
2017년 데이터 분석 경진대회 기법 재현
by DANBI
이번 포스트는 2017년에 실시된 데이터 분석 경진대회 우승팀의 모델 재현에 대한 포스트입니다. 이전 대회의 데이터를 활용하여 게임 로그 가공법 및 모델 생성 방법을 소개해드리겠습니다.
데이터 가공
-
경진대회 당시 참가자들에게 제공된 데이터를 해당 기간 동안 행한 행동의 총계인 기간 총계 데이터와 일별 행동의 총계인 일일 데이터, 두 가지로 집계합니다.
-
집계한 일일 데이터의 요약치를 추가 집계하여 최종 데이터를 생성합니다.
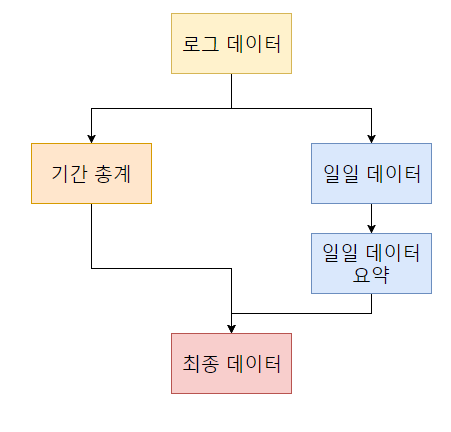
각 데이터의 구성 방법 및 특징에 대해 자세하게 설명해 드리겠습니다.
기간 총계 데이터
- 기간 총계 데이터는 해당 기간 동안 계정의 활동 로그를 집계한 데이터 입니다.
| 구분 | 정의 | 비고 |
|---|---|---|
| accountLevel | 전체 캐릭터의 최종 레벨 및 홍문 레벨 총합 | 기간 내 캐릭터 별 최대 레벨의 합으로 계산 |
| nActors | 전체 캐릭터의 수 | 기간 내 로그가 존재하는 캐릭터의 수 |
| nActorsLow | 50레벨 미만 캐릭터의 수 | 홍문레벨 무 |
| nActorsHigh | 50레벨 이상 캐릭터의 수 | 홍문레벨 유 |
| nZones | 전체 케릭터가 플레이한 지역의 수 | |
| nGuilds | 전체 케릭터의 소속 길드 수 |
일일 데이터
- 일일 데이터는 하루 동안 계정의 활동 로그를 집계한 데이터입니다. 일, 구분, 데이터 형식으로 구성 되어 있습니다. X는 변수를 의미합니다.
| 구분 | 정의 | 비고 | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LogID | 일별 각 로그아이디 개수 | 전체 로그아이디의 개수 | ||||||||||||||||||||
| playtime | 일별 플레이 시간 | |||||||||||||||||||||
| sessions | 일별 세션 개수. | 로그아웃을 기준으로 세션 정의 | ||||||||||||||||||||
| levelUpNormal | 일별 모든 캐릭터의 레벨업 횟수 | |||||||||||||||||||||
| levelUpMastery | 일별 모든 캐릭터의 홍문 레벨업 횟수 | |||||||||||||||||||||
| nActorsDaily | 일별 플레이한 캐릭터 수 | |||||||||||||||||||||
| playtime_dayOfWeek_[X] | 해당일자의 요일 및 플레이시간 | 플레이시간은 주중/주말로 구분하여 가공 할 때 사용 | ||||||||||||||||||||
| playtime_actorJob_[X] | 해당일자의 캐릭터 직업별 플레이시간 |
|
||||||||||||||||||||
| playtime_actorRace_[X] | 해당일자 캐릭터 종족 별 플레이시간 |
|
||||||||||||||||||||
| playtime_actorGender_[X] | 해당일자 캐릭터 성별 플레이시간 | 1: Male, 2: Female | ||||||||||||||||||||
| playtime_timeOfDay_[X] | 하루를 6개의 시간 블럭으로 나눔 |
|
||||||||||||||||||||
| actionVariety | 해당일자에 행해진 행동 개수 (로그 아이디 개수) | |||||||||||||||||||||
| [X]_group | 그룹별 카운트 로그 아이디를 8개의 그룹으로 나누어 집계 |
|
||||||||||||||||||||
| equipScore | 해당일 장착 장비 지수 | 2103 (SaveEquipInfo)의 Old_Value3_Num | ||||||||||||||||||||
| totalMoneyGotLog | log(총 획득 게임 머니) |
일일 데이터에 대한 통계 데이터
- 위에서 일별로 집계된 일일 데이터에 대한 통계 데이터를 집계합니다. X는 일별 데이터 각각의 특징을 의미합니다. 기간 총계 데이터와 해당 데이터를 합쳐 학습에 활용합니다.
| 구분 | 정의 | 비고 |
|---|---|---|
| [X]_total | 일별 데이터의 총합 | |
| [X]_mean | 일별 데이터의 평균 | |
| [X]_std | 일별 데이터의 표준 편차 | |
| [X]_variation | 일별 데이터의 변동 계수 ( %) | 표준편차 / 평균 * 100 |
| [X]_loyalty | 일별 데이터의 충성도 | 해당 Feature의 개수 / 총 플레이기간 |
| [X]_amountLast | 마지막 활동량 | 마지막 데이터의 해당 값 |
| [X]_lastDays_7 | 마지막 7일동안 플레이한 로그의 개수 | 해당 Feature의 개수 / 7 |
| [X]_lastDays_14 | 마지막 14일동안 플레이한 로그의 개수 | 해당 Feature의 개수 / 14 |
| royalty_last1week | 마지막 1주간 충성도 | 접속 횟수 / 7 |
| royalty_last2week | 마지막 2주간 충성도 | 접속 횟수 / 14 |
| daySinceLastActiontoLastDay | 로그별 마지막 기록시간과 마지막 접속 시간의 시간차 |
위에서 생성된 변수 중, 특징을 잘 설명할 수 있도록 변수를 선택하고 일반화를 통해 학습이 용이하도록 변경합니다.
변수 선택
-
학습 데이터 (Train Set)와 평가 (Test Set) 데이터간, 유사하지 않은 분포 보이는 변수를 제외합니다. 학습 데이터와 평가 데이터간 존재 가능한 외부적 요건의 (e.g. 2016년 12월 14일 F2P 전환 등) 영향력을 최소화하여, 성능 저하를 막기 위해 진행하였습니다.
-
선택 방법 및 결과는 다음과 같습니다.
-
1) 학습 데이터를 이용하여 각 변수의 평균 (mean)과 표준 편차 (standard deviation)을 계산합니다.
-
2) 평균 ± 2(표준편차)로 각 변수의 *유효 범위를 구합니다. 유효 범위는 단순히 지칭을 위한 명칭이며, 실질적으로 유.무효의 의미를 나타내진 않습니다 (e.g. 평균 = 5, 표준편차 = 2일 경우 계산되는 범위는 5±4 = [1, 9] )
-
3) 평가 데이터 70% 이상이 유효범위에 속하는 변수를 사용합니다.
-
-
변수 선택 결과, 2145번 및 4001번 로그 관련 변수들이 제외되었습니다.
-
2145번 로그(랜덤스탯 보패 관련 로그)의 경우, 학습 데이터 기간 이후 추가된 기능으로 변수에서 제외하였습니다.
-
4001번 로그(스킬 획득 로그)의 경우, 학습 데이터 기간 대비, 평가데이터 기간 중 월등하게 많은 수의 로그가 기록되었습니다. (mean 기준 약 3배, median 기준 약 3.5배) 이는 평가데이터 대상의 유저들이 학습데이터의 유저들보다 많은 수의 스킬을 획득했음을 의미합니다.
-
-
데이터 Normalization
-
RNN의 경우, 데이터의 Normalization/ Standardization 이 진행되지 않을 경우, 학습이 진행되지 않습니다. 학습이 잘 진행 되기 위해 모든 변수에 대해 Normalize를 진행합니다.
-
Binary classification은 결과값의 범위가 [ 0 , 1 ] 이기 때문에, 모든 변수들이 [ 0 , 1 ] 범위에 속하도록 Min-Max Normalization을 진행하였습니다.
-
모든 유저의 모든 일자에 대해 변수별로 합친 뒤, 변환을 진행하였습니다. 위와 같이 진행한 이유는 각 유저에 대한 데이터의 Weight 및 각 일자에 대한 Weight가 같은 단위에 속하도록 하기 위함 입니다.
-
모델 생성
모델은 Python Keras를 활용하여 생성하였습니다. 모델의 전체 구성도는 다음과 같습니다. Main Input 레이어에는 기간 총계 데이터 및 일일 통계 데이터를, Sub Input에는 일일 데이터를 학습에 활용합니다. 각 레이어를 왜 활용하였는지, 어떤 방식으로 동작하는지 설명드리겠습니다.
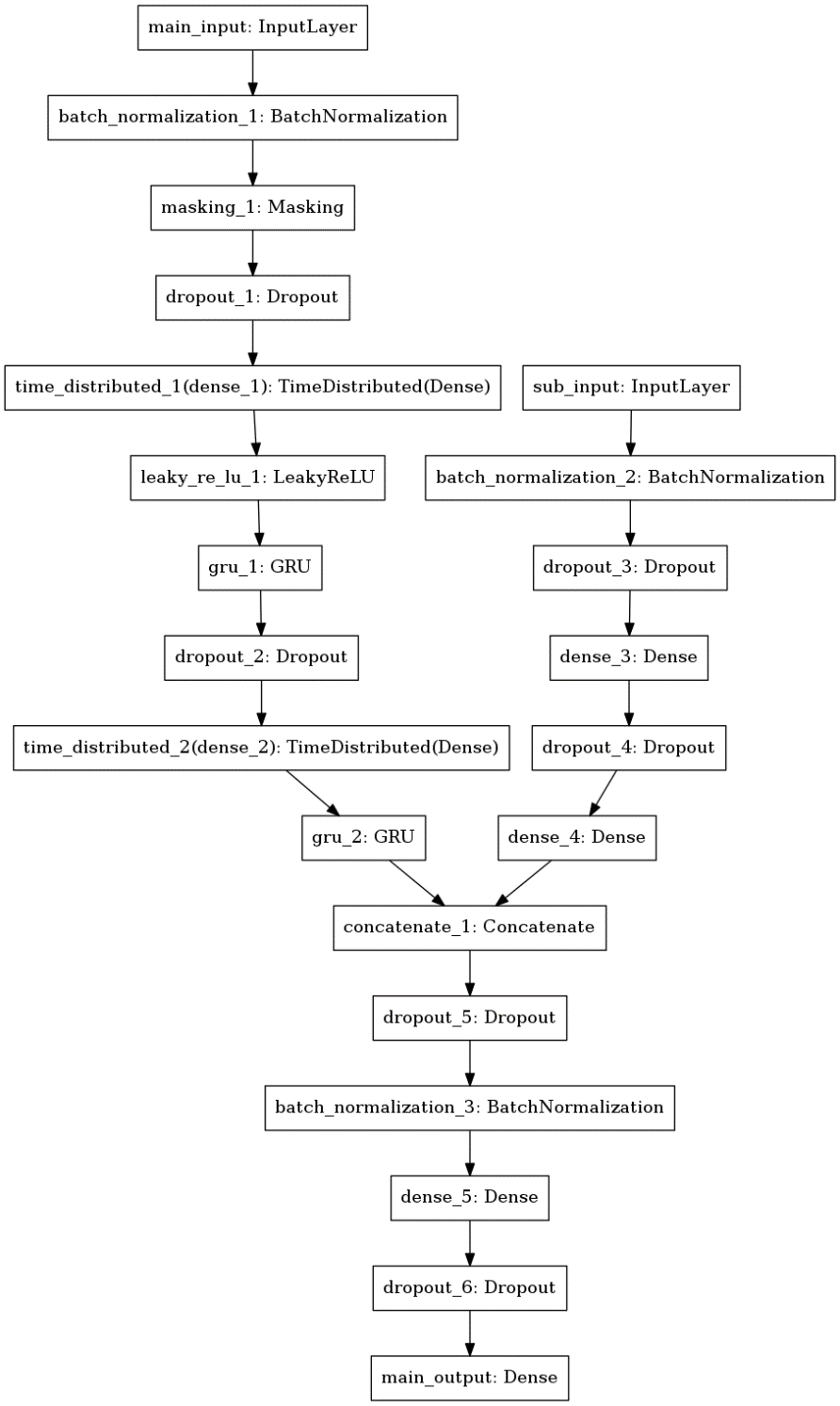
-
Batch Normalization
- Batch Normalization은 기본적으로 Gradient Vanishing / Gradient Exploding 이 일어나지 않도록 하는 아이디어 중의 하나입니다. 대부분 뉴럴넷은 보통 전체 데이터를 쪼개어(Batch) 한 부분씩 학습을 진행하는데 각각 쪼개진 부분에 대해 평균과 표준편차를 구해 Normalization을 진행하여 새로운 값을 만들어 학습한다고 이해하시면 됩니다.
-
빈값 채워주기
-
데이터의 차원을 동일하게 만들도록, 존재하지 않는 항목을 채워줘야 합니다. 예를 들어, 어떤 유저는 13일동안의 접속 기록이 존재하고, 다른 유저는 4일의 접속기록만 존재한다면, 각 유저에 대한 데이터 차원이 다를 수 밖에 없습니다. 미리 값을 채워준 후 Normalize 진행하면, 채워진 값 (0)이 normalize 연산에 포함되는 오류가 존재하게 됩니다. 따라서 관측치들로 normalize 진행후, 채워주기를 진행 하는 것이 바람직합니다.
-
하지만 빈 값을0으로 채울 경우, 기계는 이게 정말 0인지, 아니면 값이 없어 0을 넣은 것 인지 정확히 알 수 없습니다. 따라서 값이 없는 경우 0이 아닌 특별한 숫자를 삽입하거나, 0을 넣고 Normalization을 [ 1 , 2 ]로 진행하는 등의 방법을 사용하여 실제 0과 없는 값을 구분해야 합니다. 이 작업을 마스킹 이라고 합니다
-
위 모델에서는 빈 값을 직접 채우지 않고Tensorflow에서 제공하는 마스킹 함수를 사용하였습니다. 마스킹이 된 데이터는 자동으로 학습에 적용되지 않습니다.
-
-
Dropout
- Dropout은 모든 뉴런을 계산에 참여시키지 않고 레이어에 포함된
뉴런 중 일부만 계산에 참여시키는 방법입니다. 이전 레이어에서
다름 레이어로 데이터를 전달할 때 일부 뉴런을 0으로 만드는
방법입니다 위 방법을 사용하여
Overfit을 줄일 수 있습니다.
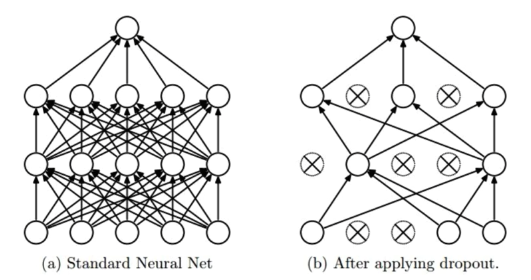
- Dropout은 모든 뉴런을 계산에 참여시키지 않고 레이어에 포함된
뉴런 중 일부만 계산에 참여시키는 방법입니다. 이전 레이어에서
다름 레이어로 데이터를 전달할 때 일부 뉴런을 0으로 만드는
방법입니다 위 방법을 사용하여
-
TimeDistributed Dense
- TimeDistributed는 3차원으로 구성된 배열 (데이터 수, TimeSteps,특징) 중 각 TimeSteps 마다 독립적인 레이어를 사용하는 방식입니다. 예를 들어 (100,20,40) 형태의 Input Layer가 있으면, 100은 샘플 수, 20은 TimeSteps, 40은 특징수로 구성되어 있을 겁니다. TimeDistributed(Dense(20))을 진행한다면, output layer는 (100,20,20)으로 샘플과 시간의 개수는 그대로 유지하고 특징의 개수에만 독립적으로 적용하게끔 하는 변수입니다.
** 모델 튜닝 **
-
하이퍼 파라미터 튜닝
- 각각의 Dropout, Layer수 , Batch size, Epoch는 모두 Grid Search 방식으로 진행하였습니다.
최종 모델
-
평균 F-Score 0.59로 경진대회 우승팀과 0.02점 차이가 났습니다
-
최종 모델 코드
# RNN Model
main_input = Input(shape=np.shape(Z_train[1]), dtype='float32',name='main_input')
main_inp = BatchNormalization()(main_input)
x = Masking(mask_value=0.)(main_inp)
x = Dropout(float(drop_out[0]))(x)
x = TimeDistributed(Dense(int(RNN_dense[0]),
kernel_initializer='normal'))(x)
x = LeakyReLU()(x)
x = GRU(units=int(gru[0]), return_sequences=True)(x)
x = Dropout(float(drop_out[1]))(x)
x = TimeDistributed(Dense(int(RNN_dense[1]),
kernel_initializer='glorot_uniform', activation='sigmoid'))(x)
x = GRU(int(gru[1]), return_sequences=False)(x)
# DNN Model
sub_input = Input(shape=np.shape(X_train[1]), dtype='float32',
name='sub_input')
sub_inp = BatchNormalization()(sub_input)
y = Dropout(float(drop_out[2]))(sub_inp)
y = Dense(int(DNN_dense[0]), kernel_initializer='he_uniform',
activation='relu')(y)
y = Dropout(float(drop_out[3]))(y)
y = Dense(int(DNN_dense[1]), kernel_initializer='he_uniform',
kernel_regularizer=l2(l2_lambda), activation='relu')(y)
# Merge Model ( Concat )
x = keras.layers.concatenate([x, y])# Shape (None,2048+64)
x = Dropout(float(drop_out[4]))(x)
x = BatchNormalization()(x)
x = Dense(int(DNN_dense[2]), kernel_initializer='he_uniform',
activation='relu')(x)# Shape (None,256)
x = Dropout(float(drop_out[5]))(x)
main_output = Dense(1, activation='sigmoid',
kernel_initializer='glorot_uniform',
kernel_regularizer=l2(l2_lambda),name='main_output')(x)# Shape
(None,1)
model = Model(inputs=[main_input, sub_input], outputs=main_output)
# Set Optimizer
opt = keras.optimizers.Adam(lr=0.0005)
# Set Complie Method
model.compile(optimizer=opt,
loss={'main_output': 'binary_crossentropy'},
metrics=['binary_accuracy',f1,recall,precision])
# Train Model with Validation Data
history = model.fit({'main_input': Z_train, 'sub_input': X_train},
{'main_output': y_train},
epochs=int(epochs), batch_size=int(batch_size),
validation_split=0.1)
-
성능 측정
- Drop Out Rate의 무작위성으로 인한 성능 오측을 막기위해, 학습 및 평가를 10회 반복하여 성능 측정하였습니다.
| 각 수치별 병균 및 표준편차 | ||
|---|---|---|
| Test 1 | Test 2 | |
| Precision (SD) | 0.493 (0.013) | 0.534 (0.011) |
| Recall (SD) | 0.675 (0.026) | 0.666 (0.022) |
| FScore (SD) | 0.5603 (0.004) | 0.593 (0.004) |
-
진리표
- Test1
| Test 1 (기준 = 0.5) | |||||||
|---|---|---|---|---|---|---|---|
| 우승팀 | 모델 | ||||||
| 예측치 | 예측치 | ||||||
| 이탈 | 비이탈 | 소계 | 이탈 | 비이탈 | 소계 | ||
| 관측치 | 이탈 | 624 | 276 | 900 | 644 | 256 | 900 |
| 비이탈 | 531 | 1,569 | 2,100 | 677 | 1,423 | 2,100 | |
| 소계 | 1,155 | 1,845 | 3,000 | 1,321 | 1,679 | 3,000 | |
Precision : 0.54 Accuracy : 0.731 F-Score : 0.61 |
Precision : 0.49 F-Score : 0.58 |
||||||
- Test2
| Test 2 (기준 = 0.5) | |||||||
|---|---|---|---|---|---|---|---|
| 우승팀 | 모델 | ||||||
| 예측치 | 예측치 | ||||||
| 이탈 | 비이탈 | 소계 | 이탈 | 비이탈 | 소계 | ||
| 관측치 | 이탈 | 683 | 217 | 900 | 699 | 201 | 900 |
| 비이탈 | 615 | 1,485 | 2,100 | 670 | 1,430 | 2,100 | |
| 소계 | 1,298 | 1,702 | 3,000 | 1,369 | 1,631 | 3,000 | |
Precision : 0.53 Accuracy : 0.72 F-Score : 0.62 |
Precision : 0.51 F-Score : 0.61 |
||||||
-
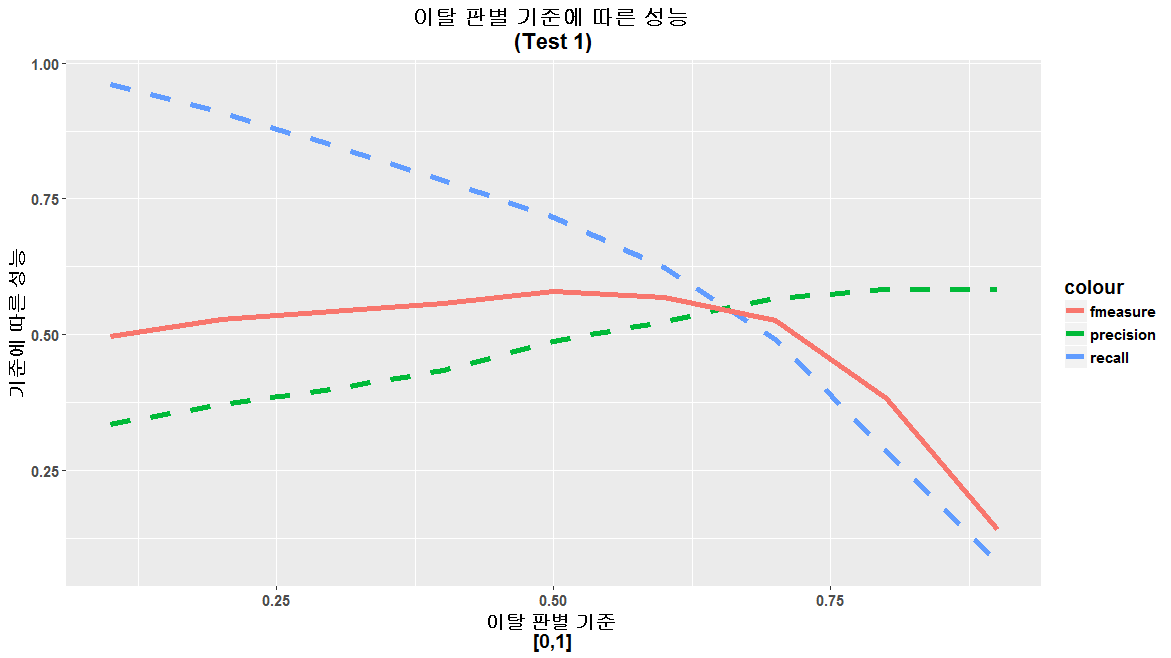
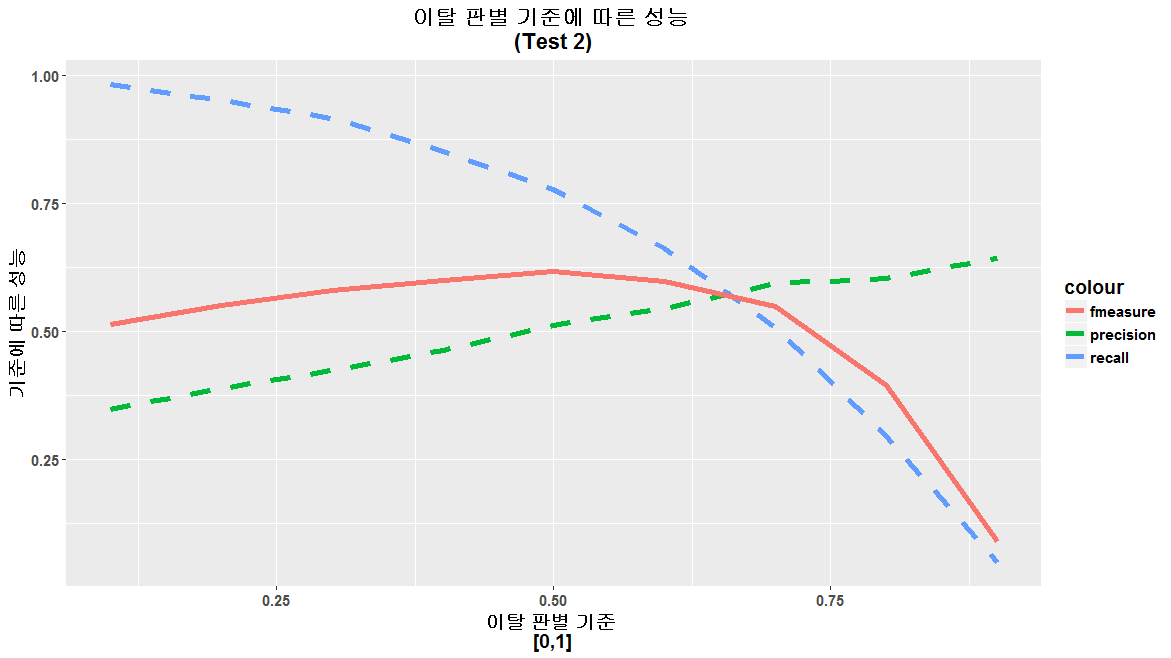
이탈 판별 기준 (Threshold)에 따른 성능 측정
-
이탈 판별 기준이란, [0,1] 범위로 도출되는 Sigmoid 함수의 결과물을 이탈/비이탈의 두가지로 분류하는 기준을 말합니다. 예를들어 기준이 0.5인 경우, 결과값이 0.7인 경우 이탈로 판단하고, 0,4인 경우 비이탈로 판단합니다.Test1, Test2에 대한 Threshold 변경에 따른 성능 측정 결과, 0.5가 최고의 성능을 보였습니다.
-
Test1
-
Test2
-
결과물
모델 및 결과 파일입니다.