
2018 빅콘테스트 후기
by DANBI
이 글은 2019년 1월에 발간된 마이크로소프트웨어 395호에 기고했던 글입니다.
시작하며
데이터 분석 및 기계 학습에 대한 관심과 중요도가 커짐에 따라 데이터 분석 경진 대회의 인기도 점점 커지고 있다. 특히, 사람들에게 가장 널리 알려진 것은 캐글이라고 하는, 2010년에 설립된 데이터 분석 경진 대회 전문 플랫폼이다 (https://www.kaggle.com/). 캐글에서 사람들은 레이블과 함께 주어진 학습 데이터를 분석하여 예측 모델을 만든 후 레이블 없이 주어진 평가 데이터들에 대해서 누가 더 정확히 정답을 맞추는지 겨루게 된다. 참가자들이 좋은 성적을 얻을 경우 직접적으로는 상금이나 명예를 얻기도 하지만, 무엇보다 캐글이 데이터 분석가들에게 인기를 얻게 된 이유는 다른 사람들이 분석하거나 만든 예측 모델링 기법이나 코드를 서로 공유할 수 있기고 쉽게 접하기 힘든 데이터들을 접할 수 있기 때문이라 생각한다. 경쟁과 공유가 적절히 시너지를 발하면서 캐글은 데이터 분석 분야의 발전에 큰 공헌을 하고 있다. 캐글이 인기를 끌면서 우리 나라에서도 이를 벤치마킹한 유사한 서비스가 등장하기도 했고, 여러 회사나 정부 기관에서 이와 비슷한 형식의 경진 대회를 매해 개최하고 있다.
엔씨소프트에서는 2017년에 우연한 기회를 통해 IEEE Conference on Computational Intelligence and Games 라는 국제 학회를 통해 최초로 게임 데이터를 활용한 데이터 마이닝 경진대회를 개최했었다 (대회 홈페이지). 그러나 경험 미숙과 홍보 부족으로 인해 참가 규모가 크지 않았고, 우승팀을 제외한 다른 참가팀의 결과물이 기대에 미치지 못한 아쉬움이 있었다.
올해에는 지난 해 대회를 타산지석 삼아, 문제 난이도를 조금 낮추고 홍보에 많은 노력을 기울여 최대한 많은 참여를 유도하는 것을 목표로 했다. 이를 위해 캐글을 이용할 계획을 갖고 연락을 취했다. 그러나 캐글 측 담당자와 상담을 해보니 캐글 플랫폼을 이용하는데 비용이 매우 크다는 사실을 알 수 있었다. 일반 회사에서 캐글을 통해 경진 대회를 주최할 경우 상금을 제외하더라도 컨설팅 및 호스팅 명목으로 최소 6만 달러 이상의 비용이 필요하다. 더불어 캐글 측에서는 우리가 하려는 정도의 대회는 총 상금 규모를 최소한 2만 달러 이상 책정해야 한다는 의견도 주었다. 결국 우리가 책정한 예산보다 클 뿐만 아니라, 상금보다 최소 3배 가까운 비용을 대회 운영을 위해 소비하는 것은 적절하지 않다고 판단했고, 차라리 국내에 진행 중인 행사에 참여하는 쪽으로 방향을 바꾸었다. 결국 여러 조사 과정을 통해 한국정보화진흥원과 빅데이터포럼에서 공동으로 주최하는 ‘빅콘테스트’ 라는 행사를 알게 되어 주관사로 참여하게 되었다 (빅콘테스트 홈페이지).
엔씨소프트에서 데이터 분석 경진 대회를 하게 된 최초 취지를 한 단어로 표현하자면 ‘홍보’ 였다.
먼저 게임 데이터가 갖고 있는 잠재력과 매력을 널리 알리고 싶었다. 게임 분야는 다른 IT 영역에 비해 다소 폐쇄적인 성격이 강하다. 게임 업계의 규모나 종사하는 사람들의 규모를 고려해 보면 게임 업계의 다양한 기술이나 관련 이슈에 대해 공유하는 자리는 매우 빈약한 수준이다 (비록 NDC 라고 하는 큰 행사가 있지만, 반대로 말하면 이 행사가 거의 유일하다).
특히, 데이터 분석과 관련해서는 거의 공개되는 내용이 없다. 하지만 게임 데이터는 데이터 분석가의 입장에서 볼 때 세상에서 가장 매력적인 데이터라 생각한다. 유저들이 가상 세계에서 어떻게 성장하는지, 다른 사람들과 다양한 사회 관계를 통해 경쟁하거나 협력하는지 등의 다양한 활동이 초 단위로 기록된다수행하는 다양한 활동이 초 단위로 기록된다. 여기에는 사람들이 어떻게 성장하는지, 다른 사람들과 다양한 사회 관계를 통해 경쟁하거나 협력하는지 등이 모두 나와 있다. 더군다나 MMORPG 에서는 현실 세계와 유사한 경제 시스템도 구축되어 있어 다양한 사람들이 어떻게 재화를 획득하고 소비하며 거래하는지 관찰할 수 있다. 심지어 채팅 데이터를 통해 자연어 분석도 가능하다. 말 그대로 우리가 접할 수 있는 거의 모든 종류의 데이터가 있는 것이다. 다양성 측면에서 보자면 구글도 갖지 못한 데이터이다.
따라서 이러한 게임 데이터의 매력을 널리 알린다면 외부에 있는 우수한 데이터 분석가들의 관심을 끌 수 있으리라 생각했다. 오래 전부터 데이터 분석팀을 키우기 위해 인재 채용에 많은 노력을 기울였지만 매번 지원자가 거의 없어 고생을 많이 했다. 우수한 인력들은 대부분 웹 포털 업체 등에 관심을 보이며갖지 게임 회사에는 별로 매력을 느끼지 않는 것 같았다. 하지만 이렇게 게임 데이터가 갖고 있는 매력이 알려진다면, 그리고 엔씨소프트가 이런 데이터를 가장 잘 관리하고 있다는 인식이 퍼진다면, 많은 데이터 분석가들이 우리 회사에 관심을 가질 것이라 생각했다.
더 나아가 학계에 있는 연구자들이 게임 데이터를 이용해서 다양한 연구를 하면 좋겠다는 생각도 들었다. 현재도 게임을 이용한 흥미로운 연구들이 없는 것은 아니다. 월드 오브 워크래프트의 유명한 사건인 ‘오염된 피 사건’은 전염병 전파 경로에 대한 연구에 활용되기도 했고(참고링크: ‘오염된 피’ 사건), 아키에이지의 베타 서비스 데이터를 이용해 종말이 다가오면 인간이 어떻게 행동할 것인지에 대해 연구한 논문도 있다 (논문링크). 그러나 앞서 언급했듯이 게임 업계의 폐쇄성 때문에 절대적인 연구 규모는 매우 미약한 수준이다. 그래서 이런 경진 대회를 통해 공개된 데이터를 활용한 연구가 많이 이뤄졌으면 하는 바램도 있었다.
그런데 막상 대회를 끝내고 결과를 받아 보니 기대하지 않았던 수확도 있었다. 참가팀들의 결과물이 예상을 뛰어 넘는 수준이었다. 이들이 사용한 데이터 분석 기법 및 노하우를 잘 정리하면 이를 통해 회사의 분석 역량을 발전시키는 데에도 도움이 되겠다는 생각이 든다. 결국 홍보만 잘해도 성공하리라 생각했던 행사였으나, 참가자들의 우수한 분석 역량을 확인하고 우리의 분석 기술을 발전시키는 좋은 계기가 되었다고 생각한다.
빅콘테스트는 어떤 행사이고 어떻게 진행되었는가
빅콘테스트는 2013년에 처음 시작하여 올해로 6회째를 맞이한 행사이다. 한국정보화진흥원과 빅데이터포럼이 공동으로 주최하며, 전반적인 대회 운영은 한국정보통신진흥협회에서 담당하고 있다. 주관사는 매년 조금씩 바뀌는 것으로 알고 있는데 올해에는 신한은행, SK텔레콘, 신한카드와 엔씨소프트가 참여하여 총 4개의 트랙으로 대회가 진행되었다. 각 트랙별 문제는 아래와 같다.
- Innovation 분야
- 통신: 통신서비스 데이터 기반의 카드 소비 데이터, 공공 데이터 등 다양한 데이터를 활용한 ‘지역생활편의지수’ 개발
- 금융: 금융 데이터를 활용한 ‘나의 금융생활정보 지수’ 개발
- Analysis 분야
- 퓨처스리그: 개봉(예정) 영화에 대한 관객 수 예측
- 챔피언리그: 게임 내 활동 데이터를 활용한 ‘게임 유저 이탈 예측 모형’ 개발
대회는 7월 10일부터 참가팀 접수를 받기 시작하여 설명회와 함께 데이터가 공개되었다. 이후 참가팀들은 9월 14일까지 주어진 데이터 (혹은 외부에서 입수 가능한 데이터) 를 활용해 각 트랙에서 요구한 문제를 풀어 그 결과를 제시하는 형태로 진행했다. 엔씨소프트는 Analysis 분야의 챔피언리그 트랙의 문제를 담당하였는데, 대회를 위한 데이터뿐만 아니라 대회 진행 기간 동안 홈페이지를 통해 본인들이 만든 예측 모델의 성능을 테스트해보고 그 결과를 다른 참가팀들과 비교해 볼 수 있도록 자율 평가 시스템을 제공하였다 (캐글의 Leader board와 유사한 형태이다).
Analysis 분야 챔피언 리그에는 총 531개 팀이 참여했으며 이 중 93개 팀이 최종 결과물을 제출하였다. 최종 결과물은 최종 예측 결과뿐만 아니라 예측에 사용한 모델링 코드와 분석 보고서를 같이 제출하는 형태였다. 그런데 자율 평가 시스템을 통해 모델의 예측 정확도는 개략적으로 확인이 되기 때문에 상위 순위에 들지 못한 다수의 참가팀들이 최종 결과물 제출을 포기한 것으로 추정된다.
제출한 결과물과 최종 예측 결과를 토대로 1차 심사를 진행했으며 그 결과 12개팀을 선별해 2차 심사를 진행했다.
2차 심사는 엔씨소프트 R&D 센터에서 진행되었는데 참가팀들이 직접 자신들의 예측 모델과 이탈 분석 결과를 15분동안 발표하고 10분동안 QA를 하는 방식이었다. 이후 1,2차 심사 결과를 바탕으로 최종 수상자들이 결정되었으며 11월 21일에 진행한 ‘2018 데이터 진흥 주간’ 에 있었던 시상식을 통해 최종 순위가 발표되었다.
Analysis 분야 챔피언 리그 문제에 대한 소개
엔씨소프트에서 제시한 문제는 ‘게임 유저 이탈 예측 모형 개발’ 이었다. ‘이탈 예측 (churn analysis)’ 은 ‘고객 관계 관리 (Customer Relationship Management, CRM)’ 분야에서 오래 전부터 연구 되어 왔던 주제이다. 과거에는 주로 금융이나 통신 분야 등에서 주로 활용되었으나 최근에는 다양한 분야로 확산되었으며, 온라인 게임 분야에서도 이에 대한 연구가 최근에 많이 이뤄지고 있다.
그러나 온라인 게임에서 고객의 이탈의 원인을 찾는 문제는 보기보다 쉽지 않다. 게임 데이터는 고객이 가상 세계에서 활동하는 정보만을 기록하기 때문에 현실 세계에서의 어떤 불가피한 원인 ? 이를 테면, 군대를 간다거나 수험생이 시험 준비를 하는 등 ? 으로 인한 이탈은 파악이 불가능하다. 따라서 이런 제한된 정보 내에서 최대한 이탈 징후를 조기에 찾기 위해선 폭넓은 데이터의 활용과 더불어 정교한 모델링이 필요하다. 결국 이탈 예측 문제는 문제에 대한 정의는 명확하고 이해가 쉬운 반면, 분석가의 역량과 노력 수준에 따라 그 편차가 크게 나타날 수 있는 문제이다 (즉, 좋은 문제란 얘기다).
우리는 엔씨소프트의 대표적인 MMORPG 중 하나인 ‘블레이드 앤 소울 (Blade and Soul, B&S)’ 의 게임 데이터를 문제에 사용하였다. 아래 그림과 같이 고객들이 과거 8주 동안 수행한 여러 가지 활동 정보를 제공한 후, 고객들이 향후 12주 사이에 언제 이탈할지를 예측하는 방식이다. 대개 이탈 예측 문제는 단순히 특정 시점에 이탈할지 여부를 판별하는 이분 분류 모델링이 일반적이다. 그러나 우리는 이탈 시기에 따른 유저의 패턴을 좀 더 정교하게 예측할 수 있도록 아래와 같이 네 가지 종류의 라벨을 제시했다.
- Week: 1주 이내 이탈
- 1Month: 2~4주 이내 이탈
- 2Month: 4~7주 이내 이탈
- Retained: 8주 이상 잔존
 <그림 1> 제공 데이터와 라벨링 기간
<그림 1> 제공 데이터와 라벨링 기간
참가팀이 분석 역량을 최대한 활용할 수 있도록 다양한 데이터를 제공하였는데 제공된 데이터의 종류는 다음과 같다.
1) 게임 활동 정보
가상 세계에서 게임 캐릭터들이 수행한 각종 활동들을 일주일 단위로 집계한 데이터이다. 앞서 언급했듯이 총 집계 기간은 8주이다. 매주 꾸준히 접속하는 고객도 있고 그렇지 않은 고객도 있기 때문에 각 고객별로 최대 8개의 데이터가 제공된다. 제공된 활동 정보의 스키마는 다음 표와 같다.
<표 1> 게임 활동 정보 스키마
| 필드명 | 설명 | 필드명 | 설명 |
|---|---|---|---|
| wk | 활동주(1~8) | cnt_enter_raid | 레이드참여횟수 |
| acc_id | 계정 아이디 | cnt_enter_raid_light | 라이트레이드참여횟수 |
| cnt_dt | 해당 주에 한번 이상 접속한 일수 | cnt_enter_bam | 밤의 바람평야 입장 횟수 |
| play_time | 플레이 시간(단위: 초) | cnt_clear_indun_solo | 솔로 인던 완료 횟수 |
| npc_exp | NPC 사냥 일반 경험치 | cnt_clear_indun_light | 라이트 인던 완료 횟수 |
| npc_hongmun | NPC 사냥 홍문 경험치 | cnt_clear_indun_skilled | 숙련 인던 완료 횟수 |
| quest_exp | 퀘스트 일반 경험치 | cnt_clear_raid | 레이드 완료 횟수 |
| item_hongmun | 아이템 홍문 경험치 | cnt_clear_raid_light | 라이트 레이드 완료 횟수 |
| game_combat_time | 전투 시간 (단위: 초) | cnt_clear_bam | 밤의 바람 평가 완료 횟수 |
| get_money | 재화 획득량 | normal_chat | 일반 채팅 횟수 |
| duel_cnt | 결투 참여 횟수 | whisper_chat | 귓속말 채팅 횟수 |
| duel_win | 결투 승리 횟수 | district_chat | 지역 채팅 횟수 |
| partybattle_cnt | 전장 참여 횟수 | party_chat | 파티 채팅 횟수 |
| party_battle_win | 전장 승리 횟수 | guild_chat | 문파 채팅 횟수 |
| cnt_enter_indun_solo | 솔로 인던 입장 횟수 | factions_chat | 세력 채팅 횟수 |
| cnt_enter_indun_light | 라이트 인던 입장 횟수 | cnt_use_buffitem | 버프 아이템 사용 횟수 |
| cnt_enter_indun_skilled | 숙련 인던 입장 횟수 | making_cnt | 제작 횟수 |
2) 소셜 관련 정보
B&S에서 게임 캐릭터들은 다른 캐릭터들과 다양한 상호 작용을 통해 경쟁 및 협업을 수행한다. 우리는 이런 다양한 사회 활동 중에서 핵심 컨텐츠라고 할 수 있는 파티, 문파, 거래 데이터를 제공했다.
파티 활동 정보의 경우 각 파티가 가장 처음 결성된 시각과 해체된 시각, 그리고 그 파티에 참여한 게임 계정 목록으로 구성되며, 문파 정보는 마지막 8주차에 있었는존재했던 문파들의 문파원 정보로 구성된다. 마지막으로 거래 정보는 각 캐릭터들이 언제 누구와 어떤 아이템을 얼마만큼 주고 받았는지에 대한 거래 이력 데이터이다.
3) 결제 이력 데이터
기존에 알려진 여러 이탈 관련 연구에 의하면 고객의 이탈과 결제 이력 간에는 높은 상관성이 있기 때문에 고객들이 게임을 위해 결제한 이력 정보도 제공됐다.
참고로 제공된 모든 데이터는 기밀 및 개인 정보 노출로 인해 발생할 수 있는 문제를 피하기 위해 표준화 및 익명 처리가 되었다. 학습 데이터와 평가 데이터의 규모는 각각 10,000명과 40,000명이며 라벨 별 비율은 모두 동일하게 맞췄다.
예측 성능 평가에는 F1 score 를 사용했다. F1 score는 precision과 recall의 조화 평균인데, 우리가 제공한 라벨은 총 4 종류이므로 아래와 같이 계산된다.
\[F1 = \frac{8}{(\frac{1}{Week_PR}+\frac{1}{Week_RC}+\frac{1}{Month_PR}+\frac{1}{Month_RC}+\frac{1}{2Month_PR}+\frac{1}{2Month_RC}+\frac{1}{Retained_PR}+\frac{1}{Retained_RC})}\]위 식에서 각 라벨의 첨자로 표시된 ‘PR’과 ‘RC’는 각각 Precision과 Recall을 의미한다.
마지막으로 대회 진행 중에 참가팀들이 평가 데이터에 대한 예측 성능을 미리 가늠해 볼 수 있도록 대회 홈페이지에 자율 평가 기능을 제공했다 (단, 어뷰징을 피하기 위해 자율 평가 횟수는 1일 5회로 제한되며, 평가 데이터의 20% 만 사용했다). 캐글에도 Leader board 라고 이와 동일한 기능이 있는데, 이런 방식은 참가자들이 장기간의 대회 기간 동안 지속적으로 예측 모델을 개선하게 만드는 중요한 동기 부여 요인이 된다고 생각한다. 실제로 대회를 운영한 한국정보통신진흥협회 담당자분의 말에 의하면 이번 대회가 가장 많은 참가팀이 참여했으며 결과도 가장 좋았다고 들었는데, 게임이라는 분야에 대한 관심이 큰 이유도 있었겠지만 이 자율 평가 기능도 한 몫을 했다고 생각한다.
다만, 심사 위원으로 참여한 한 교수님의 말씀에 의하면, 이렇게 다른 참가팀의 결과를 볼 수 있다 보니 성능이 상대적으로 너무 떨어져서 수상 가능성이 낮다고 판단한 팀들이 중간에 포기하는 경우도 있었다고 한다. 향후 유사한 대회를 진행한다면 이런 장/단점을 잘 고려하여 개선점을 찾을 필요가 있겠다.
 <그림 2> 자율 평가 순위표 - 치열한 순위 경쟁의 현장
<그림 2> 자율 평가 순위표 - 치열한 순위 경쟁의 현장
최종 제출물
참가팀들은 최종 결과물을 제출할 때 평가 데이터에 대한 예측 결과뿐만 아니라 분석에 사용한 코드 및 분석 기법을 설명한 PT 문서도 같이 제출해야 했다. 그래서 단순히 정답을 잘 맞췄는지 보기 보다는 얼마나 체계적이고 논리적인 절차를 통해 분석했는지, 접근한 방법이 다른 사람들도 활용할 수 있는 충분한 재현성과 일반성을 갖고 있는지, 다른 팀에 비해 얼마나 독창적이거나 참신한 방법을 사용했는지 등을 평가하고자 했다.
예측 정확도
앞서 소개에서 언급했듯이 게임 활동 정보만을 이용해 고객의 이탈을 정확하게 예측하는 것은 쉽지 않다. 그럼에도 불구하고 최종 결과를 제출한 팀들 중 상당수가 70%가 넘는 정확도를 기록했으며, 특히 대부분의 팀들이 F1 score 기준으로 0.7~0.75 사이에 몰려 있을 정도로 매우 치열한 접전을 벌였다. 처음 문제를 만들 때는 0.6 ~ 0.7 정도에서 최고 점수가 나오지 않을까 예상했었는데 예상을 뛰어넘는 놀라운 결과였다.
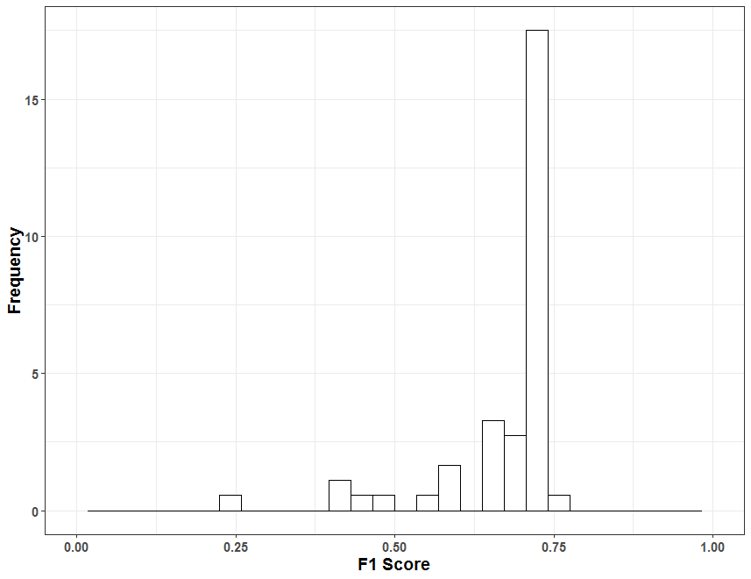 <그림 3> 참가팀들의 최종 F1 Score 분포
<그림 3> 참가팀들의 최종 F1 Score 분포
구현 코드 및 사용 도
대부분의 참가팀들이 파이썬이나 R을 사용하여 최근의 추세를 잘 반영하고 있었다. 몇몇 팀은 SPSS나 Spotfire 와 같은 도구를 보조적으로 사용하기도 했다. 엑셀만을 이용해 데이터를 분석한 팀도 있었으나, (이 팀의 제출 문서에 나온 바에 의하면) 제공된 데이터의 양이 매우 크기 때문에 엑셀에서 모든 자료를 불러 올 수 없어서 일부 용량이 큰 자료는 분석을 포기하기도 했다.
몇몇 팀의 경우 클라우드 서비스를 잘 활용한 점이 인상적이었다. 특히, 수상팀 중 하나인 ‘블린이’ 라는 팀은 본선 발표 심사에서 굉장히 많은 모델과 하이퍼 파라미터 튜닝을 시도한 내용을 소개했는데, 심사 위원 중 한 분이 이렇게 많은 경우의 수를 다 시도하면 너무 시간이 오래 걸리지 않느냐고 질문하자, AWS에 리소스를 대량으로 투입해서 몇 시간 만에 모든 테스트를 다 끝냈다고 답변하기도 했다. 당시 대신 AWS에 돈을 너무 많이 써서 상금 못 타면 빚쟁이가 된다고 농담조로 얘기 했었는데 다행히 수상을 하게 되었으니 대회 운영자로서 다행이라고 생각한다.
구체적으로 참가팀이 사용한 프로그래밍 언어 및 도구에 대한 집계 내역은 다음과 같다 (확인이 가능한 자료만 집계하여 수치는 전체 참가팀 수에 비해 적으며 여러 도구를 사용한 경우 중복 집계하였다).
<표 2> 참가팀들의 사용 언어 및 도구별 통계
| 사용 언어 및 도구 | 팀수 | 비고 |
|---|---|---|
| R | 28 | 이 중 13팀은 파이썬 함께 이용 |
| 파이썬 | 57 | Tensorflow 및 Keras 이용자 포함 |
| 기타 도구 사용 | 4 | 엑셀, Spotfire, SPSS |
한편, 구현 결과물을 다시 재현해 보기 위해 제출한 코드들을 살펴 봤는데, 대부분 코드 정리가 잘 안되어 있어 재현이 불가능한 점이 아쉬웠다. 원천 데이터에서 최종 결과를 내기 위해 어떤 패키지가 필요하고 어떤 절차대로 실행해야 하는지에 대한 설명이 거의 없고 코드 역시 거의 정리가 안되어 있었다. 아마 대부분의 참가팀들이 학생이다 보니 코드 관리에 대한 경험이 부족했기 때문이 아닌가 생각한다.
만약 다음에 대회를 한다면, 대회 시작 시점에 참가팀들이 재현성에 신경을 쓸 수 있도록 사전 안내가 필요하겠다는 생각이 들었다.
참가팀 분석 기법 정리
참가팀들의 제출물을 받았을 때 가장 놀란 점은 바로 문서의 퀄리티였다. 비록 예선에서는 예측 성능을 기준으로 상위 33개팀 만을 대상으로 심사가 진행되었으나 심사 대상이 되지 못한 다른 팀들 역시 대부분 자신들이 수행한 분석 및 모델링 결과를 체계적으로 잘 정리했다. 그래서 이렇게 훌륭한 결과물이 그냥 묻히는 게 너무 아깝다는 생각이 들었기에 여기서는 참가팀들의 다양한 결과물에 대해 소개해 보고자 한다. 이들이 사용한 다양한 기법들은 경진 대회를 준비하는 학생들뿐만 아니라 실무에서 다양한 분석 업무를 수행하는 분석가들에게도 많은 도움이 되리라 생각한다.
각 팀마다 문서 구성 상에 약간씩의 차이는 있지만 크게 보면 1) 데이터 전처리 및 탐사 분석, 2) 예측 모델링 및 튜닝, 3) 모델 해석 및 이탈 원인 분석 과정으로 나눌 수 있다. 각 단계별로 참가팀들이 사용한 기법들을 정리하면 다음과 같다.
데이터 전처리 및 탐사 분석
전반적으로 대단히 다양한 데이터 전처리 및 탐사 기법들을 시도한 점이 인상적이었다. 원래 제공된 변수들도 많았지만 이것을 여러 가지 변형과 파생 변수 생성을 통해 확장을 시도했다. 이 과정에서 심지어 어떤 팀은 수천 개가 넘는 파생 변수를 처리하기도 했다. 보편적으로 많이 사용한 전처리 기법들은 다음과 같다.
- 주별로 나눠 집계된 활동 데이터 및 결제 이력 정보를 하나의 행으로 피봇팅
- 주별 활동 데이터에 대한 기초 통계량 (총합, 평균, 분산, 최댓값, 최솟값 등) 집계
- 주별 데이터의 추세 변화에 대한 파생 변수 생성 (예: 기울기나 이동 평균)
- 서로 관련된 두 개 변수를 이용한 비율 변수 생성 (예: 결투 참여 횟수와 승리 횟수를 이용하여 승률 변수 생성)
- 파티 데이터를 가공하여 계정 별 파티 참여 횟수나 파티 멤버 수 집계
- 길드 가입 횟수나 가입된 길드의 규모 변수 생성
그 외에 독특한 시도를 한 팀들도 있었는데 몇 가지 소개하면 다음과 같다.
요인 분석 (Factor analysis)
이탈 분석을 위해 제공된 게임 활동은 약 40여 종에 달하는 만큼 전반적인 활동 상의 특징을 한번에 살펴 보기는 쉽지 않다. 때문에 변수들을 몇 개의 잠재 요인으로 통합하여 그 특징을 살펴 보는 것은 좋은 접근 방법이라고 생각한다.
아래 자료는 ‘포화란’ 팀의 요인 분석 자료이다. 다양한 활동 정보를 총 5가지 요인으로 축약한 후 Radar plot을 이용해 Week/Month/2Month/Retained 집단 별 특징을 시각화함으로써 그 차이를 직관적으로 설명하고자 했다.
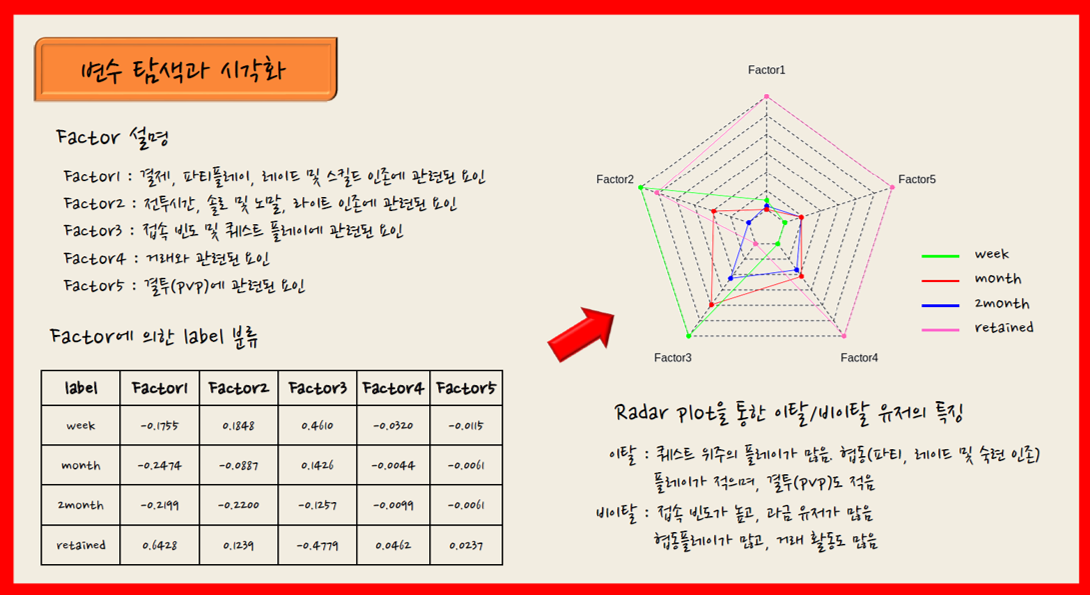 <그림 4> 요인 분석을 이용한 탐사 분석 (출처: '포화란' 팀 분석 자료)
<그림 4> 요인 분석을 이용한 탐사 분석 (출처: '포화란' 팀 분석 자료)
비선형 관계 혹은 변수 간의 상호 작용을 고려한 변수 변환 및 파생 변수 생성
대개 경험이 적은 분석가들은 독립 변수와 종속 변수 간의 관계를 다소 단순하게 생각하기 쉽다. 이를 테면 ‘플레이 시간이 길수록 이탈할 확률은 떨어질 거야’ 라거나 혹은 ‘PvP 승률이 떨어질수록 이탈할 확률이 높아질 거야’ 라는 식이다. 그런데 실상은 더 복잡할 수 있다. 가령, 플레이 시간이 어느 정도까지는 이탈 확률과 음의 상관이지만 일정 수준을 넘어서면 양의 상관으로 바뀐다거나 혹은 더 복잡한 비선형 관계를 가질 수도 있다.
참가팀 중에 ‘INSta’ 라는 팀은 이런 점을 잘 파고 들어 다양한 파생 변수를 시도했다. 이 팀은 제공된 각 변수들에 Sigmoid, Tanh, ReLU 등 다양한 비선형 함수를 적용한 파생 변수를 만든 후 변수 선택 과정을 통해 최적의 조합을 찾는 방식을 시도했다. 일종의 Kernel trick 을 수동으로 한 것인데, 어떻게 보면 다소 비효율적일 수 있지만 흥미로운 시도였다고 생각한다.
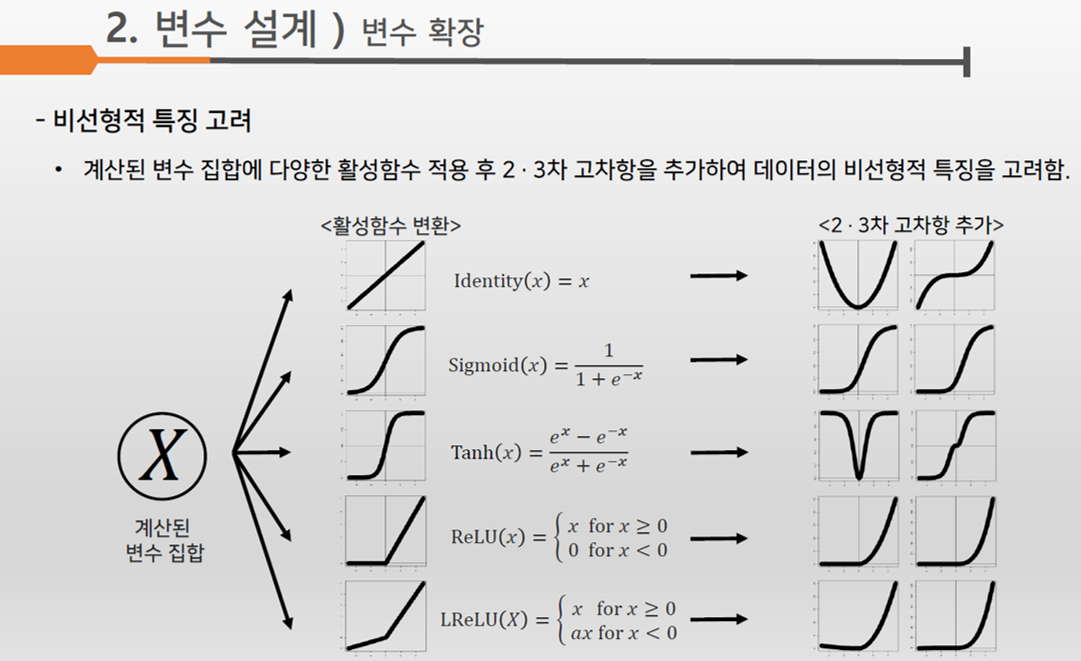 <그림 5> 다양한 비선형 함수 조합을 이용해 레이블간의 분리를 시도한 예 (출처: 'INSta' 팀 분석 자료)
<그림 5> 다양한 비선형 함수 조합을 이용해 레이블간의 분리를 시도한 예 (출처: 'INSta' 팀 분석 자료)
클러스터링을 이용한 플레이 유형 분류
대부분의 팀들이 동일 라벨의 고객을 하나의 집단으로만 취급한 반면, 몇몇 팀들은 먼저 플레이 유형을 나눈 후 각 유형별 탐사 분석이나 예측 모델링을 통해 다양한 이탈 징후를 모델링에 활용하고자 했다. 고객들의 게임 플레이 패턴이나 이탈하게 된 동기는 다양하기 때문에 비록 같은 라벨 (Week, Month, 2Month, Retained) 의 집단이더라도 개개인이 갖고 있는 게임 활동 상의 특징은 다를 수 있다. 따라서 탐사 분석 과정에서는 고객들을 라벨 별로 하나의 집단으로 묶어서 라벨 별 특징을 비교하기 보다는 좀 더 세분화된 유형을 나눈 후 비교하는 것이 좀 더 패턴을 찾는데 도움이 될 수 있다. 이를 위해선 클러스터링을 활용하는 것이 좋은 방법이다.
다양한 클러스터링 기법을 선보였는데, ‘도토리’ 팀은 k-means 알고리즘을 이용해 게임 활동량을 기준으로 전체 고객을 4개의 유형으로 나눈 후 각 유형별 특징과 이탈 레이블 간의 관계를 분석하였으며, ‘찬호는 지금 누구랑 사귈까’ 팀은 주 별 활동 시퀀스에 대해서 계층 클러스터링을 통해 유형을 분류하는 방법을 시도하였다. ‘플라이하이’ 라는 팀은 k-means 클러스터링 결과로 나온 유형 정보를 예측 모델의 변수로 사용하였는데 마치 대표적인 앙상블 기법인 ‘스태킹 (stacking)’ 의 변형이라는 느낌이 들었다. ‘섭씨32도’ 팀은 t-SNE 알고리즘을 이용하여 학습 데이터 상의 고객들을 좀 더 다양한 유형으로 분류했으며, 시각화를 통해 이들 유형과 이탈 라벨 상의 관계를 직관적으로 보인 점이 인상적이었다.
끝으로 ‘Level 0’ 팀은 캐릭터 간 거래나 퀘스트 경험치 획득량 등의 데이터에서 이상한 패턴을 발견한 후 군집화를 통해 작업장 의심 집단과 일반 고객 집단, 더미 집단 (튜토리얼만 진행하고 이탈하는 고객) 을 분류한 후 이 정보를 예측 모델의 변수로 활용하였다. 이후 모델링 단계가 다소 빈약한 점이 아쉽긴 했으나 풍부한 도메인 지식을 바탕으로 집요한 탐사 분석을 시도한 점을 높게 평가하고 싶다.
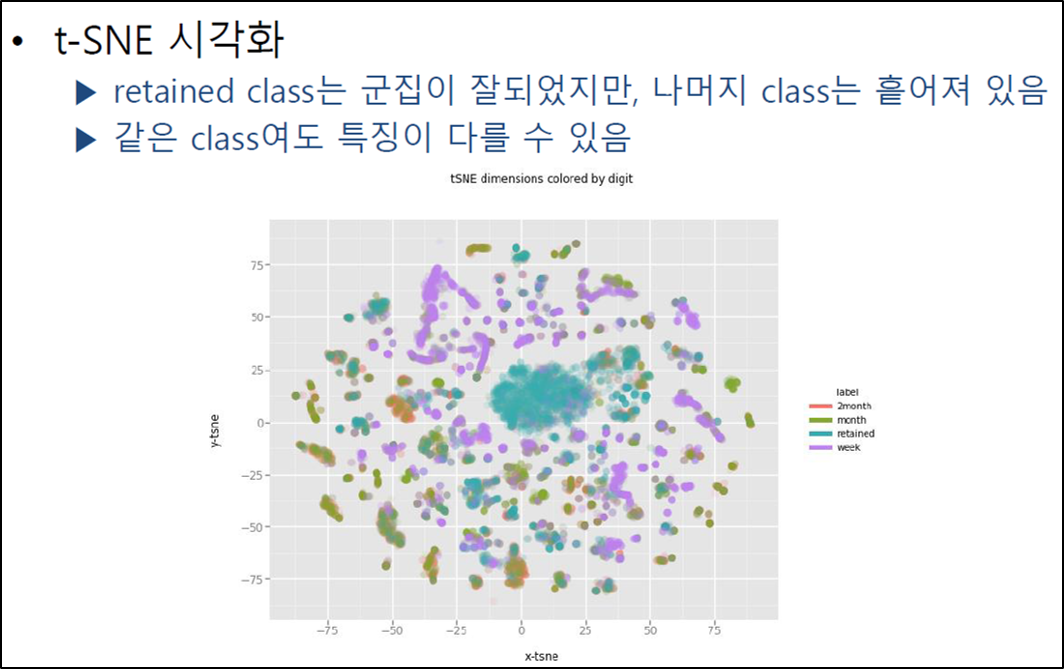 <그림 6> t-SNE 를 이용한 군집 유형과 이탈 레이블 관계 시각화 (출처: '섭씨 32도' 팀 분석 문서)
<그림 6> t-SNE 를 이용한 군집 유형과 이탈 레이블 관계 시각화 (출처: '섭씨 32도' 팀 분석 문서)
전반적으로 전처리 및 탐사 분석 내용이 우수하였으나 굳이 아쉬운 점을 꼽자면, 소셜 네트워크 분석을 진행한 팀이 전혀 없었다는 점이다. B&S와 같은 MMORPG 장르의 게임은 고객 간의 게임 내 사회 관계 활동이 중요한 역할을 한다. 또한 여러 게임 고객 이탈과 관련된 연구에 의하면, 온라인 게임에서 고객의 이탈은 게임 내 사회 관계와 높은 관련성이 있다고 알려져 있기도 하다. 따라서 제공된 다양한 사회 활동 데이터를 이용해 네트워크 분석 기법을 적용해 보았다면 흥미로운 탐사 분석 결과가 나오지 않았을까 생각한다.
예측 모델링 및 튜닝
예측 모델을 만들기 위해 참가팀들이 사용한 학습 알고리즘은 총 27종류에 달할 정도로 다양한 기법들을 시도했다. 또한 한 팀에서 10여 개의 알고리즘을 시도한 경우도 있었다. 그 중에서 가장 널리 사용된 알고리즘은 Random Forest나 XGBoost 같은 앙상블 기반의 알고리즘이었다. 딥러닝 계열의 기법들을 시도한 팀들도 제법 있었으나 성능은 그리 좋지 않았다. 딥러닝 알고리즘 중에서는 ? 대부분의 자료들이 주별로 집계된 일종의 시퀀스 데이터이기 때문인지 ? Long Short-Term Memory (LSTM) 를 시도한 팀들이 가장 많았다.
<표 3> 참가팀들이 사용한 알고리즘과 사용 빈도 (중복 포함)
| 알고리즘 | 빈도 | 알고리즘 | 빈도 |
|---|---|---|---|
| Random Forest | 51 | XGBoost | 45 |
| LightGBM | 26 | Logistic Regression | 15 |
| Support Vector Machine | 11 | Gradient Boosting | 10 |
| K Nearest Neighbot | 8 | LSTM | 8 |
| Multi-layer Perceptron | 8 | AdaBoost | 6 |
| Decision tree | 6 | Bagging | 5 |
| Neural Network | 5 | CatBoost | 4 |
| Extra tree | 4 | Naive Bayes | 4 |
| DNN | 3 | Extremely Randomized Tree | 2 |
| Linear Discriminant Analyssi | 2 | Quadratic Discriminant analysis | 2 |
| Boosting | 1 | CNN | 1 |
| Elastic net | 1 | Gaussian Process | 1 |
| Lasso Regression | 1 | Ridge Regression | 1 |
| SGD | 1 |
대부분의 참가팀이 둘 이상의 알고리즘을 이용하여 모델을 만든 후 최종 모델을 선택하는 방식을 취했다. 이 때, 여러 모델의 성능을 비교해 보고 이 중에서 하나의 모델을 선택하는 방식을 취한 팀과 여러 알고리즘 결과를 조합해 최종 결과를 만드는 앙상블 기법을 이용한 팀의 비중이 거의 비슷했다. 대체적으로 앙상블 기법을 이용한 팀들의 성능이 더 좋았으나 가장 높은 F1 score 를 기록한 팀은 여러 모델 중 하나의 모델을 선택한 팀이었으며 이들이 사용한 최종 모델은 Random forest 였다, 그러나 성능이 가장 나쁜 팀이 사용한 기법도 Random forest 였기 때문에 이 알고리즘의 성능이 가장 좋다기 보다는 가장 많은 팀들이 선호한 알고리즘이었다 라고 해석하는 것이 더 적절하겠다.
앙상블 기법은 다시 크게 세 가지 방식으로 나눌 수 있는데, 단순 voting (hard voting) 과 가중치를 이용한 voting (soft voting), 그리고 여러 모델 결과를 변수로 이용해 추가적인 모델을 만드는 stacking 이다. 이중에서 stacking 을 사용한 비율이 압도적으로 높았으며 성능 역시 stacking 이 voting 보다 전반적으로 우세했다.
<표 4> 참가팀들이 최종적으로 사용한 모델 (자료 상에 명시적으로 표시가 안된 팀은 집계하지 않았음)
| 알고리즘 | 빈도 |
|---|---|
| Ensemble | 26 |
| Random Forest | 16 |
| XGBoost | 11 |
| LightGBM | 8 |
| Gradient Boosting | 1 |
| LSTM | 1 |
| MLP | 1 |
<표 5> 앙상블 상세 기법 (자료 상에 명시적으로 언급하지 않은 팀은 집계하지 않음)
| 앙상블 기법 | 빈도 |
|---|---|
| stacking | 12 |
| soft voting | 4 |
| hard voting | 3 |
대부분의 팀들이 모델 튜닝에도 많은 신경을 썼는데 주로 Grid search 나 Bayesian optimization을 많이 이용했다.
모델 해석 및 이탈 원인 분석
대부분의 참가팀들이 모델 결과를 해석하는데 변수 중요도 정보를 활용하였다. Random forest나 Gradient Boosting 같은 트리 방식의 모델들은 각 변수 별로 엔트로피나 정보 획득량 (Information gain) 을 기준으로 변수의 중요도를 계산한다. 그래서 많은 분석가들은 트리 모델에서 나오는 변수 중요도를 근거로 어떤 변수가 이탈 라벨을 분류하는데 영향력이 큰지 정리한다. 그러나 이 방법은 다른 변수들과의 상호 작용을 고려하지 않는 한계가 있으며, 어떤 변수의 엔트로피가 높거나 낮은지에 대해서만 알려줄 뿐 해당 변수와 이탈 간의 관계가 구체적으로 어떤지는 알려주지 않기 때문에 모델 해석에 활용하기엔 정보가 매우 빈약하다.
이 점을 보완하기 위해 몇몇 팀들은 Partial Dependence Plot (PDP) 을 이용했다. PDP는 쉽게 말해, 어떤 입력 변수 값의 변화에 따라 예측 모델 결과 값의 평균적인 변화를 시각화한 것이다. 특히, ‘파란만장 시즌2’ 팀은 변수간의 상호 작용을 고려하여 모델의 분류 기준을 좀 더 정교하게 해석하여 눈에 띄었다.
 <그림 7> 변수 간 상호 작용을 고려한 PDP 시각화 (출처: '파란만장 시즌 2' 팀 분석 자료)
<그림 7> 변수 간 상호 작용을 고려한 PDP 시각화 (출처: '파란만장 시즌 2' 팀 분석 자료)
그 외에도 SHAP Value Analysis나 LIME 을 이용하여 모델 해석을 시도한 팀들도 있었다. 대다수가 학생들로 구성된 팀임에도 불구하고 비교적 최근에 등장한 이런 최신 기법들을 적극적으로 활용한 점은 무척 놀라웠다.
다만, 많은 팀들이 모델 해석 결과를 이탈 원인으로 설명하는 경향이 있었는데 이것은 다소 위험한 해석이라 생각한다. PDP나 SHAP, LIME 등은 분류 모델이 라벨을 분류하는 기준을 해석하는 것이지 실제 고객이 이탈하는 현상을 설명하는 것이 아니다. 모델의 정확도가 70% 남짓 되는 상태에서 분류 모델의 결과를 실제 이탈과 동일한 것으로 해석하는 것도 부적절할뿐더러, 심지어 설령 정확도가 100%라 하더라도 모델의 분류 기준을 이탈 원인이라고 쉽게 단정해서는 안 된다. 결국 모델의 분류 기준을 해석하는 것과 이탈 원인을 분석하는 것은 다르게 취급해야 한다.
마치며
이번에 빅콘테스트를 통해 직접 대회를 주관하면서 우리 나라에 데이터 분석가를 꿈꾸는 우수한 학생들이 정말 많다는 점을 알 수 있었다. 대부분의 참가자들이 취업을 준비하는 대학생들이었음에도 불구하고 웬만한 현업 분석가와 비교하더라도 전혀 부족함이 없을 정도로 분석 수준이 매우 높았다.
최근에 다양한 분석 관련 경진 대회들이 개최되고 있어 이런 경험을 쌓을 기회가 많아진 점, 캐글과 같은 인터넷 사이트나 블로그 등을 통해 여러 가지 분석 노하우가 공유되어 분석 기술들이 보편화되고 있는 점 등이 그 이유라 생각한다.
한편, 국내에 많은 수의 데이터 마이닝 경진 대회가 개최되고 있지만 단지 주최자들은 수상자를 선정하고 상금을 지급하는 행사를 치르는 것 차제에만 집중하고, 참가자들도 참가 및 수상 경력을 이력서에 추가할 스펙의 측면으로만 바라보는 것은 아닐까 라는 생각도 들었다. 경진 대회를 준비하고 진행하는 과정에서 관련 키워드로 웹 검색을 해보면 대회 홍보를 위한 보도 자료 혹은 대회 참가를 위해 팀원들을 모집하는 글은 많이 볼 수 있었지만 대회 진행과 관련된 후기나 참가자들의 분석 노하우에 대한 자료는 거의 찾아 보기 힘들었다.
캐글이 대표적인 데이터 분석 플랫폼이 될 수 있었던 가장 큰 이유는 이들이 다양한 경진 대회 문제를 제공했기 때문이 아니라, 대회에 참여한 수많은 분석가들이 다양한 분석 자료를 공유하고 서로 토론하는 장을 마련한 데에 있다고 생각한다.
이 글에서 빅콘테스트 참가팀들의 분석 기법을 정리한 이유는 이런 노하우 공유를 통해 향후 좀 더 다양하고 체계적인 분석 기법들이 발전했으면 하는 바람이 있기 때문이다. 더불어 우리 나라에 잠재력 높은 우수한 예비 분석가들이 많다는 점도 같이 알리고 싶었다. 더 나아가 경진 대회를 주관하는 기관에서는 앞으로 경진 대회가 좀 더 체계적이고 발전된 모습으로 나아가기 위해서 대회 진행 간에 있었던 여러 가지 이슈나 노하우를 회고하고 공유하는 것이 필요하겠다.
마지막으로 엔씨소프트에서는 향후에도 데이터 분석가들을 위한 분석 경진 대회를 지속적으로 진행할 계획이다. 이를 통해 우수한 예비 분석가를 발굴할 뿐만 아니라, 다양한 탐사 분석 및 모델링 기법들을 정리함으로써 게임 데이터 분석 기법의 체계화 및 발전에 조금이나마 기여할 수 있기를 바란다.