
인턴 생활기 시즌2 #4
by DANBI
이번 주에는 멘토&멘티 점심 회식을 통해 회사 생활에 대한 이야기를 더 깊게 나눌 수 있었습니다. 또한 매주 업무 진행 상황을 공유하는 실 회의에 참석하여 멘토님들이 속한 프로젝트의 흐름을 파악할 수 있었습니다. 실 내 회의 이외에도, 유관 부서와 함께 진행하는 회의에 참석해서 저희 팀에서 구축한 분석 도구를 공유하고 요구 사항을 조정하는 과정을 경험할 수 있었습니다.
Hive 예제 연습
이번 주에는 Hive DB에 있는 아이온, 블레이드앤소울과 같은 PC 게임들의 유저 활동 데이터도 살펴보았습니다. 팀에서 쿼리 교육용으로 만들어 놓은 예제 문제들을 풀면서 쿼리에 대한 이해뿐만 아니라 테이블마다 어떤 정보가 담겨 있는지 파악할 수 있었습니다.
원하는 내용의 데이터를 추출하기 위해서는 여러 테이블들을 사용해야 하기 때문에 필요한 테이블들을 조인하고 데이터를 가공하는 일에 익숙해져야 합니다. 데이터 가공을 효율적으로 하기 위해서는 여러 함수들을 상황에 맞게 잘 활용하는 것이 좋습니다. 내장되어 있는 많은 함수들 가운데 특정 기준에 따라 나열한 후 상위 몇 개의 값을 추출하는 rank() 함수나 그룹별로 나누어 값을 요약하는 avg() 과 같은 함수가 유용하게 많이 쓰였습니다.
예를 들어, 블레이드앤소울에서 2019년 6월 첫째 주에 수행한 퀘스트 중 완료율이 낮은 하위 10개의 퀘스트와 평균 완료 시간을 살펴본다고 한다면, 해당 기간에 접속한 유저의 퀘스트 획득/완료 로그와 퀘스트 명을 테이블에서 찾아야 합니다. 계정과 퀘스트를 그룹화한 뒤 rank()함수를 이용하면 낮은 완료율을 갖고 있는 퀘스트 하위 10개를 추출할 수 있고 avg() 함수를 이용하여 퀘스트 별로 완료 시간이 얼마정도 걸리는지 계산할 수 있습니다.
악성 유저(봇) 탐지
- TensorBoard를 활용한 모델 시각화
저희 팀에서는 자연어처리 분야에서 많이 사용되는 word2vec를 활용하여 게임에서 발생하는 행동 로그(word)를 벡터(vec)로 변형하는 작업을 진행했었는데요. 이 로직에 TensorBoard를 적용해 보았습니다. TensorBoard를 잘 활용하면, TensorFlow로 구현한 로직 및 결과를 쉽게 확인하고 잘 학습되고 있는지 학습 과정도 모니터링 할 수 있습니다.
TensorBoard는 시각화 하고 싶은 노드를 summary operation로 추가한 뒤 실행하여 요약 데이터들을 저장하는데요. 이 요약 데이터는 형태에 따라 histogram, scalar, image 등이 있습니다. 이런 요약 데이터 값들이 기록된 이벤트 파일을 저장할 수 있도록 하는 것이 FileWriter입니다. FileWriter에 이벤트 파일이 저장 위치와, 모델 그래프를 표시하기 위한 그래프를 파라미터로 전달해주면 이를 시각화 해주는 방식으로 동작합니다.
FileWriter에 값을 저장하는 과정에 대해 간략히 말씀드리면, 먼저 summary.FileWriter를 통해 로그를 저장할 경로를 지정해줍니다. 이후 로그를 찍을 손실 함수나 레이어 노드에 summary.scalar , summary.histogram 함수를 적용하여 값을 전달합니다. 각각의 결과는 별도로 sess.run 을 해주어야 하는데 저장할 결과가 많다면 불편할 것입니다. 따라서 summary.merge_all 함수라는 것이 존재하는데요. 이를 통해 여러 노드에 적용한 scalar, histogram 값들을 일일이 실행할 필요 없이 모든 요약 데이터를 한번에 sess.run 할 수 있었습니다. 마지막으로 묶고 싶은 단위마다 name_scope 함수를 적용해서 이름을 정해주면, 묶음별로 일목요연하게 그래프를 볼 수 있었습니다. (사실 word2vec 같은 경우에는 히든 레이어가 한 층으로 되어 있기 때문에 TensorBoard로 시각화할 필요는 없어 보이지만)
TensorBoard 활용에 익숙해지면 앞으로 다룰 복잡한 모델도 한 눈에 볼 수 있는 장점이 있을 것입니다. 아래 그림처럼 데이터를 불러온 후 배치 처리를 위해 데이터를 전처리 하는 과정, 학습에 쓰이는 배치를 나누는 각 과정을 묶어서 볼 수 있었습니다.
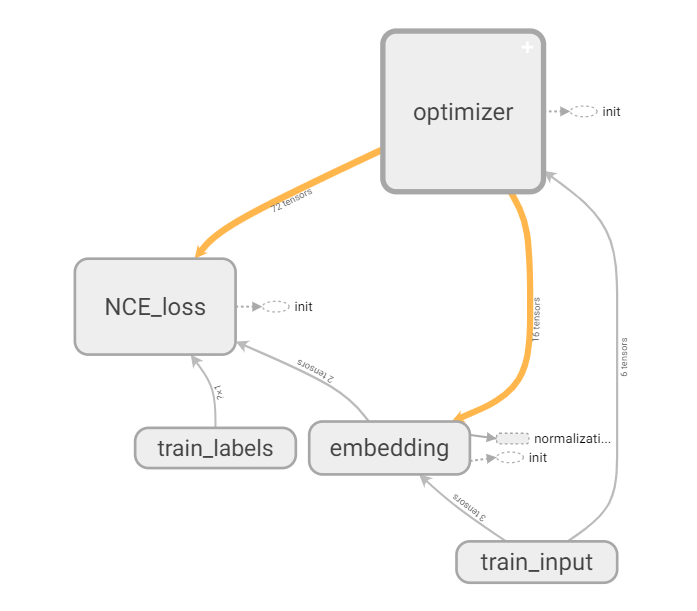
(optimizer, NCE_loss 등 name scope를 지정하여 학습을 한 눈에 볼 수 있습니다!)
두 번째로는 특정 학습 step마다 train/validation loss를 간단히 출력해보았습니다.
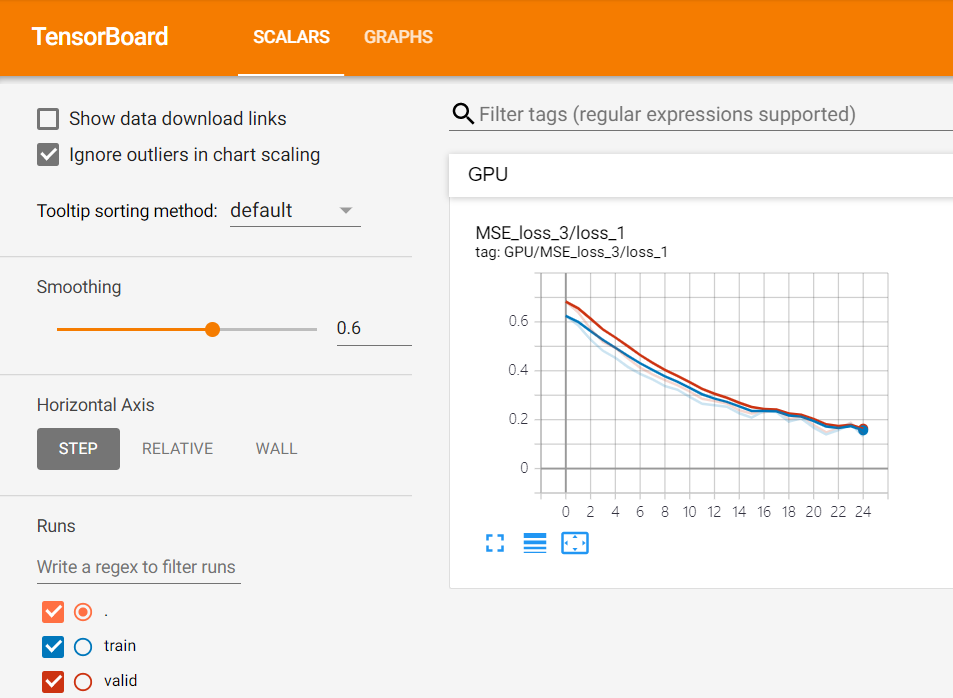
이를 통해 지금 학습하고 있는 모델의 loss 값이 잘 줄어드는지, validation loss와 함께 비교해보며 과적합이 되고 있지는 않은지 확인할 수 있습니다.