
회귀 모델의 종류와 특징
by DANBI
회귀 모델이란?
회귀 모델을 한 마디로 정의하면 ‘어떤 자료에 대해서 그 값에 영향을 주는 조건을 고려하여 구한 평균’ 입니다. 통계학적인 관점에서 보면 모든 데이터는 아래와 같은 수식으로 표현할 수 있다고 가정합니다.
\[y = h(x_1, x_2, x_3, ..., x_k; \beta_1, \beta_2, \beta_3, ..., \beta_k) + \epsilon\]위 수식에서 h() 가 위에서 말한 조건에 따른 평균을 구하는 함수이며 우리는 이것을 보통 ‘회귀 모델’이라고 부릅니다. 이 함수는 어떤 조건(x1, x2, x3, …)이 주어지면 각 조건의 영향력(beta1, beta2, beta3, …)을 고려하여 해당 조건에서의 평균값을 계산해 주는 것이죠.
뒤에 붙는 e 는 ‘오차항’을 의미합니다. 측정상의 오차나 모든 정보를 파악할 수 없는 점 등 다양한 현실적인 한계로 인해 발생하는 불확실성이 여기에 포함됩니다. 이것은 일종의 ‘잡음(noise)’인데, 이런 잡음은 이론적으로 보면 평균이 0이고 분산이 일정한 정규 분포를 띄는 성질이 있습니다.
우리가 회귀 분석을 한다는 것은 이 h() 함수가 무엇인지를 찾는 과정을 의미합니다. 그럼 우리가 추정한 회귀 모델이 정말 h() 라는 걸 어떻게 확신할 수 있을까요? 엄밀히 말하면 정확히 맞다는 것을 알 방법은 없습니다. 다만 그럴 것이라고 어느 정도는 확신할 수 있는 방법이 있는데, 바로 우리가 만든 회귀 모델의 예측치와 실측치 사이의 차이인 ‘잔차(residual)’가 정말 우리가 가정한 오차항(e) 의 조건을 충족하는지 확인하는 것입니다. 이런 확인 작업을 ‘모델 검정’이라고 부르는데 세세한 방법에 대해서는 여기서 다루지 않겠습니다.
어쨌든 우리는 최대한 실제 h() 에 가깝게 회귀 모델을 만드는 것이 목표입니다. 만약 추정을 잘못하면 몇몇 중요한 조건들을 반영하지 못해 h()의 일부분만 회귀 모델로 만들 수 있는데 이것을 ‘underfitting’ 이라고 부릅니다. 반대로 실제 종속변수에 영향을 주는 조건이 아닌 단순한 ‘잡음’을 평균에 영향을 주는 조건으로 착각하고 모델에 반영할 수도 있는데 이런 것을 ‘overfitting’ 이라고 부릅니다. 보통 overfitting 문제를 많이 다루고 있지만 사실 현실 세계에서 우리가 만드는 대부분의 회귀 모델은 underfitting 문제도 같이 갖고 있습니다. 다시 말해, 우리가 만드는 대부분의 회귀 모델들은 h()의 일부분과 e의 일부분을 같이 반영하고 있는 상태입니다. 단지 둘 중 어느 쪽이 더 많은 비중을 차지하고 있느냐의 문제일 뿐이지요.
한편 우리가 모델을 만드는 이유는 현실을 좀 더 단순한 형태로 표현하기 위해서입니다. 그리고 이렇게 단순화하려면 불필요하다고 생각하는 정보들을 버려야 합니다. 이때, 우리가 회귀 모델을 만들기 위해 버린 정보들이 무엇인지를 설명하는 것이 회귀 모델의 가정(assumption)입니다. 즉, 회귀 모델을 만들 때 ‘실제 데이터는 이러 이러한 특성을 갖고 있다고 가정’하는 것입니다. 따라서 이런 가정이 많아질수록 모델은 좀 더 단순해집니다. 반대로 가정을 최소화할수록 모델은 복잡해지겠죠.
여기서 설명할 다양한 회귀 모델들은 이렇게 데이터가 어떤 특성을 갖고 있다고 가정했느냐에 따라 나뉘어 집니다.
선형성 vs. 비선형성
가장 먼저 고려해야 할 가정은 선형성과 비선형성입니다. ‘선형성(linearity)’란 어떤 집합의 원소쌍(아래 수식의 u와 v)에 대해서 함수 f()가 아래 두 가지 성질을 만족시키는 것을 말합니다 (직관적으로 잘 와닿지 않는 분들을 위해 쉽게 말하면, 일차 다항식을 선형 함수라고 생각하면 됩니다).
\[f(c \times u) = c \times f(u) (여기서 c는 상수)\] \[f(u+v) = f(u) + f(v)\]그런데 이 부분에서 많은 분들이 착각하는 점이 있는데, 회귀 모델에서 선형과 비선형을 구분할 때 독립 변수와 종속 변수의 관계를 기준으로 생각하면 안됩니다. 선형이냐 비선형이냐를 결정하는 대상은 ‘변수’가 아니라 ‘회귀 계수’입니다. 다시 말해, 회귀식에서 x를 기준으로 선형 함수인지를 판단하는 것이 아닙니다. 왜냐하면 회귀 모델에서 우리가 추정해야 하는 미지수는 독립 변수나 종속 변수가 아니라 회귀 계수이기 때문입니다. 이에 대해서는 ‘선형 회귀 모델에서 선형이 의미하는 것은 무엇인가 (https://brunch.co.kr/@gimmesilver/18)’ 에서 자세하게 설명을 했으니 한번 읽어 보시기 바랍니다.
어쨌든 우리가 (특히 통계학 수업에서) 배우는 대부분의 회귀 모델은 선형 회귀 모델입니다. 반면 최근에 크게 주목받고 있는 딥러닝은 대표적인 비선형 회귀 모델링 방법입니다. 선형 회귀 모델은 회귀 계수간의 관계가 비교적 직관적이기 때문에 각 조건의 영향력을 해석하기가 비선형 모델에 비해 쉽습니다. 대신 모든 조건들을 오직 선형 결합(쉽게 말해 더하기)으로만 표현해야 하기 때문에 표현력에 한계가 있습니다. 다시 말해 실제 모델링 대상이 되는 현실 데이터가 선형 결합으로 표현이 불가능한 데이터라면 정확한 회귀 모델을 만들 수 없습니다.
선형 회귀 모델의 이런 한계점 때문에 모델의 해석보다는 예측 자체가 중요한 복잡한 문제에 대해서는 딥러닝을 이용합니다. 딥러닝은 비선형 회귀 모델이기 때문에 현실 세계의 복잡한 관계도 거의 대부분 표현이 가능합니다. 즉, underfitting 문제에서 상대적으로 자유롭습니다. 대신 불필요한 잡음을 모델에 반영하는 overfitting 문제가 발생할 가능성이 더 크기 때문에 이 문제를 피하기 위한 다양한 기법들이 연구되고 있죠.
정리하자면, 회귀 모델은 모델링 대상을 회귀 계수의 선형 결합만으로 표현할 것인지 여부에 따라 ‘선형’ 회귀 모델과 ‘비선형’ 회귀 모델로 구분됩니다.
종속 변수 개수에 따른 구분
두번째로 고려해야할 가정은 종속 변수 개수입니다. 보통 y = h(x) + e 라고 하면 종속 변수인 y는 하나인것만 생각합니다만 실제로는 종속 변수가 여러 개인 경우에 대해서도 회귀 모델을 만들 때가 있습니다. 그래서 종속 변수가 하나인 회귀 모델을 ‘단변량(univariate)’ 회귀 모델 이라고 부르며, 종속 변수가 2개 이상인 경우를 ‘다변량(multivariate)’ 회귀 모델이라고 부릅니다.
다변량 회귀 모델은 주로 계량 경제학에서 많이 다루는데 종속 변수간에 서로 상관성이 있는지, 종속 변수가 서로 다른 종속변수의 독립변수 역할도 수행하는지, 어떤 두 종속 변수가 장기 균형 관계를 갖는지 등의 조건에 따라 다양한 회귀 모델로 나뉩니다.
여기까지가 회귀 모델의 가장 상위 단계에서 고려해야 하는 모델링 방식입니다. 즉, 모델링 대상이 하나의 종속변수만 다루는지 아니면 여러 개의 종속변수를 같이 고려해야 하는지, 종속변수가 회귀계수의 선형 결합만으로 표현이 가능한지 아닌지에 따라 ‘단변량 선형 회귀 모델’, ‘단변량 비선형 회귀 모델’, ‘다변량 선형 회귀 모델’, ‘다변량 비선형 회귀 모델’로 구분하게 되며 이 각각이 다시 하위에 광범위한 모델링 기법들을 포함하고 있습니다 (그런데 보통 비선형 회귀 모델에서는 단변량과 다변량을 따로 구분하지는 않는 것 같습니다). 이 글에서 이 모든 회귀 모델들을 다루기는 불가능하므로 범위를 좁혀서, 회귀 분석을 할 때 주로 사용하고 있는 ‘단변량 선형 회귀 모델’에 대해서 좀 더 자세히 다루겠습니다.
고전적 선형 회귀 모델 (Classical linear regression model)
고전적 선형 회귀 모델은 단변량 선형 회귀 모델의 가장 기본 형태입니다. R에서는 lm()이라는 함수를 이용해서 모델링을 하는데, 이 모델을 수식으로 표현하면 아래와 같습니다.
\[\hat{y} = \beta_0 + \sum_{i=1}^{p}{\beta_i x_i}\]고전적 선형 회귀 모델은 독립 변수의 개수에 따라 아래와 같이 명칭을 구분하기도 합니다.
- 단순 선형 회귀 (simple linear regression): 독립 변수가 하나
- 다중 선형 회귀 (multiple linear regression): 독립 변수가 둘 이상
고전적 선형 회귀 모델은 형태가 단순한만큼 데이터에 대해 많은 가정을 갖고 있습니다.
- 오차항은 평균이 0이고 분산이 일정한 정규 분포를 갖는다.
- 독립변수와 종속변수는 선형 관계이다.
- 오차항은 자기 상관성이 없다.
- 데이터에 아웃라이어가 없다.
- 독립변수와 오차항은 서로 독립이다.
- 독립변수 간에서는 서로 선형적으로 독립이다.
따라서 만약 실제 데이터가 이런 가정을 충족하지 않는다면, 고전적 선형 회귀 모델은 실제 데이터를 정확히 반영하지 못하게 되므로 다른 방법을 사용해야 합니다. 일반적으로 알려진 가이드라인은 다음과 같습니다.
- 독립 변수와 종속 변수가 선형 관계가 아닌 경우: Polynomial regression, Generalized Additive Model (GAM)
- 오차항의 확률분포가 정규분포가 아닌 경우: Generalized Linear Model (GLM)
- 오차항에 자기 상관성이 있는 경우: Auto-regression
- 데이터에 아웃라이어가 있는 경우: Robust regression, Quantile regression
- 독립변수 간에 상관성이 있는 경우(다중공선성): Ridge regression, Lasso regression, Elastic Net regression, Principal Component Regression (PCR), Partial Least Square (PLS) regression
각각에 대한 좀 더 상세한 설명은 다음과 같습니다.
독립 변수와 종속 변수가 선형 관계가 아닌 경우
다항 회귀 (Polynomial regression)
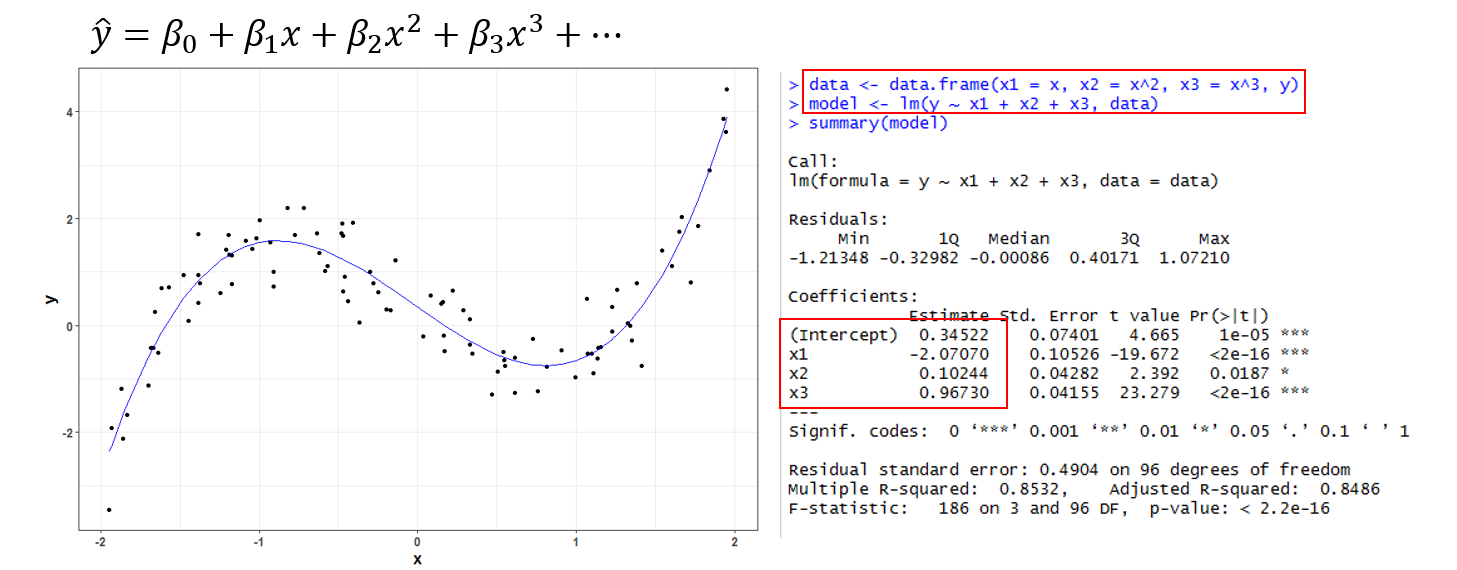
이름 그대로 독립 변수가 다항식으로 구성되는 회귀 모델입니다. 아래 그림처럼 만약 종속변수인 y와 독립변수인 x가 선형 관계가 아닌 곡선 형태를 갖는다면 독립변수에 지수승을 붙여서 여러 개의 변수로 만들어 회귀 모델을 구성하는 기법을 말합니다. 실상 형태적으로 보면 고전적인 다중 선형 회귀 모델과 똑같습니다. 또한 R에서 다항 회귀를 이용하는 방법은 아래 그림에 나와 있듯이 고전적 선형 회귀와 똑같이 lm() 함수를 이용하면 됩니다.
Generalized Additive Model (GAM)
‘일반화 가법 모형(GAM)’은 회귀 모델을 만들 때 독립변수를 그대로 이용하는 것이 아니라 다른 함수의 선형 결합으로 표현하는 기법입니다.
\[\hat{y} = \beta_0 + f_1(x_1) + f_2(x_2) + f_3(x_3) + ... + f_p(x_p) (f: smooth function)\]독립변수에 적용되는 함수들을 smooth function 이라고 부르는데, 이 smooth function 으로 비선형 함수를 사용함으로써 종속변수와 독립변수 간의 비선형 관계를 표현하는 방식입니다. smooth function 으로 어떤 함수를 사용하느냐에 따라 다양한 관계를 표현할 수 있기 때문에 ‘generalized’ 라는 이름이 붙었죠. 실상 바로 위에서 소개한 다항 회귀 역시 일종의 GAM 입니다.
GAM 은 이렇게 표현할 수 있는 모델의 범위가 넓긴 하지만 여전히 회귀 계수 관점에서는 선형 결합 형태로만 표현되는 한계가 있습니다(즉, 비선형 회귀 모델이 아닙니다). 가령, GAM은 두개 이상의 독립 변수 간의 상호 작용에 대한 추정을 자동으로 해주지는 못합니다.
참고로 R에서는 ‘gam’ 이라는 패키지가 있는데 이 패키지에서 제공하는 gam() 이 일반화 가법 모형을 만드는 함수입니다. https://www.r-bloggers.com/generalized-additive-models/ 에 기본적인 사용법이 나와 있습니다.
오차항의 확률분포가 정규분포가 아닌 경우
Generalized Linear Model (GLM)
일반화 선형 회귀 모델은 종속 변수에 적절한 함수를 적용하는 회귀 모델링 기법입니다.
\[g(\hat{y}) = \beta_0 + \sum_{i=1}^{p} {\beta_i x_i} (g: link function)\]이렇게 종속변수에 적용하는 함수를 link function 이라고 부르는데 오차항의 확률 분포가 무엇이냐에 따라 일반적으로 사용하는 link function 이 정해져 있습니다. 대표적인 것 몇 가지만 소개하면 아래와 같습니다.
| 오차항의 확률 분포 | 사용하는 Link function |
|---|---|
| binomial | logit function |
| exponential | inverse function |
| poisson | log function |
보통 GLM은 종속 변수의 특성에 따라 세부적인 명칭을 구분하기도 합니다.
- 종속 변수가 0 아니면 1인 경우: Logistic regression
- 종속 변수가 순위나 선호도와 같이 순서만 있는 데이터인 경우: Ordinal regression
- 종속 변수가 개수(count)를 나타내는 경우: Poisson regression
참고로 R에서는 glm() 함수가 GLM을 만드는 함수인데 이 함수의 옵션 파라미터 중에 ‘family’ 가 바로 위 표에 나오는 오차항의 확률 분포를 지정해주는 옵션입니다. 가령, 로지스틱 회귀의 경우 family 옵션에 ‘binomial’ 을 주는데 그 이유는 이렇게 종속 변수가 0 아니면 1인 경우 오차항의 확률 분포는 binomial 분포라고 가정하는 것이 합리적이기 때문입니다.
GLM은 가장 많이 사용하는 회귀 분석 기법 중 하나입니다. http://www.theanalysisfactor.com/r-glm-model-fit/ 에는 다양한 GLM 활용 방법에 소개되어 있습니다 (시리즈 글이므로 전체 글을 다 보시면 좋습니다).
오차항에 자기 상관성이 있는 경우
Autoregressive Model
보통 시계열 데이터와 같이 순서가 정해져 있는 데이터의 경우 주기성이나 계절성 같이 일정한 패턴을 갖고 있는 경우가 많은데 이것을 ‘자기 상관성’ 이라고 합니다. 그래서 이런 경우에는 아래와 같이 회귀 모델을 만들게 됩니다.
\[\hat{y_t} = \beta_0 + \sum_{i=1}^{k} {\beta_i y_{t-1}} + e_t\]수식을 보면 알 수 있듯이, 특정 시점 t의 데이터를 과거 시점의 종속변수들이 설명하는 방식입니다. 이런 모델을 ‘자기 회귀 (Autoregressive)’ 모델이라고 부릅니다. 대개의 경우 현실 세계에서는 위와 같이 단순한 자기 회귀 모델로만 적용할 수 있는 경우는 거의 없습니다. 보통 위 수식에 있는 e_t 에 또 다른 패턴이 있는 경우가 많으며 어떤 패턴이 있느냐에 따라 크게 두 가지 방식으로 확장됩니다.
- 시간에 따라 평균이 변하는 경우: Auto-Regressive Moving Average (ARMA) model
- 시간에 따라 분산이 달라지는 경우: Auto-Regressive Conditionally Heteroscedastic (ARCH) model
R에서는 arima()라는 함수를 기본 패키지로 제공하며 이 함수를 이용해 자기 상관 모델을 만들 수 있습니다. 다만, arima()는 위에서 소개한 두 가지 방식 중 평균이 변하는 경우에 대해서만 모델링할 수 있습니다. 만약 분산이 달라지는 경우에 대해 처리하려면 GARCH(Generalized ARCH) 모델링 기능을 제공하는 ‘fGARCH’ 같은 패키지를 추가로 설치해야 합니다.
데이터에 아웃라이어가 있는 경우
Robust regression
일반적으로 선형 회귀 모델에서는 회귀 계수를 추정할 때 잔차의 제곱합을 이용하는 ‘최소 제곱법’을 사용합니다. 그런데 이렇게 잔차의 제곱을 이용할 경우 아웃라이어와 같이 잔차가 다른 데이터에 비해 매우 큰 경우에는 제곱을 하면 그 값이 비례적으로 커지기 때문에 이 값 하나로 인해 전체 추정치가 왜곡되기 쉽습니다.
Robust regression 은 이런 문제를 완화하기 위한 회귀 모델 기법입니다. 모델의 형태 자체는 일반적인 선형 회귀 모델과 동일하지만 회귀 계수의 추정 방식에서 차이가 있는 것이죠. 가장 널리 알려진 Robust regression 기법은 잔차의 제곱 대신 절대값의 합이 최소가 되도록 계수를 추정하는 방식입니다. 이렇게 절대값을 이용하면 아웃라이어의 영향력이 줄어들기 때문에 왜곡 현상이 완화됩니다. 고전적 선형 회귀와 로버스트 회귀의 계수 추정 방법을 수식으로 비교하면 아래와 같습니다.
-
Classical linear regression: \(argmin_\beta \sum{(\epsilon_i)^2}\)
-
Robust regression: \(argmin_\beta \sum {\|\epsilon_i\|}\)
R에서는 ‘MASS’ 라는 패키지에서 rlm() 함수를 이용하면 로버스트 회귀 분석을 할 수 있습니다. 사용방법은 lm()과 거의 유사합니다.
Quantile regression
첫부분에서 언급했듯이 대부분의 회귀 모델은 어떤 조건에서 종속 변수의 ‘평균’을 추정하는 방식입니다. 그런데 특이하게도 quantile regression은 평균이 아니라 특정 분위값을 추정하는 기법입니다. 분위값이란 전체 데이터를 정렬한 후 전체 순위를 백분율로 표시했을 때 특정 %에 위치한 값을 의미합니다. 예를 들어 1%의 분위값은 상위 1% 그룹의 경계에 있는 데이터의 종속변수값을 말합니다. 따라서 만약 quantile regression을 이용해서 50% 분위값인 중앙값을 추정하는 모델을 만들면 아웃라이어의 영향을 거의 받지 않게 됩니다. 왜냐하면 아웃라이어의 값이 아무리 비정상적으로 크더라도 전체 데이터 상에서 다른 관측값들의 순위는 영향을 받지 않기 때문입니다.
Quantile regression이 갖는 또다른 장점은 분산이 일정하지 않은 이분산(heteroscedasticity) 데이터도 회귀 모델링이 가능하다는 점입니다. 더 나아가 다양한 분위값에 대해 각각 회귀 모델을 만들 경우 데이터의 전반적인 분포와 그에 따른 영향력(회귀계수)의 관계를 추정할 수도 있습니다.
R에서는 ‘quantreg’ 이라는 패키지를 이용해서 quantile 회귀 분석을 할 수 있습니다. 좀 더 상세한 분석 방법은 http://data.library.virginia.edu/getting-started-with-quantile-regression/ 를 참고하시기 바랍니다.
다중공선성이 있는 경우
Ridge / Lasso / Elastic net regression
다중공선성이 있는 데이터에 대해서 그냥 고전적인 선형 회귀 모델을 만들게 되면 회귀 계수의 영향력이 과다 추정될 수 있습니다. 이런 문제를 피하기 위해 가장 널리 알려진 방법이 ‘regularization’이라고 부르는 기법입니다. 여기서 소개하는 Ridge / lasso / elastic net 이 모두 이런 regularization 을 이용한 회귀 모델링 기법입니다. 이것 역시 로버스트 회귀처럼 모델의 형태 자체는 고전적인 선형 회귀 모델과 동일하나 회귀 계수를 추정하는 방식에서 차이가 있습니다. 말로 설명하기에 앞서 우선 수식으로 표현하면 아래와 같습니다.
-
Classical linear regression: \(argmin_\beta \sum{\epsilon_i^2}\)
-
Ridge: \(argmin_\beta {\epsilon_i^2} + \lambda \sum{\beta_k^2}\)
-
Lasso: \(argmin_\beta {\epsilon_i^2} + \lambda \sum{\|\beta_k\|}\)
-
Elastic net: \(argmin_\beta {\epsilon_i^2} + \lambda_1 \sum{\beta_k^2} + \lambda_2 \sum{\|\beta_k\|}\)
위 수식을 보면 고전적인 선형 회귀 모델은 회귀 계수를 추정할 때 잔차의 제곱의 합을 계산합니다. 이 함수를 비용함수라고 부르는데 이 비용 함수가 최소가 되는 회귀 계수를 찾는 것이죠. 그런데 여기서 소개하는 회귀 모델들은 이 비용함수에 (그림에서 빨간색으로 표시한) 추가적인 수식들이 붙습니다. 이런 추가적인 수식을 페널티 함수라고 부릅니다. 말그대로 회귀 계수 값 자체가 너무 커지지 않도록 페널티를 줌으로써 회귀계수값들이 과다 추정되는 것을 막는 것입니다. 이 때 페널티 함수의 형태에 따라 ridge 와 lasso 가 구분됩니다. ridge regression 은 회귀 계수의 제곱합을 계산하는 방식이고, lasso 는 회귀 계수의 절대값을 계산하는 방식입니다. 그리도 elastic net은 이 둘을 결합한 방식이죠.
이런 페널티 함수를 이용하면 다중공선성이 있더라도 회귀 계수 과다 추정을 막을 수 있으며, 더 나아가 모델이 overfitting 되는 문제도 어느 정도 완화시킬 수 있습니다. 그래서 보통 독립 변수의 개수가 데이터의 개수에 비해 너무 많은 경우에 이 기법을 사용합니다. 특히 lasso regression은 영향력이 적은 변수의 회귀 계수값을 0으로 만들기 때문에 일종의 변수 선택 효과까지 있는 장점이 있습니다.
이들 회귀 모델을 R에서 만들기 위해선 ‘glmnet’이라는 패키지를 설치해야 합니다. 사용 방법은 https://www.r-bloggers.com/ridge-regression-and-the-lasso/ 을 참고하시기 바랍니다.
Principal Component Regression (PCR)
PCR은 말그대로 독립 변수들의 주성분(Principal Component)들을 추출한 후 이 주성분들을 이용해서 회귀 모델을 만드는 기법입니다. 즉, PCA + multiple linear regression 입니다. 주성분들은 서로 직교하기 때문에 다중공선성이 발생하지 않습니다. 따라서 안심하고 다중 선형 회귀 모델을 만들 수 있죠.
게다가 PCA를 이용해서 변환한 주성분 변수들 중에서 상위 몇개의 변수만 이용할 경우 위에 lasso 처럼 일종의 regularization 효과를 줄 수 있어 모델의 overfitting 현상도 완화시킬 수 있습니다.
반면, 각각의 주성분 변수들은 실제 독립변수들의 전체 영향력을 부분적으로 반영한 변수들이기 때문에 이 회귀 모델을 이용해서는 각 조건의 영향력을 파악하기가 거의 불가능해지는 문제가 있습니다 (즉, 모델을 해석하기가 어렵습니다). 그래서 실제로 PCR은 잘 사용하지 않습니다.
http://www.milanor.net/blog/performing-principal-components-regression-pcr-in-r/ 은 PCR 에 대해 간략히 소개한 자료입니다.
Partial Least Square (PLS) regression
PCR과 기본 개념은 비슷하지만 아래와 같이 변수들의 변환 방식이 다릅니다.
- PCR: 독립 변수의 분산을 최대로 하는 축을 찾아 데이터를 전사(projection)하는 방식으로 독립변수만 변형합니다.
- PLS: 종속 변수와 독립 변수의 관계를 가장 잘 설명하는 축을 찾아 전사하는 방식으로 종속 변수와 독립 변수를 모두 변형합니다.
https://www.r-bloggers.com/partial-least-squares-regression-in-r/ 에 PLS 에 대한 기본적인 사용법이 나와 있으니 참고하시기 바랍니다.
기타
Survival regression
특정 사건이 발생한 시간을 추정할 때 사용하는 회귀 모델입니다. ‘생존 (Survival)’ 이라는 이름이 붙은 이유는 이 모델링 기법이 의학 분야에서 임상 실험 환자가 사망할때가지의 시간을 추정하기 위한 기법을 고안하는 과정에서 만들어졌기 때문입니다.
예를 들어 어떤 병에 걸린 환자가 그 병으로 인해 사망할 때까지 걸리는 시간을 추정할 때는 다음과 같은 문제들을 처리해야 합니다.
회귀 모델을 만드는 시점에 살아 있는 환자들의 경우 사망할때가지 걸리는 시간을 어떻게 정의해야 하나?
원래 모델링하려는 병이 아닌 다른 원인(자연사 혹은 교통 사고 등)으로 인해 사망한 환자의 경우는 어떻게 처리해야 하나?
만약 해당 병으로 인해 사망한 환자들만을 갖고 회귀 분석을 한다면 사망 환자에 대해서만 편향된 모델이 만들어지기 때문에 전반적으로 사망하는데까지 걸리는 시간이 과소 추정될 수 있습니다. 이런 식으로 내가 모델링하고자 하는 사건이 아직 발생하지 않은 데이터들을 ‘중도 절단 (censoring)’ 데이터라고 부르는데 이런 중도 절단 데이터 문제로 인해 일반적인 회귀 모델을 이용할 수 없습니다.
그래서 생겨난 기법이 생존 분석 기법입니다. 생존 분석 분야는 그 자체로도 굉장히 광범위하기 때문에 전체 내용을 여기서 다 다룰수는 없고 아주 간략하게만 소개하자면, 생존 회귀는 사망 시간을 직접적으로 모델링하는 대신, 어떤 그룹의 시간에 따른 생존율의 변화에 대한 함수를 추정하는 방식을 취합니다.
이후 실제 예측을 할 때는 어떤 관측치가 속한 그룹의 생존율이 50% 미만으로 떨어지는 시간을 추정치로 사용합니다. 참고로 생존 회귀 모델 중 가장 널리 사용되는 기법으로는 Cox Proportional Hazard Model 이 있습니다.
R에서는 ‘survival’이라는 패키지를 이용하면 되는데 http://rstudio-pubs-static.s3.amazonaws.com/5896_8f0fed2ccbbd42489276e554a05af87e.html 에 아주 기본적인 사용법이 정리되어 있습니다.
결론
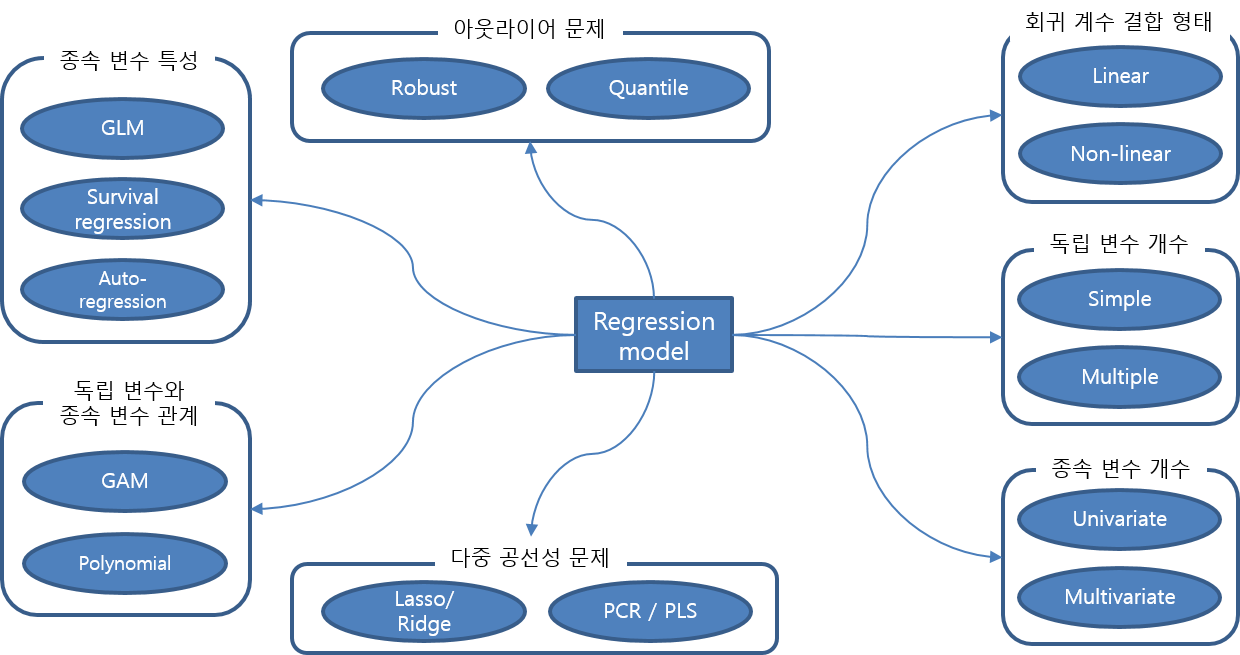
지금까지 언급한 회귀 모델들을 특징에 따라 분류한 내용을 도식화하면 아래 그림과 같습니다.
이것을 다시 일반화 수준에 따라 계층적으로 정리하면 아래 그림처럼 표현할 수 있습니다.
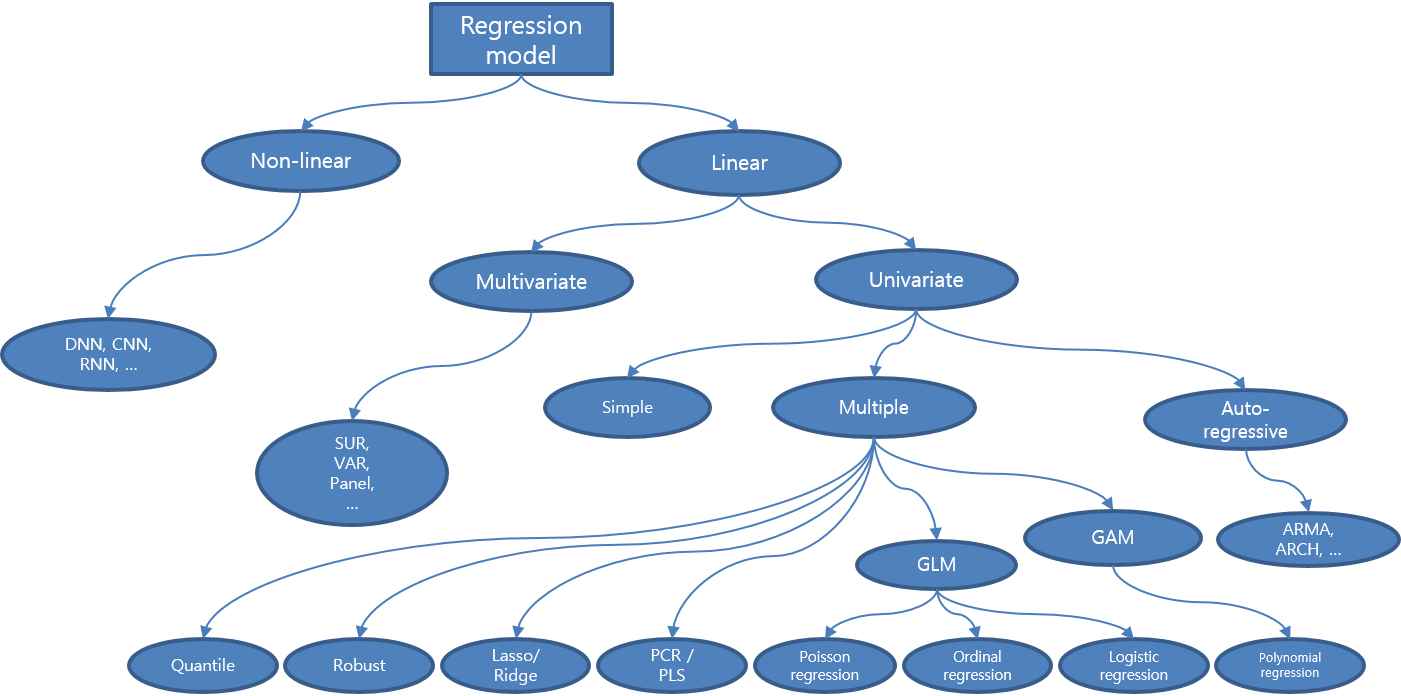
보통 회귀 모델이라고 하면 ‘다중 선형 회귀 모델’이나 ‘로지스틱 회귀 모델’ 정도 만 생각하기 쉽지만 위 도식을 보면 아시다시피 전체 회귀 모델에서 이들이 차지하는 비중은 굉장히 작습니다. 데이터가 가진 특징이나 모델링 목적 등에 따라 적절한 회귀 모델을 사용하는 것이 중요하기 때문에 다양한 회귀 분석 기법을 알아 두는 것은 중요합니다. 더 나아가 올바른 회귀 분석을 위해선 먼저 탐사 분석 과정을 통해 내가 모델링하려는 데이터의 특성을 파악해야하며, 이후 모델링 결과가 정말 내가 생각한 가정과 잘 맞는지를 확인하는 모델 검정 절차가 필요합니다.
물론 모든 가정을 다 따져가며 완벽한 모델을 찾으려는 것은 어리석은 시도일 수 있습니다. 여러 가지 현실적인 제약 때문에 완벽한 회귀 모델을 만드는 것은 불가능에 가깝습니다 (우리는 ‘라플라스의 악마’가 아니기 때문이죠). 특히 실전에서는 비용적, 시간적인 제약으로 인해 더욱 불가능합니다. 따라서 우리는 완벽한 모델을 만드는 것이 아니라 우리가 수행하려는 작업에 사용해도 괜찮은 정도의 모델을 만드는 것을 목표로 삼아야 합니다. ‘All models are wrong, but some are useful(https://en.wikipedia.org/wiki/All_models_are_wrong)’ 이라는 말의 의미를 되새겨 보면 좋겠습니다.
참고자료
https://www.listendata.com/2018/03/regression-analysis.html
https://brunch.co.kr/@gimmesilver/18
https://www.r-bloggers.com/generalized-additive-models/
http://www.theanalysisfactor.com/r-glm-model-fit/
http://data.library.virginia.edu/getting-started-with-quantile-regression/
https://www.r-bloggers.com/ridge-regression-and-the-lasso/
http://rstudio-pubs-static.s3.amazonaws.com/5896_8f0fed2ccbbd42489276e554a05af87e.html