
인턴 생활기 시즌2 #3
by DANBI
그 동안 인턴 생활기에 업무 외에 일상적인 얘기를 많이 못 담아 드린 것 같습니다. 저희는 업무 외적으로도 다양한 활동을 수행했는데요. 첫날 본 여러 직무의 인턴 분들과 다시 만나는 자리인 인터미션, 팀내 회식자리가 있었습니다. 그 중 다양한 회식자리가 인상 깊었는데요. I&I실의 전 인원이 참여한 회식, 그리고 90년대생, 80년대생으로 컨셉을 나누어 재미있는 회식 자리를 만들어 주셨습니다. 맛있는 음식을 먹으며 누적된 피로를 풀고 팀원들과 친근한 분위기에서 대화할 수 있는 좋은 자리였습니다. :) (원래 영화 라이온킹을 볼 예정이었는데 취소할 정도로 재밌었습니다…)
임베딩 벡터를 뽑는 과정 파악하기
이번 주에는 SPARKSQL 로부터 추출된 데이터를 활용하는 전반적인 흐름에 대해 살펴보았습니다.
이전에 뽑은 시퀀스 데이터를 이용해 임베딩 하는 과정을 하게 된다 말씀 드렸는데요. 여기서 말하는 임베딩이란 텍스트 분석에서 익히 알려진 Word2Vec 임베딩 방법 등을 말합니다. 텍스트의 유의어, 반의어를 벡터 공간에 나타내는 것과 유사하게 각 행동 로그의 임베딩 벡터가 유저 행동 로그의 유사성, 반대 관계 등을 나타내 줄 수 있습니다. 이렇게 유저의 각 활동 로그에 대한 의미를 찾아 여러가지 분석에 활용할 수 있습니다. 따라서 임베딩 벡터 학습이 잘 될 수 있게 하기 위해 여러 전처리 과정을 반복하고, 임베딩 벡터 학습 모델을 고도화하는 작업이 중요하다 할 수 있습니다.
임베딩 벡터를 만들기 위한 딥러닝 모델 코드와 서비스를 위한 코드가 서버 내에 구현되어 있었는데요. 이렇게 모듈화 되어 있는 다양한 코드들의 각 기능을 멘토님께 설명 받을 수 있었습니다.
이후 실제 학습이 이루어지는 부분에 대한 코드를 따로 분리하여 보는 실습을 진행했습니다. 이전에 추출해둔 시퀀스 데이터를 모델 학습을 담당하는 코드의 input 데이터로 사용하여 모델을 학습하는 과정부터 최종적으로 서비스에 사용될 모델을 저장하는 과정까지 이해할 수 있었습니다. 추후에 이 모델을 활용하여 각 유저의 시퀀스 정보를 모델에 넣어 유저의 정보가 압축된 임베딩 벡터를 추출해 낼 수 있습니다.
그렇다면 이렇게 얻은 임베딩 벡터는 어떻게 활용할 수 있을까요? 한 가지 방법으로 클러스터링 기법을 활용하여 유저를 특징이 비슷한 유형별로 분류해낼 수 있습니다. 팀 내에서는 다양한 클러스터링 기법들을 활용하고 있었는데 임베딩 벡터에 대한 클러스터링을 진행할 때에는 DBSCAN 알고리즘을 적용하고 있었습니다.
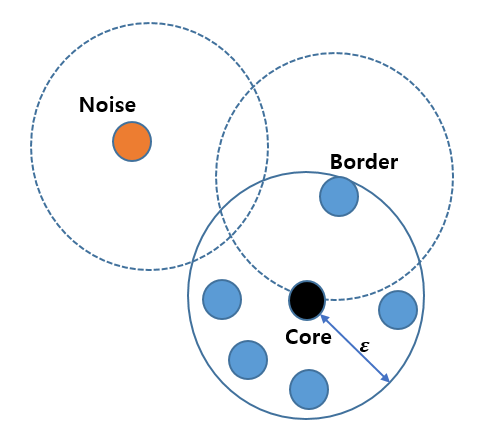
DBSCAN 알고리즘에 대한 대략적인 설명으로는 군집 내 포함 최소 샘플 수, 거리 반경을 지정하게 됩니다. 예를 들어 거리 반경이 3, 최소 샘플 수가 4라고 했을 때, 특정 점을 하나 선택한 후 다른 점과의 거리가 3 안에 들어오는 샘플이 4개 이상이라면 선택한 점을 core point라고 부르게 됩니다. 반면에 4개의 샘플이 포함되지 않으면 border point, 아무것도 포함되지 않으면 noise point라 하는데요. 앞서 말씀 드린 core point를 기준으로 군집을 형성해 가면서 인근의 border point 를 같은 군집으로 합쳐 나가는 것이 DBSCAN 알고리즘의 학습 방식입니다.
앞으로는 이러한 임베딩 벡터를 잘 만들기 위한 데이터 전처리, 모델 학습과정, 군집 분석 결과로 얻을 수 있는 인사이트 등을 다뤄볼 예정입니다 :D
R를 이용한 데이터 분석
저번 주에 이용한 Hive 쿼리를 통해서 추출되었던 데이터들을 R를 이용해서 분석해보았습니다. 추출한 데이터는 리니지M 데이터로, 출시 시점부터 2018년 10월까지 접속했던 게임 유저들에 대한 것이었습니다. 월별로 추출된 이 데이터는 접속 날짜, 유입 광고 매체, 신규 유저 여부, 콘텐츠 활동 등을 나타냅니다.
이러한 데이터들을 이용해서 여러 가지 분석을 해보았는데요. 먼저 특정 달에 유입된 신규 유저들이 첫 결제까지 걸린 시간을 이용해서 광고 매체를 통해서 들어온 유저와 그렇지 않은 유저(이하 오가닉)를 비교 분석해 보았습니다. 첫 결제까지 걸린 시간은 시간에 따른 미결제율 곡선을 그려 확인할 수 있었습니다. R의 survival 패키지와 ggfortify라는 패키지를 이용하여 생존 곡선을 차용하여 이와 비슷하게 그릴 수 있었는데요. 각 달의 미결제율 곡선을 보고 광고 매체를 통해서 들어온 유저와 오가닉 유저의 결제 시점이나 결제율에 대한 차이를 비교 분석 할 수 있었습니다.
또한 유저들의 컨텐츠 활동을 생산/소비/소셜 활동으로 나누어 광고 매체와 오가닉 간의 차이가 나타나는지 알아보았습니다. 신규 유저와 복귀 유저 별로 광고매체가 오가닉보다 항상 수치가 좋았던 특정 활동이 있는지, 또 그와 반대인 활동들이 있는지 살펴 보았습니다. 이를 쉽게 보기 위해 아래와 같이 콘텐츠 별로 ggplot 패키지의 박스 플랏을 그려보았고 이러한 그래프들을 통해서 특정 활동 별로 패턴이 있는지 살펴볼 수 있었습니다.
(보안상의 이유로, 구체적인 값은 표기하지 않은 점 참고 부탁 드립니다.)
이처럼 R의 여러가지 패키지를 이용해서 분석 결과를 나타내 보았습니다. 이번 분석 업무를 통해 효과적으로 데이터 시각화하는 방식을 깨달았습니다. :)