
데이터 시각화 - #2 Box Plot과 Scatter Plot
by DANBI
데이터 시각화 - #2 Box Plot과 Scatter Plot
※본 글에서 제공되는 코드는 모두 R을 기준으로 작성되었습니다.
이전 데이터 시각화 글에서 언급한 것과 같이, 가장 기본적인 데이터 시각화 방식 중 하나인 Box Plot과 Scatter Plot에 대해서 얘기해보도록 하겠습니다. Box Plot과 Scatter Plot은 각각 단변수(Univariate)와 이변수(Bivariate) 값을 시각화하는 가장 기본적인 그래프 중 하나입니다. 아래 그림에서 알 수듯이, 우리는 Box Plot을 통해 한 변수의 분포에 관련된 정보를 알 수 있으며, Scatter Plot을 통해 두 개의 변수 각각의 분포와 더불어 두 변수 간의 관계를 확인할 수 있습니다.
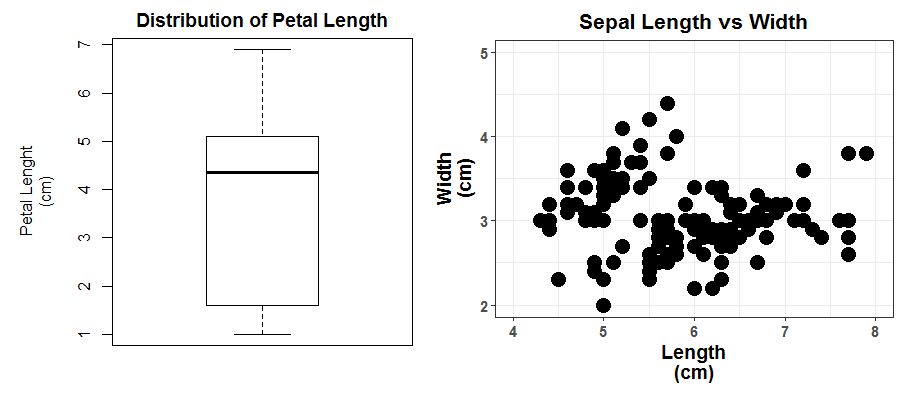
유명한 iris 데이터를 이용한 Box Plot과 Scatter Plot. 좌 : 꽃받침 길이의 분포를 나타내는 Box Plot. 우 : 꽃밪침의 길이와 넓이의 관계를 나타내는 Scatter Plot
이번 글에서는 “Box Plot은 박스의 형태로 변수의 분포를 나타내는 방법이며….” 식의 구글링을 하면 1.2초면 확인이 가능한 기본적인 사항들을 다루기보다는, Box Plot과 Scatter Plot 각각의 단점과 이를 보완하여 정확하게 정보 전달하는 방법을 다뤄보도록 하겠습니다
Box Plot
Box Plot은 탐사분석의 개념을 정립한 John W.?Tukey에?의해 1969년에 발명되었으며, 아래 그림과 같이, 최소값 (min), 최대값(max), 중간값(median 또는 2분위수) 그리고 1Q와 3Q (각각 1분위수, 3분위수)로 이뤄져 있으며, 통상적으로 1Q로부터 IQR (3Q - 1Q의 값)의 1.5배보다 작거나, 3Q로부터 1.5 IQR보다 큰 데이터 포인트들을 아웃라이어로 표현하게 됩니다.
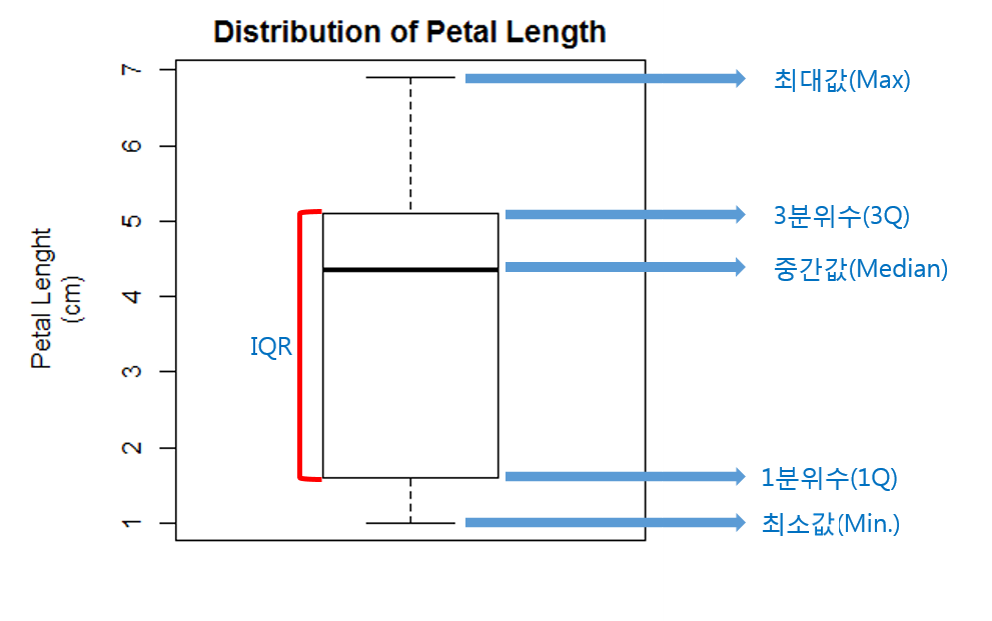
Box Plot은 변수의 분포를 함축하여 보여주는 몇몇 핵심 값들을 시각화 표현하며, 해당 변수의 대략적인 범위 및 분포를 쉽게 확인가능도록 합니다. 또한, 중간값의 위치에 따라 skewness 또한 유추 가능합니다. 하지만 Box Plot만으로 데이터의 분포를 특정하기에는 부족합니다. 특히, Box Plot은 평균 (mean) 그리고 최빈값 (mode)을 유추하기 어렵기 때문에, 히스토그램과 같이 개별 데이터 포인트에 대한 정보(히스토그램의 경우 빈도)를 보여주는 시각화 기법을 통해 보완이 요구됩니다.
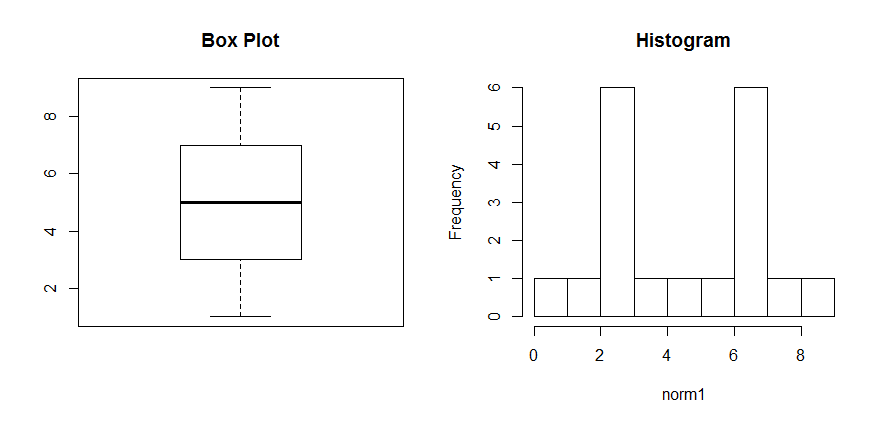
양봉형 데이터에 대한 Box Plot (좌)과 히스토그램 (우)
예를 들어, 위 그림의 Box Plot만을 해석할 시에는, 해당 데이터가 정규분포를 따른다고 판단할 수 있지만, 히스토그램을 그려보면 전형적인 종형의 정규분포가 아닌 양봉형의 분포를 띈다는 것을 알 수 있습니다.
이런 Box Plot의 장점이자 단점인 단순함 또는 함축성을 보완하는 방법은 어떤 것이 있을까요?
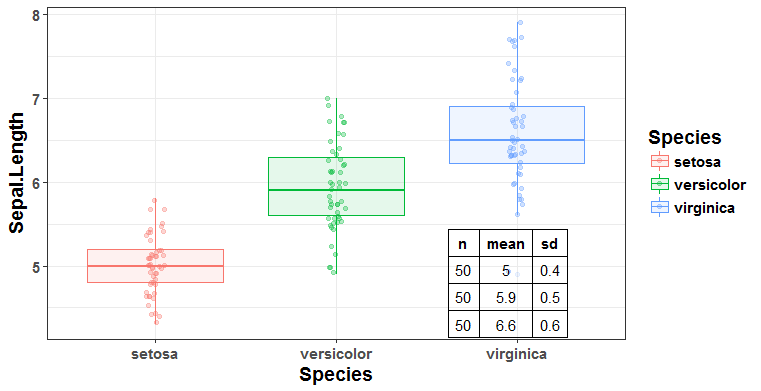
먼저, 위 예시와 같이 히스토그램처럼 데이터 포인트 개별의 정보를 보여주는 다른 도표를 추가로 작성하여 살펴보는 방법이 있습니다. 분석가의 입장에서는 이 방법이 가장 간단하지만, 분석 내용을 타인에게 전달하는 경우에는 적합하지 않습니다. 한 변수의 분포와 대략적인 정보를 나타내기 위해 도표를 두 개를 이용하는 것은 비효율적이며, 독자로 하여금 두 가지의 도표를 비교하도록 하기에, 독자 친화적이지 않기 때문입니다. 이런 단점을 보완하기 위해서는, Box Plot에 직접 각각의 데이터 포인터들을 표시하고, 데이터의 주요 정보들을 아래와 같이 한 도표에 보여주는 것이 좋습니다.
library(ggpubr)
library(ggplot2)
table=desc_statby(iris,measure.var = "Sepal.Length",grps="Species" )
table=table[,c("length","mean","sd")]
colnames(table)=c("n","mean","sd")
table=apply(table,2,function(x){round(x,1)})
table=ggtexttable(table,rows=NULL, theme= ttheme("classic"))
ggplot(data=iris, aes(x=Species, y=Sepal.Length))+
geom_boxplot(alpha=0.1,aes(col=Species,fill=Species))+
geom_jitter(alpha=0.3, aes(col=Species),width=0.05)+theme_bw()+
theme(text=element_text(size=14,face="bold"), plot.title=element_text(hjust=0.5, size=16,face="bold"))+ annotation_custom(ggplotGrob(table),xmin=2.8,xmax=3.1,ymin=1.5)
위 도표는 Iris 데이터의 종 (Species)별 꽃받침 길이의 분포를 나타내는 도표입니다. Box Plot과 더불어 개별 데이터 포인트 및 종별 주요 통계치를 한 도표에 표현하고 있습니다. 위에 첨부된 소스코드와 같이, 깔끔한 도표를 작성하기 위에서는 다양한 라이브러리와 하이퍼 파라미터 설정 그리고 함수들이 요구됩니다만, 상대에게 정보를 전달할 때, 일일이 말로 설명하는 것보다는 코드 몇 줄 더 쓰고 깔끔한 도표로 전달하는 것이 당연히 더욱 효과적이겠습니다.
위의 예시와 같이 Box Plot에 데이터 포인트 각각을 추가해주는 경우, 유의해야 하는 사항이 있습니다. 먼저, 데이터가 너무 방대할 경우 개별 포인트를 그리는 것의 의미가 퇴색되며 컴퓨터에 부담될 수 있습니다. 또한, 점들을 상하좌우로 조금씩 이동시켜 겹치는 점들을 표현하는 jitter를 사용하는 경우, 적절한 값을 사용하는 것이 중요합니다. 너무 큰 값으로 점들을 이동시키면, 각 데이터 포인트들이 갖고 있는 정보 자체가 달라지기 때문입니다.
Scatter Plot
Scatter Plot은 두 변수 간의 관계를 보여주는 대표적인 시각화 기법의 하나입니다. 17세기에 x축과 y축으로 이뤄진 2차원의 공간에 함수(y=f(x))를 시각화하는 수학의 좌표체계의 개념이 고안되었습니다. 참고로, 좌표체계의 개념은 데카르트와 페르마에 의해 고안되었고, 뉴튼에 의해 널리 퍼지게되었으며, 좌표체계 탄생의 역사는 브리태니커 백과사전의 해당 항목 (링크)을 참조하시기 바랍니다. 좌표체계 탄생 이후, 1686년 Edmund Halley에 의해 x와 y의 관계를 나타내는 함수가 아닌, 고도(x축)와 기압(y축)의 관측값의 변화를 나타내는 첫 Scatter Plot(아래 그림)이 탄생하였습니다.
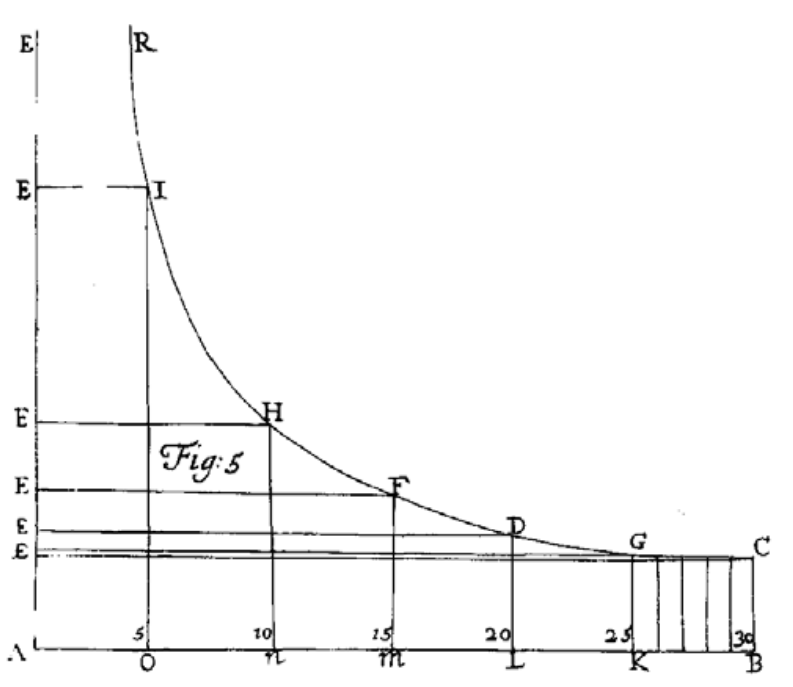
이렇게 고안된 Scatter Plot은 기존 수학의 좌표체계와의 유사성 때문인지 빠르게확산되었고, 1983년 데이터 시각화의 선구자인 Edward?Tufte의 연구에 의하면 과학 출판물에 사용된 도표의 70-80%가 Scatter Plot이라고 집계될 만큼 쉽게 접할 수 있는 시각화 기법입니다.
Scatter Plot은 이름처럼 각각의 데이터 포인트들을 흩 뿌려놓은 (scatter)형태로, 크게 양의 상관관계 (한 변수가 증가할 때 나머지 변수도 같이 증가) 또는 음의 상관관계 (한 변수가 증가할 때 나머지 변수는 감소) 그리고 무상관 (두 변수 간 상관성이 없음)을 나타냅니다. 이렇게 모든 데이터 포인트 각각을 표시해주기 때문에 해상도 높은 정보를 표현할 수 있지만, 모든 포인트를 표현하는 것이 Scatter Plot의 단점이기도 합니다.
먼저 시각화해야 하는 데이터 포인트가 많은 경우 시각화 하는 데에 많은 리소스가 요구됩니다. 또한, 자세한 내용을 알아보기 힘들어지기도 합니다. 아래 그림은 양의 선형관계를 갖도록 생성된 1,000개의 데이터 포인트들을 Scatter Plot으로 표현한 예시입니다.
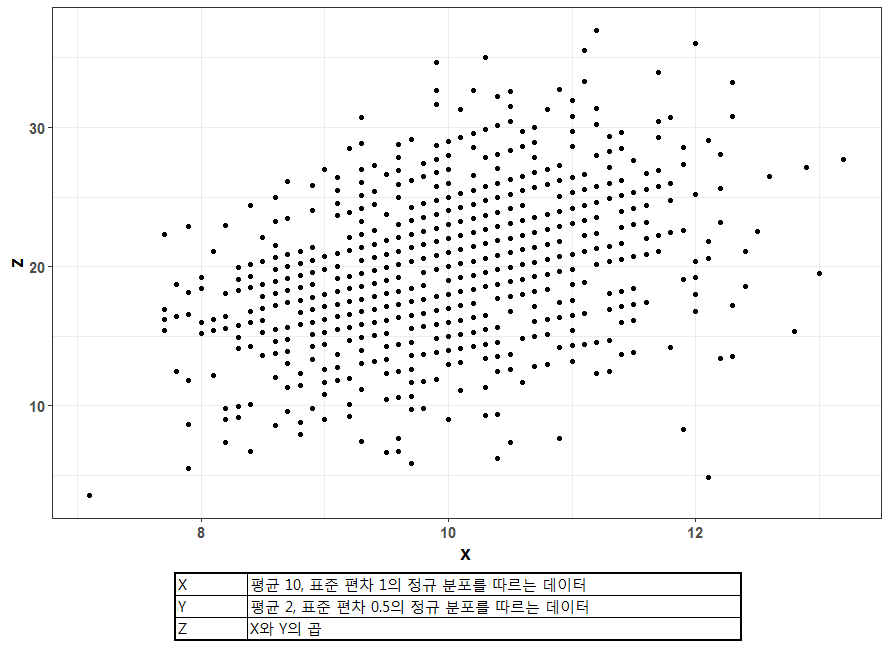
데이터 포인트의 수가 많다 보니, 겹치는 구간들이 생겨 도표 중간 부분의 분포를 알 수가 없습니다. 정규분포를 따르도록 생성이 되었기 때문에, 도표의 중간 부분에 포인트들이 밀집되어 있어야 하지만, 점들이 겹쳐서 표현되서 밀도가 나타나지 않습니다. 또한, 밀도를 알 수 없으므로, 위의 Scatter Plot을 통해, Z와 X 간의 양의 선형관계가 의심되기는 하지만, 확인은 쉽지 않습니다. 겹치는 점들에 의해 실제 분포가 확인되지 않는 문제점을 어떻게 해결할 수 있을까요?
가장 간단한 방법은 위 Box Plot 부분에서 언급되었던 Jitter를 추가하는 것입니다. Jitter는 무작위적인 노이즈를 데이터에 추가하여, 겹치는 점들을 말 그대로 흔들어 (Jitter)버리는 것입니다. 아래 도표를 비교하면, Jitter 추가 전에는 (왼쪽) 겹쳐있었던 점들이 보이고, 이에 따라 도표 가운데 부분의 밀도가 높다는 것을 알 수 있습니다.
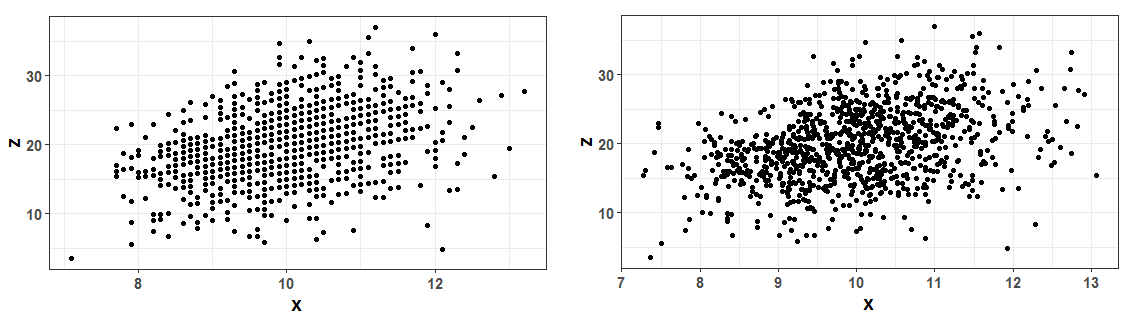
하지만 Jitter는 실제 값을 변형시켜 표현하며, 데이터 포인트의 수가 많을 경우 또 겹칠 수 있다는 단점이 있습니다. 또한, 상대적으로 얼마나 중간 부분의 밀도가 높은지 확인하기도 어렵습니다. 단순히 “아 가운데에 점들이 많구나” 정도만 확인할 수 있지요. 이런 단점을 조금 더 보완하는 방법은 바로 밀도, 즉 데이터의 빈도를 포인트의 크기로 표현하는 방법입니다.
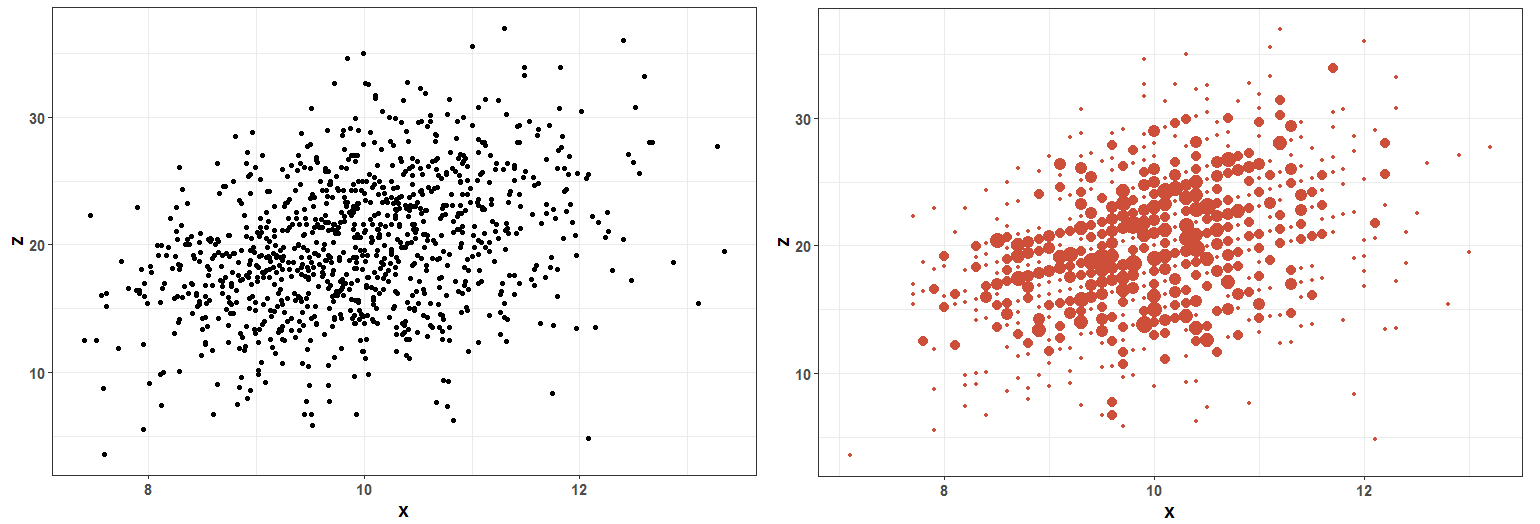
좌측의 도표와 같이 Jitter를 추가한 경우 보다, 우측의 빈도를 점의 크기로 표현한 편이 조금 더 정돈되고, 그리고 상대적으로 도표의 중심 부분에서 벗어남에 따라 밀도가 낮아짐을 한눈에 파악 가능합니다.
하지만 빈도를 크기로 표현한 경우에도, 여전히 각 변수의 분포를 쉽게 파악하기는 어렵습니다. 또한, 변수 간에 정확하게 어떤 관계를 형성하는지 역시 한눈에 확인하기 어렵습니다.
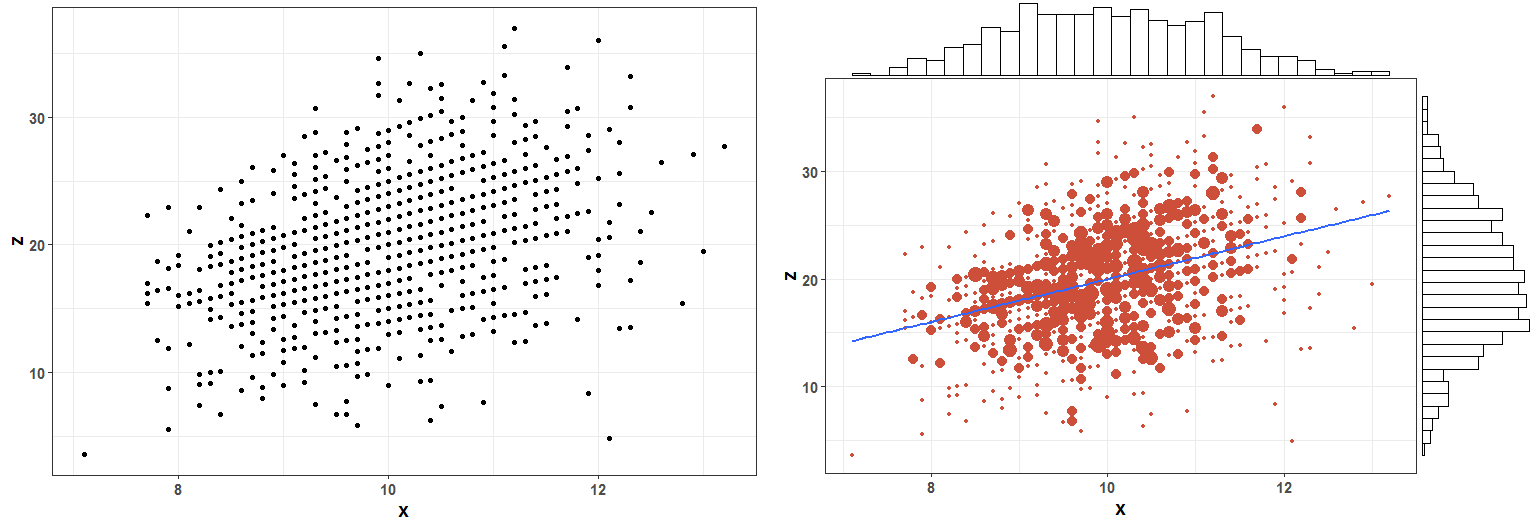
이런 경우 히스토그램과 Scatter Plot을 결합하고, 선형회귀선을 추가하여 시각화하는 방법을 사용할 수 있습니다. 모서리 부분에 각 변수의 히스토그램을 추가하여 분포를 한눈에 표시하고, 선형회귀선을 추가하여 독자가 쉽게 두 변수가 양의 직선형 상관관계 (Z = aX+b)를 갖는다는 것을 확인할수 있습니다. 좌측의 기본형 Scatter Plot과 우측의 업그레이드된 도표를 비교 시, 전달되는 정보의 차이는 하늘과 땅 차이입니다.
library(ggplot2)
library(ggExtra)
x=round(rnorm(1000,10,1),1)
y=round(rnorm(1000,2,0.5),1)
z=x*y
data=data.frame(x,y,z)
ggplot(data,aes(x,z))+geom_point()+theme_bw()+
theme(text=element_text(size=14,face="bold"), plot.title=element_text(hjust=0.5, size=16,face="bold"))
ggplot(data, aes(x, z)) + geom_jitter(width = .5) +theme_bw()+
theme(text=element_text(size=14,face="bold"), plot.title=element_text(hjust=0.5, size=16,face="bold"))
ggplot(data, aes(x, z)) + geom_count(col="tomato3", show.legend=F)+theme_bw()+
theme(text=element_text(size=14,face="bold"), plot.title=element_text(hjust=0.5, size=16,face="bold"))
g=ggplot(data, aes(x, z)) +geom_count(col="tomato3", show.legend=F)+theme_bw()+
theme(text=element_text(size=14,face="bold"), plot.title=element_text(hjust=0.5, size=16,face="bold"))+
geom_smooth(method="lm", se=F)
ggMarginal(g, type = "histogram", fill="transparent")
맺음말
제가 본 글을 통해서 말씀드리게 되는 내용은 만고진리의 정답이라기보다는, 그래프 통해 정보를 전달하고, 발표를 진행해본 경험을 토대로 쌓아온 노하우라는 점을 명심해주시기 바랍니다. 그러므로 때에 따라, 제가 말씀드린 것이 옳지 않은 경우도 있습니다. 다음 글에서는, 데이터 시각화 시 유의해야 할 점 특히 선, 색 등을 고를 때 유의해야 할 점들을 다뤄보도록 하겠습니다.