
p−해킹이란 무엇인가?
by DANBI
들어가며
요즘 p−해킹이란 말을 심심치 않게 들을 수 있다. 혹자는 “재현성”의 위기라고도 한다. 여기서 재현성이란 정확하게 표현하면 “연구 재현성research reproducibility”이다. 즉 어떤 연구 결과물을 해당 연구를 수행한 연구자 뿐 아니라 다른 사람이 이를 반복해도 같은 혹은 거의 같은충분히 비슷한 결과가 나와야 한다는 것이다.
자연과학이나 공학에서 연구 재현성은 해당 연구를 수행한 사람 이외에 다른 사람이 실시하는 실험으로 구현할될 수 있을 것이다. 누가 하더라도 연구가 제시한 조건 및 세부 사항이 갖춰졌을 때에서는 기본적으로 같은 결과가 나와야 한다.
이런 맥락에서는 이해가 간다. 그러면 데이터를 다루는 분야에서 재현성이란 무엇일까? 데이터는 어차피 한번 생성되면 추가되거나 수정되지 않는 이상 고정된다. 이렇게 고정된 데이터를 분석할 때에도하는 데 재현성이 문제가 될 수 있을까? 노벨 경제학상을 받은수상한 로널드 코즈가 했다는 이야기 중에서 유명한 말이 하나 있다.
If you torture the data enough, nature will always confess. 데이터를 충분히 고문하면, 자연은 언제나 바른 말을 하게 될 것이다.
데이터를 고문하다니? 백문이 불여일견!이다. 네이트 실버의 538에서 p−해킹이란 무엇인지를 체험해 볼 수 있는 좋은 웹 서비스를 만들었다.
Hack Your Way To Scientific Glory
같은 데이터 셋에 대해서 여러가지 조건의 붙여서(즉 데이터를 고문해서)필터를 걸어 당신이 원하는 ‘과학적’ 결론을 찾을 수 있다! 왜어째서 과학적인가? 4번 항목의 유의 확률을 보면 된다. ‘업계의 표준’에 따라서 이 녀석이 0.05보다 작으면 나의 결론은 과학적이다! 이렇듯 과학의 후광을 빌리게 원하는 결론을 과학적으로 얻기 위해서 데이터를 고문하는 것이 p−해킹이다. 사실 위 고문 사례는 무척 순진한 경우에 해당한다. 빅데이터와 컴퓨팅 자원이 저렴한 오늘날 데이터를 고문하는 데 동원할 수 있는 방법 또한 다양하다.
사실 조건과 예측
p−해킹의 문제를 살펴보파헤치기 전에 간단한 분류표 먼저 보자. 표부터 보자. 아마도 기계학습 혹은 통계학을 공부한 사람들이라면 한번 쯤은 봤을 법한 분류표다. 이 분류표는 혼동 행렬(confusion matrix)이라고 부르기도 한다.
\(x\) 라는 현상은 존재하거나 존재하지 않거나 두 가지 상태만 지닌다. 이때 \(x\)의 상태에 관해 예측을 하고 예측이 맞았는지 여부를 확인하기 위해서는 다음의 네 가지 경우를 살피면 된다.
| TRUE | FALSE | |
|---|---|---|
| positive | true positive | false positive |
| negative | false negative | true negative |
표에서 TRUE, FALSE는 일종의 ‘사실 조건’을 나타낸다. 사실 조건이란 현상이 실제로 존재하는지 여부를 나타낸다. TRUE면 존재하고 FALSE면 존재하지 않는 것으로 지칭하겠다. positive, negative는 판단 조건이다. 어떤 대상의 존재 유무에 대한 예측을 positive와 negative로 표기하며, positive는 TRUE의 상태임을 예측하는 것이다. 일부러 대문자로 쓴 대목에 유의하시라. 즉, 이 녀석은 형용사가 아니라 현상의 존재 조건에 관한 라벨 같은 것이다.
- positive, negative 예측이 맞는 경우: true positive, true negative
- positive, negative 예측이 틀리는 경우: false positive (오탐), false negative (미탐)
예측 결과(가설 검정의 결과)가 있을 때 당연히 true positive와 true negative의 비율을를 가급적 높이는 것이 당연히 좋다. 예측은 정확할수록 좋은 것이니까. 이 매트릭스에서 예측의 설명력을 측정하는 각종 성과 지표를 도출할 수 의 관심사는 아니니 일단 넘어가자.
그리고 여기서 true, false는 형용사다.1
1종 오류와 2종 오류
통계학을 공부한 사람은 사실 이 매트릭스를 한번은 봤을 것이다. 통계학에서 제일 안 외워지는 것 중 하나가 1종 오류(type I error), 2종 오류(type II error)다.
| TRUE | FALSE | |
|---|---|---|
| positive | \(1-\beta\) | \(\alpha\) |
| negative | \(\beta\) | \(1-\alpha\) |
(\(\alpha, \beta \in [0,1]\))
앞서의 표를 살짝 다르게 표현한 한 것이한 것이한 것이한 것이다. 표에서 예측이 맞는 경우의 확률은 \((1-\alpha)\), \((1-\beta)\)이고 그렇지 않은 확률은 \(\alpha\), \(\beta\)다. 이다. 이때, false positive 의 비율을 \(\alpha\)라고 하자. 이를 통계학에서는 1종 오류라고 한다. 반대로 false negative의 비율 \(\beta\)를 2종 오류라고 부른다.
통계적인 검정은 영 가설2을 통해 이루어진다. 영 가설을 통해 유의도를 검정하는 통계학적인 절차를 영 가설 검정(Null Hypothesis Significance Test: NHST)라고 부른다. NHST에서 영 가설은 대체로 등호의 형태로 표현된다. 예를 들어, 어떤 회귀식의 한 계수가 \(\beta_1 = 0\) 임을 검증하는 것이 일반적인 NHST다. 해당 영 가설이 맞다고 할 때 현재와 같은 결과를 얻을 확률이 p-value이므로, 이 값이 일정한 임계치(대체로 1%, 5%를 많이 쓴다)보다 낮을 때(\(p < 0.05\)) 영 가설을 기각하게 된다. 앞으로 영 가설은 \(H_0\)로, 영 가설 검정은 NHST 적도록 하자.

NHST 무엇이 문제인가? (기초편)
NHST가 지닌 문제를 제대로 다루려면 별도의 포스팅을 몇 차례는 해야 할 것이다. 일단 흔하게 저지르기 쉬운 기초적인 오류 하나 짚고 p−해킹으로 넘어가도록 하자.
통계 패키지를 돌릴렸을 때 \(p < 0.05\)와 같은 메시지가 뜨 안도한다. 이때 마음 속에서 이런 목소리가 들린다. “주어진 데이터에서 \(H_0\) 참일 확률 \(p\)…” 이 목소리에 솔깃했다면 정신을 차려야 한다 여기서 \(p\) 값의 의미는 오히려 역(reverse) 명제에 가깝다.
- 현재의 데이터가 주어졌을 때, \(H_0\)가 참일 확률
- 만일 \(H_0\) 참이라면, 현재의 데이터를 얻을 확률
1과 2는 같은 말인가? 고등학교 때 배운 명제를 떠올려보자. 원래 명제와 역 명제의 진리표 결과는 항상 등치가 아니다. 그런데 우리는 종종 \(p\) 값을 은근슬쩍 1처럼 해석하고 사용한다. 이해를 돕기 위해 법의 맥락에서 다른 사례를 들어보겠다.
- \(x\) 라는 증거가 발견되었을 때, 피고가 범인일 확률
- 피고가 범인일 때, \(x\) 라는 증거를 얻을 확률
이 두 주장이은 진술인가? 아니다! 심지어 2는 무죄추정의 원칙이라는 형법의 기본 원리와 충돌한다. 그리고 증거에 근거를 두고 피고의 유무죄를 판단할 때 1이 2보다는 타당하고 정의로운 접근이 아닐까? 그런데 사실 현실의 법정에서는 2를 1처럼 는 경우가 많다.3
NHST 무엇이 문제인가?
NHST는 \(\alpha\)의 임계치를 정해 놓고 구한 p 값이 이보다 작을 경우 영 가설을 기각하는 방식의 절차다. NHST가 \(\alpha\)를 고려하는 절차라면, \(\beta\)는 신경을 쓰지 않아도 되나? 즉, 2종 오류(\(\beta\)) 제대로 통제되지 않아도 괜찮은 것일까?
\((1-\beta)\)를 검정력(power)라고 부른다. 즉 대립 가설(alternative hypothesis)이 사실일 때 이를 사실로 예측할 확률을 의미한다. 사실 NHST는 상당히 높은 수준의 검정력을 암묵적으로 전제한다. 하지만 이 전제가 성립하지 않는다면 혹은 이 문제에 관해서 의도적으로 침묵한다면 어떤 일이 생길까?
영 가설 vs 대립 가설
눈치가 빠른 분이라면 뭔가 찜찜한 느낌이 들었을 것이다. 앞서 어떤 현상이 존재하는 경우와 그렇지 않은 경우를 대문자 TRUE, FALSE로 구분했다. 이를 영 가설, 대립 가설과 어떻게 매핑해야 할까? 사실 그때 그때, 문제에 맞게 정의하는 게 맞다. 중요한 것은 두 사건이 상호 배태적(mutually exclusive)이어야 한다는 것이다. 즉, 둘이 겹치는 영역이 없어야 한다. 그래야 가설 검정으로서 의미를 지닌다. 여기서는,
- TRUE = 대립 가설이 존재하는 경우
- FALSE = 영 가설이 존재하는 경우
이렇게 둔다면, false positive의 확률 \(\alpha\) 는 “영 가설이 참인데 이를 기각할 확률”이 된다. 우리가 아는 그 유의수준 그대로다. 혼동하지 마시라!(, 라고 하지만 나도 종종 긴가민가한다…)
Ioannidis, the destroyer
이제 하버드 의대에 재직하는 이오니디스(John P. A. Ioannidis) 선생을 소개해야겠다. 사실 많은 전문가들이 부지불식간에 p−해킹을 저지르고 혹은 써먹고 있었지만, 이에 대해서 정식으로 반성하는 경우는 드물었다. 대부분이 알고 있었고 찜찜하게 생각하고 있었지만, 문제로 삼기에는 (기둥 뿌리 무너질까) 망설여 지는 그런 것이 p−해킹이 아니었을까.
이것이 ‘우상’이다. 명확한 근거를 제시할 수 없지만 숭배의 유혹을 뿌리치지 쉽지 않은 것 말이다.
2005년 이오니디스 선생이 우상 파괴를 위한 폭탄 하나를 투하했다. 일단 제목부터 도발적이다. “왜 대부분의 출판된 학술 연구의 발견이 가짜인가?” 헐! 논문이 나온 뒤 현재까지 이 논문에 관한 갑론을박이 진행중이다. 좌우간 p−해킹 만큼은 이 논문이 제대로 핵심을 보여주었다. 여기서는 다른 분이 보다 이해하기 좋게 도해한 내용을 소개한다.
인간은 ‘가시성’의 동물이다. 사람들은 보통 평범한 것보다는 튀는 걸 먼저 보려 하고, 특이하고 드러나는 걸 좋아한다. “뭘 당연한 걸 연구 씩이나 하나!” 연구자들이 종종 듣게 되는 이야기다. 과학하는 사람들도 인간이다. 그들 역시 가급적 세상을 놀라게 할 특이한 결과를 찾아 헤맨다.
이렇게 가정해보자. 어떤 과학 실험을 1,000 번 할 때(보다 정확하게 표현하면 가설검정을 1,000 번 수행할 때), 그중에서 약 10%에서 신박한 결과가 나타난다고 하자. 그림으로 표시하면 아래와 같다.

이제 업계의 관행대로 1종 오류를 5%로 두자(\(\alpha = 0.05\)). 이는 false positive의 비율, 즉 영 가설이 맞는데 이를 기각할 확률을 5%까지 허용한다는 뜻이다. 1,000 번 실험을 했다면, 효과가 없는 900 번 중에서 약 45 번(= 900 X 0.05)이 효과가 있는 것으로 보고될 것이다. 아래 그림의 붉은 색에 해당한다.

보통의 \(\beta\), 즉 2종 오류는 명시적으로 표기되지 않는다. 대략 업계의 관행이 20% 라고 하자. 즉, false negative를 허용하는 비율, 즉 영 가설로 예측했으나 대립 가설이 맞는 100 개 중에서 20 개(= 100 X 0.2) 정도가 된다. 이를 역시 그림으로 표시해보자. 아래 그림에서 녹색에 해당한다. 이제 혼동 행렬에서 모든 경우를 다 표기했음을 확인해두자.
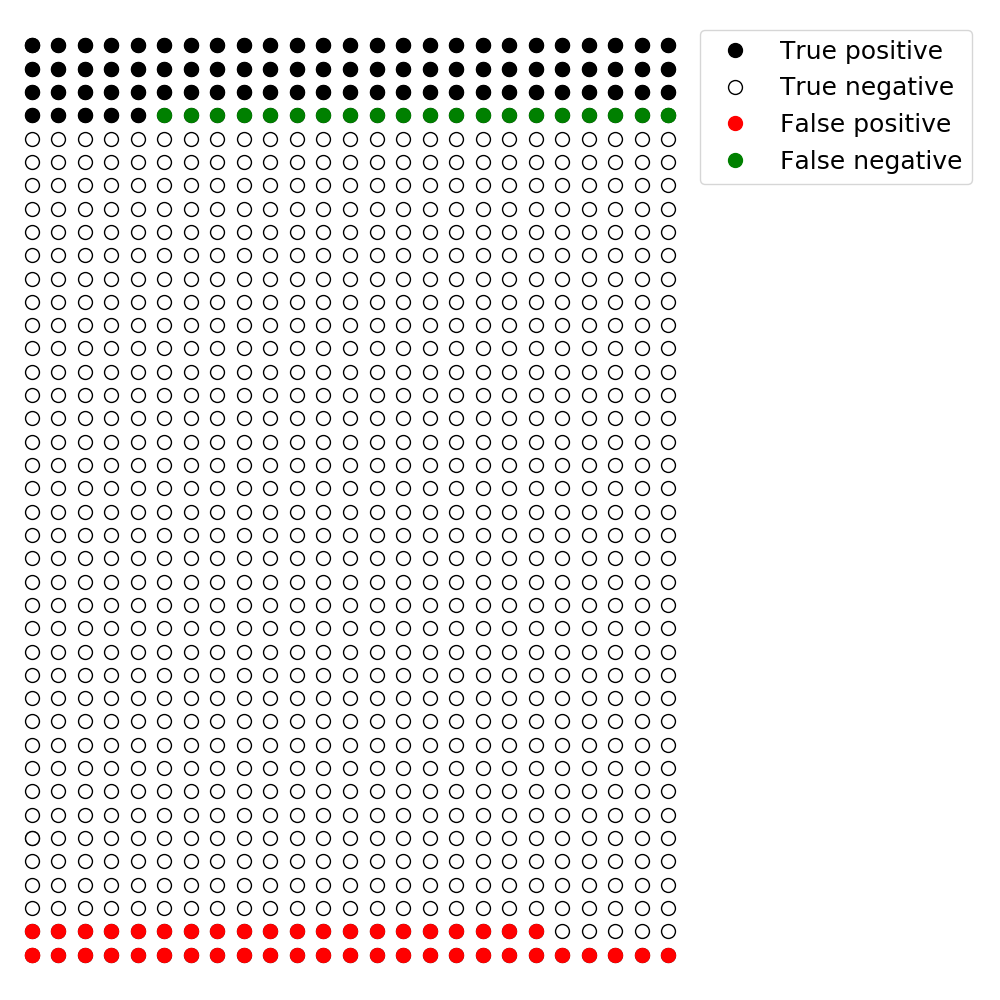
이오니디스의 일침
1,000 번의 노가다가 끝났다. 이오니디스의 제안은 간단하다. 제대로 했는지 알고 싶다면 positive라고 판정한 것 중에서 문제가 있는 경우의 비율(False Positive Report Probability)이 얼마나 되는지 계산해보라. 기계 학습을 배운 분들이라면 precision이라는 지표를 1에서 뺀 값과 동일하다.
\[\begin{aligned} \text{FPRP} &= \dfrac{\text{false positive}}{\text{false positive + true positive}} \\ &= \dfrac{\alpha N_F}{\alpha N_F + (1-\beta) N_T} \end{aligned}\]위 식에서 \(N_F\)는 FALSE에 속하는 숫자, \(N_T\)는 TRUE에 속하는 숫자를 각각 의미한다. 앞서 예시했던 문제를 계산해보자.
\[\text{FPRP} = \dfrac{900 \times 0.05}{900 \times 0.05 + 100 \times (1-0.2) } = \dfrac{45}{45 + 80} = 0.36\]생각보다 높다! 유의수준, 즉 \(\alpha\) 5%가 제법 안전해 보였을지 모르겠다. 이렇게 살짝 들춰보면 연구에 찜찜한 결함이 보인다. 사실 이 문제는 더 나빠질 수도 있다!
- 보통 \((1-\beta)\)는 0.8 정도라고 간주한다. 하지만 이를 엄밀하게 확인하는 경우는 많지 않다. 만일 검정력이 별로 높지 않아서 0.2에 불과하다고 해보자. 이때 false negative가 true positive의 숫자를 잡아먹게 되고, 이에 FPRP는 0.69로 올라간다. 즉,
- 조금 더 가볼까? 현상이 TRUE인 경우가 몹시 드물다고 해보자. 99%가 FALSE이고 1% 정도만 TRUE라면? 이 경우 \(\beta = 0.6\), \(\alpha = 0.05\)가정할 FPRP는 무려 0.93이 된다. 이오니디스 선생의 주장대로 대부분의 연구가 가짜 연구가 된다! 즉,
앞서 과학자들도 사람인지라서 신기한 것을 추구한다고 말했다. 신기한 것은 관찰되거나 검증되기 힘들다. 해당 가설을 검정한다면 대부분 negative로 예측될 것이다. 어찌어째해서 positive를 발견했다면 “유레카!”를 외치고 싶을 것이다. 이오니디스 선생은 우쭐하고 감탄하기에 앞서 의심이 먼저다, 라는 간단한 말씀을 하고 계실 뿐이다.
정리
이오니디스 선생은 엄밀하게 진행된 것처럼 보이고 불순한 의도 없이 진행된 통계적 연구조차도 상당히 높은 FPRP를 지닐 수 있음을 지적했다. 2종 오류를 명확하게 고려하지 않을 경우 신박함을 좇는 과학자의 자연스러운 ‘욕망’과 결합해 아주 나쁜 결과를 초래할 수 있다. 과학자는 ‘객관적 진실’을 추구하지만 연구 과정 및 보고 과정까지 객관적이기는 어렵다. 여기에는 과학자의 욕망이 개입하고 이에 따라서 보다 눈에 띄는 신박한 연구를 추구하려는 유인이 자연스럽게 생겨나기 마련이다.
이런 면에서 이오니디스 선생은 충고는 상식적이다. 보기 힘든 신박한 것을 발견했다면 의심부터 하라. 과학을 회의하라는 것이 아니다. 과학의 권위를 거부할 필요까지 없다. 과학자의 ‘유인incentive’을 의심해보라는 것이다. 과학이 행해지는 인간적 맥락을 살피라는 것이다. p−해킹이 출세욕에 사로 잡힌 과학자의 의도적 왜곡에서 비롯할 수도 있다. 하지만 과학을 향한 ‘순수한’ 열정의 원하지 않은 산물일지도 모른다.
자연과학이나 공학이 이렇다면 사회과학은 오죽할까. 입수한 자료를 이렇게 저렇게 비틀고 고문해서 원하는 결론으로 이끄는 일이 그리 어렵지는 않을 터… 그렇다면, p−해킹을 최대한 막을 수 있는 방책은 무엇일까? 이는 다음 기회에 다시 이야기하도록 하자.
p.s. 아마도 p−해킹에 관한 가장 익살스러운 묘사일지 모를 켄달 먼로의 xkcd 만화를 감상하며 글을 접는다. 만화를 이해하실 수 있다면 이 글의 목적은 달성!

-
이를 한번 새겨두면 말을 외울 때 쓸모가 있다. 즉, true는 뒤에 따라오는 말이 맞는 것을 지칭한다. true positive, true negative는 positive, negative의 판단이 맞았다는 이야기다. false positive는 positive 판단이 틀렸다는 이야기다. 즉, 원래 FALSE인데 TRUE로 판정한 것이다. 따라서 “오탐”이다. false negative는 negative 판단이 틀렸다는 뜻이다. 즉, 원래 TRUE인데 FALSE로 판정한 것이고, “미탐”이다. ↩
-
보통 “귀무 가설”로 번역하지만 원어의 의미로 보면 영 가설이 더 타당할 듯 싶다. 이 글에서는 영 가설로 쓰도록 하자. ↩
-
이는 베이즈 정리와 관련된 내용이고 이 자체로 흥미로운 주제다. 일단은 여기까지만 하고 넘어가도록 하자. 개탄할 노릇이지만 미국 법정은 베이즈 정리에 입각한 증거의 확률적 평가를 용인하지 않고 있다. (자세한 내용은 여기를 참고하라.) ↩