
인턴 생활기 시즌2 #6
by DANBI
이번 주에는 모바일 마케팅 분석은 특정 컨텐츠와 관련된 분석을 진행했고, 봇 탐지 분석에서는 유저모델링 작업에서 사용하였던 시퀀스 오토인코더에 대한 내용을 정리해보았습니다.
모바일 마케팅 분석
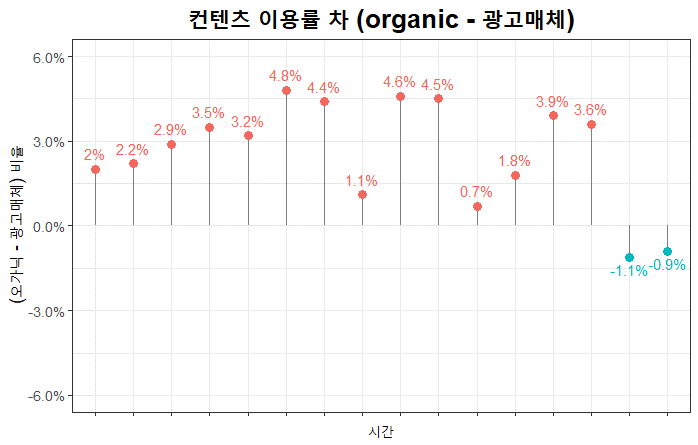
이번 주에는 다양한 시각화 방법들을 시도해보면서 리니지M 유저들의 특정 컨텐츠 활동에 대해 알아보았습니다. (보안상의 이유로, 구체적인 내용은 표기하지 않은 점 참고 부탁 드립니다.) 첫째는 오가닉과 광고 매체 유저 간의 특정 컨텐츠 이용률 비교입니다. 처음에는 두 경로로 유입된 유저들을 나타내기 위해 선 그래프 시각화를 진행해보았습니다. 오가닉 유저들의 이용률이 높다는 것을 볼 수 있었지만 두 그룹간의 차이를 시간 별로 보기 어려웠습니다. 따라서, 오가닉 이용률과 광고 매체 이용률의 차이 값을 활용하여 아래와 같은 롤리팝 그래프로 다시 그려보았습니다. 이를 통해, 두 그룹의 이용률 차이의 정도를 시간 별로 확인할 수 있었습니다.
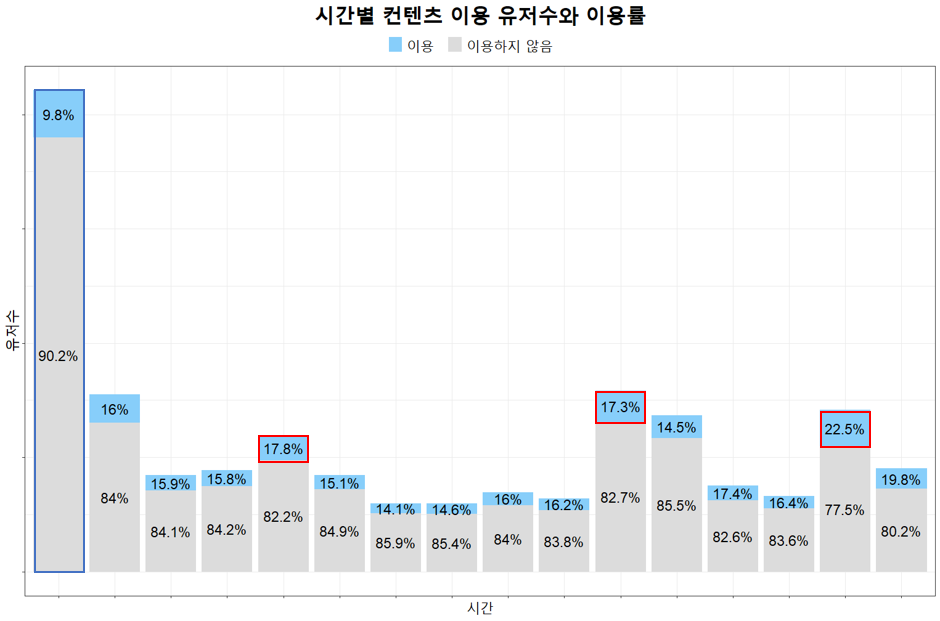
그 다음에는 광고 매체로 유입된 유저들의 컨텐츠 활동에 대해 세부적으로 살펴보았습니다. 기간별로 접속했던 유저 수가 상이하기 때문에 단순히 절대적인 값만 보기 보다는 아래와 같이 비율 정보를 표시하여 나타내 보았습니다. 파란색 박스로 표시된 부분에서 유저 수는 두드러지게 많았지만, 컨텐츠를 이용한 비율은 가장 적었습니다. 또한 빨간색 박스로 표시된 부분인 컨텐츠를 이용한 비율이 높은 기간에는 게임 업데이트와 연관성이 있어 보였습니다.
또한 이 컨텐츠를 이용한 유저들의 활동에 대해 플레이 시간을 이용하여 더 자세히 알아보았습니다.
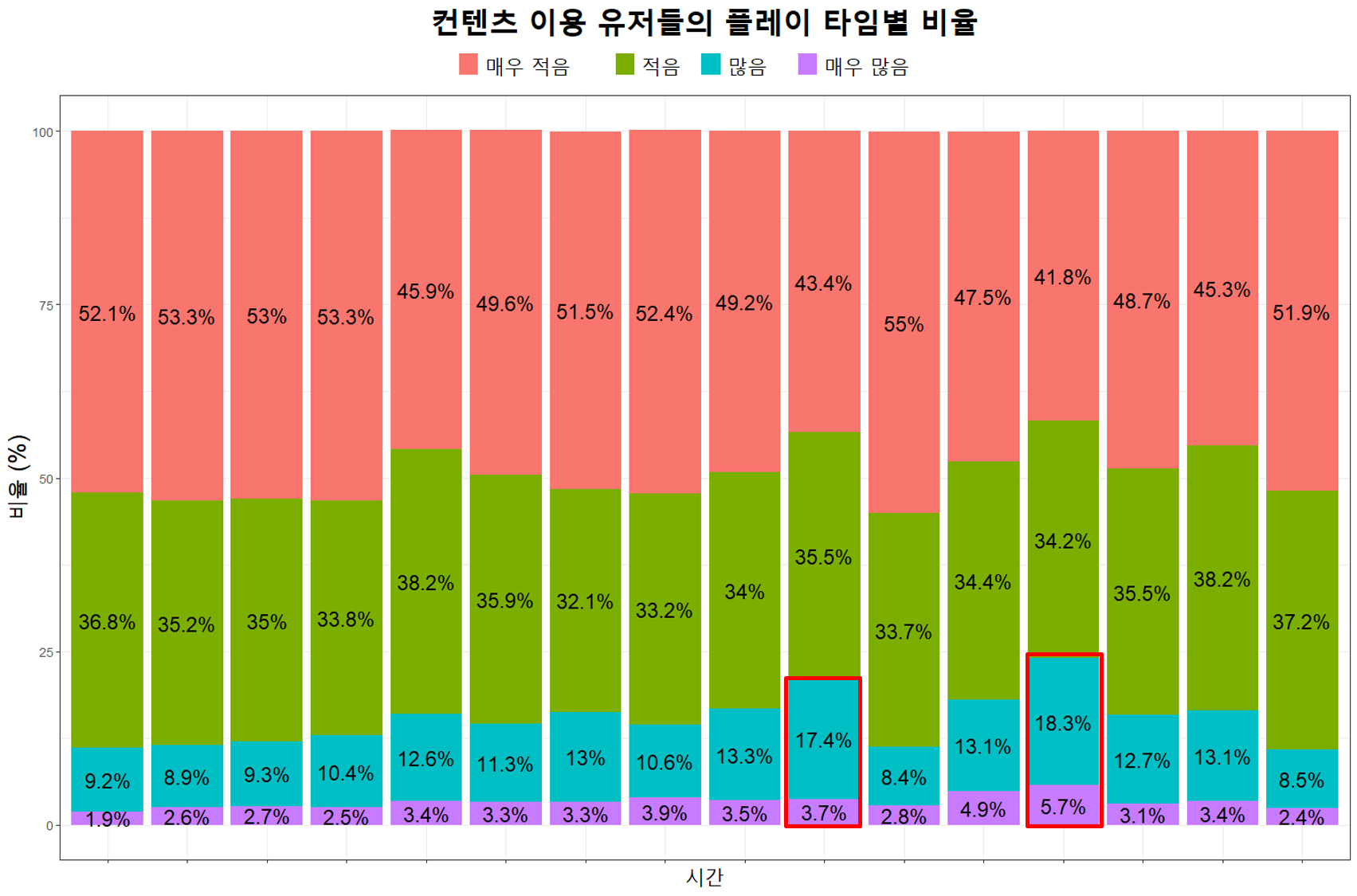
컨텐츠를 이용한 유저들을 정도에 따라 구간을 나눈 후, 위와 같이 그래프를 그려보았습니다. 대체적으로 해당 컨텐츠를 많이 이용하는 유저일수록 그 수가 적었습니다. 평균적으로 컨텐츠 이용 정도가 ‘많음’~’매우 많음’에 해당되는 유저들은 10-15%였는데 빨간색 박스로 표시된 부분과 같이 20% 이상인 경우도 있었습니다. 해당 기간에는 이 컨텐츠 관련 이벤트가 진행되었기 때문이라고 유추해볼 수 있었습니다!
악성 유저(봇) 탐지
- 시퀀스 오토인코더 파악하기
지금까지 인턴 생활기에서 ‘데이터 추출을 위한 Spark SQL 사용’, ‘로그 임베딩 결과에 대한 군집분석 방법’, ‘모델 학습 모니터링을 위한 텐서보드 활용’에 대해 다뤘습니다. 작성한 생활기를 돌아보니 유저 행동 모델링에 사용하는 딥러닝 알고리즘에 대한 설명이 부족했던 것 같습니다. 그래서 이번 주는 유저의 행동 패턴을 압축하기 위해 사용하는 시퀀스 오토인코더에 대해 포스팅하고자 합니다.
- 오토인코더
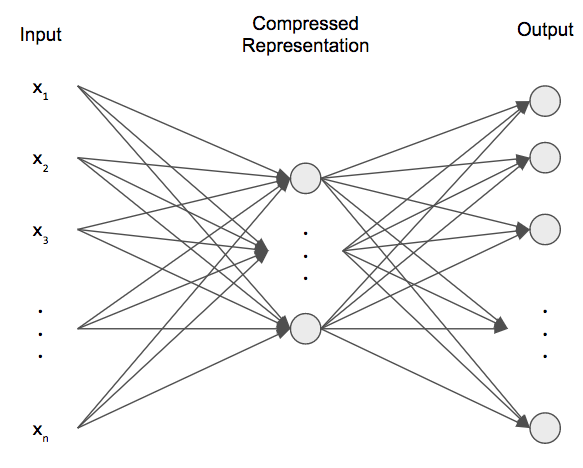
먼저, 오토인코더에 대해 살펴보겠습니다. 오토인코더란, 아래 그림과 같이 입력데이터와 출력데이터를 동일하게 구성한 뉴럴 네트워크입니다. 입력데이터는 은닉층을 거치면서 압축되었다가 출력데이터(=입력데이터)로 복원됩니다. 이 때, 은닉층에서는 입력데이터의 특징을 가장 잘 나타낼 수 있는 정보를 압축하여 담고 있습니다. 즉, 저차원으로 데이터를 줄이면서도 원본 데이터를 잘 표현할 수 있는 특성을 얻고자 합니다.
- Seq2Seq
오토인코더는 어떤 분야에 사용하는 지에 따라 그 방식과 활용 방안이 다양합니다. 저희는 유저 행동 패턴을 효과적으로 다루기 위해서 오토인코더 구조를 가진 Seq2Seq모델을 활용하고 있습니다. Seq2Seq은 주로 기계번역에 사용되는 모델로써 다음과 같은 구조로 이루어져 있습니다.
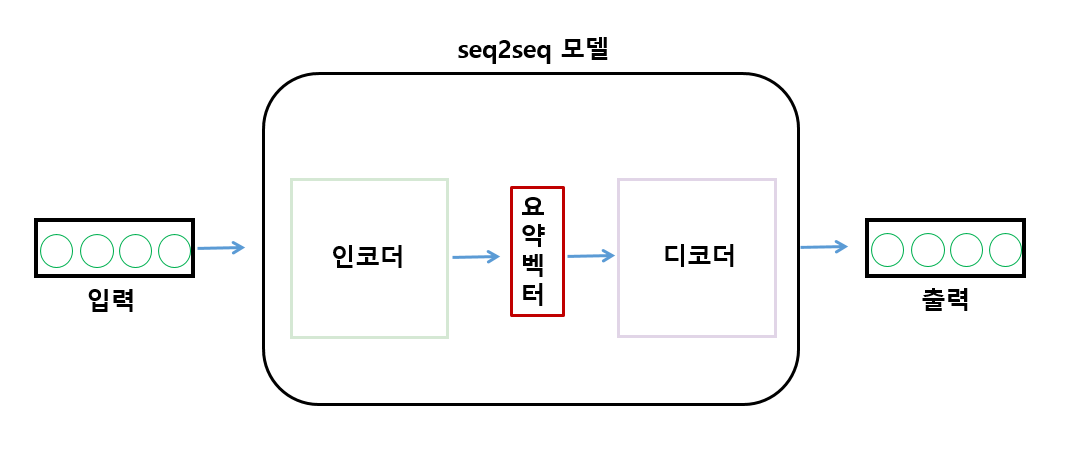
구조를 간략히 살펴보면, 인코더 단에서는 입력 데이터를 통해 특성이 압축된 요약 벡터를 생성해 주는 역할을 합니다. 이후 디코더 단에서는 인코더로부터 생성된 요약 벡터를 넘겨받아 출력 데이터와 비교하며 학습을 진행하는 구조입니다.
이러한 연산은 인코더, 디코더 안에 존재하는 신경망을 통해 진행됩니다. Seq2Seq모델은 신경망의 종류에 따라 여러 형태가 존재하지만, 이 글에서는 LSTM cell로 구성된 모델을 아래 그림과 함께 살펴보겠습니다.
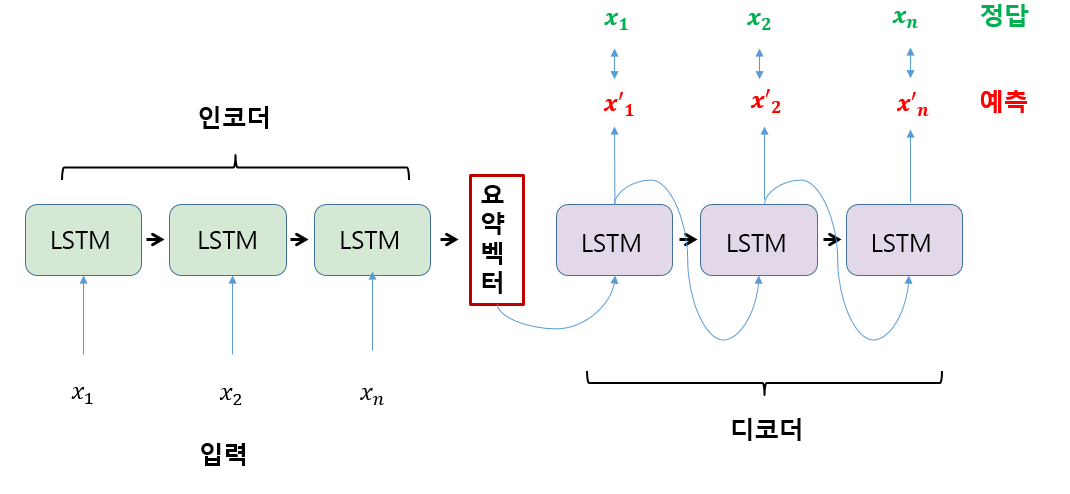
먼저, 인코더에서는 각 시점마다 들어오는 시퀀스 데이터를 입력 받습니다. 첫 LSTM cell은 입력 데이터를 받아 가중치를 계산하고 이 가중치를 다음 시점의 LSTM cell에 넘겨줍니다. 두번째 LSTM cell 은 넘겨받은 가중치와 두 번째 시점의 입력 데이터를 고려하여 가중치를 계산합니다.
이렇게 각 시점의 입력 데이터와 이전 시점까지의 가중치를 함께 고려하는 계산 방식을 마지막 시점까지 이어갑니다. 그러면 마지막 시점의 LSTM cell이 출력한 벡터가 각 시점의 정보를 누적한 요약 벡터가 될 수 있는 것입니다.
다음은 디코더 부분을 살펴보겠습니다. 디코더의 첫 LSTM cell은 마지막 인코더의 LSTM cell로부터 요약된 벡터를 입력 받아 예측 값을 출력합니다. 디코더의 첫 LSTM cell의 가중치와 예측 값은 다음 시점의 LSTM cell이 넘겨 받습니다. 이처럼 현재 시점에서 예측 값과 LSTM cell의 가중치를 다음 시점의 LSTM cell의 입력 값으로 넣는 방식을 끝 시점까지 이어갑니다. 그 후, 각 시점의 실제 값과 디코더의 예측 값을 대조하는 방식으로 모델을 학습시킬 수 있는 것입니다.
- 봇탐지 분석에 활용
그러면 왜 시퀀스 오토인코더가 봇탐지 분석에 필요한 것일까요?
봇탐지 분석에서는 유저의 행동 로그를 이어 붙인 행동 시퀀스 패턴을 이용합니다. 하지만 시퀀스 데이터가 너무 방대한 것이 문제입니다. 활동 로그의 종류가 무수히 많은데다가 여러 날의 행동 로그를 이어 붙인다면, 시퀀스 길이가 기하급수적으로 커지기 때문입니다. 따라서 Seq2Seq모델을 입·출력데이터가 같은 오토인코더로 활용하여 데이터를 압축하고자 하는 것입니다. 유저 행동 모델링의 구체적인 활용에 대해서는 저의 멘토님께서 추후 블로그에 포스팅하실 예정입니다!
인턴 생활을 마치며…
어느덧 인턴 기간 마지막 주에 접어들어 마쳐야 할 시간입니다. (ʘ̥_ʘ̥..) 비록 6주동안의 짧은 시간이었지만 유저들의 활동을 담은 많은 양의 데이터를 추출해보고 다양한 시각화 방법을 활용하여 분석도 해보았습니다. 게임 로그를 다루기 위한 여러 전처리 과정을 거치고 스스로 가설을 설정해 검정하는 등 어려움이 있었지만, 게임 데이터 분석에 대해 더 배우고 알아갈 수 있는 소중한 시간이었습니다. (첫 인턴 생활기를 작성할 때의 목적은 각 회마다 맡은 주제를 발전 시키는 성장기를 보여드리려 했으나, 흐름대로 잘 이어 갔는지 모르겠습니다. ^^;; ) 블로그 작성에 도움을 준 멘토님들께 감사를 전하며 이만 마치겠습니다. 지금까지 저희 포스팅을 읽어주셔서 감사합니다.
