의사결정 나무와 엔트로피
by DANBI
엔트로피?
문송한 사람들은 대체로 ‘이과’의 새로운 개념을 접하면 머리가 멍해진다. 글쓴이의 문과 상식으로 엔트로피는 ‘무질서도’ 된다. 열역학의 개념 말이다. 그런데 기계학습에서 이 녀석이 왜 나오지? 결론부터 말하면 배움이 짧았다. 엔트로피라는 개념을 놓고 물리학과 정보학 사이에 내밀한 교류가 있었더라. 제임스 글릭이 쓴 “인포메이션” 9장에 관련된 내용이 자세하게 소개되어 있으니 관심이 있으시다면 참고하시라. 간략하게 마음대로 요약해 보겠다.
“열역학 제2법칙”으로 알려진 내용에서 “엔트로피의 증가”는 통계적인 경향성이다. 즉 경향적으로 엔트로피가 증가한다. 만일 어떤 존재가 이 경향성을 파악할 수 있다면, 엔트로피의 증가를 막는 영구 운동도 가능할 것이다. 이런 스마트한 존재를 맥스웰은 ‘도깨비’라고 불렀다. 그리고 이것이 인류 영원의 미몽인 “영구기관”의 추구를 낳기도 했다고.
좋다. 일단 그런 깜찍한 도깨비가 있다고 치자. 이 도깨비는 어떻게 정보를 얻게 되는가? 도깨비라면 0에 가까운 비용으로 이런 정보를 얻을 수 있겠지만 그런 도깨비는 어디에도 없다. 물질의 상태에 관한 정보를 얻기 위해서는 그에 상응하는 댓가를 치러야 한다. 도깨비가 정보를 알게 되면 알게 될수록 (도깨비가 없는 세상에서) 엔트로피가 높아진다. 즉, 정보가 생기면 엔트로피의 증가로 값을 치르게 된다.
어쨌든 정보학의 창시자 끌로드 섀넌(Claude Shannon)이 여기에 주목했다. 어떤 정보의 상태가 불확실하다고 할 때, 이를 파악하기 위해서는 더 많은 작업이 필요하다. 만일 상태가 전보다 덜 불확실하다면, 파악에 필요한 작업이 줄어들 것이다. 정보의 상태 혹은 품질을 측정하는 데 엔트로피를 쓸 수 있지 않을까? 잡음은 적고 시그널은 많은 정보일수록 엔트로피는 낮을 터다. 밑천이 드러나기 전에 여기까지만 해두자.
엔트로피를 정의하기 위한 요소
의외성(surprisal)
제임스 글릭의 책에서 surpirsal을 “의외성”으로 번역했으므로 우리도 일단 따르도록 하자. 의외성이란 어떤 사건이 주는 놀라움의 정도다. 월드컵 축구에서 한국이 독일을 이길 확률은 높지 않다. 이런 사건이 발생했다면, 이는 의외성의 수준이 높은 사건이다.
유한한 전체 사건의 인덱스(고유 번호)를 \(1, \dotsc, n\)이라고 하자. 이때 사건 \(i\)가 발생할 확률이 \(p_i\)다. 이때 이런 \(p_i\)가 지니는 의외성 \(s\)를 다음과 같이 정의하자.
\[s = -\log p_i\]로그의 밑수는 어떤 것을 써도 되지만 디지털 정보가 이진수인 관계로 계산의 편의를 위해 대체로 2를 많이 쓴다. \(p_i\)가 낮을수록 높을 값을 지니게 되기 때문에 앞에 마이너스를 붙였다고 생각해도 좋다. 아니면, \(p_i\)가 0과 1사이의 값이기 때문에 log의 값이 마이너스가 되고 마이너스를 붙여서 취지를 따르면서 양수를 만들었다고 생각해도 좋겠다.
Entropy
우리가 엔트로피를 통해 수량으로 요약하고 싶은 정보는 개별 사건이 아니라 사건 전체 아우르는 현재의 불확실한 상태다. 따라서 앞서 정의한 개별 사건의 의외성을 전체를 대표하는 값으로 바꿔야 한다. 쉽다. 기댓값을 구하면 된다. 앞서 정의한 \(s\)가 확률 변수이기 때문에 기댓값을 다음과 같이 쉽게 정의할 수 있다. 이 기댓값이 다름 아닌 정보의 엔트로피다.
\[e = - \sum_{i=0}^{n} p_i \log p_i\]Cross entropy
이제 교차 엔트로피의 개념을 살펴보자. 섀넌이 정의한 크로스 엔트로피는 다음과 같다. 동일한 배후 사건들에 관해서 두 개의 확률 분포를 \(p\), \(q\)라고 하자. 이때 \(p\)를 편의상 배후 사건들에 관한 참 확률 분포라고 하고 \(q\)를 이에 대한 추정치라고 하자. \(p\), \(q\)가 이산 확률 분포라면 교차 엔트로피는 다음과 같이 정의한다.
\[H(p, q) = -\sum_{i=0}^n p_i \log q_i\]\(q\)는 \(p\)의 추정치이므로 직관적으로 (그리고 수학적으로) \(H(p,q) \geq H(p,p) = e\)가 성립한다. 이를 눈으로 직접 확인해보고 싶다면 LINK를 참고하시라.
교차 엔트로피 무엇을 뜻할까? Kraft-McMillan 정리에 따르면, 교차 엔트로피는 원래 자료가 생성된 분포가 \(p\)이고 이에 관한 불완전한 추정 분포 \(q\)가 있을 때, 개별 실현값을 맞추기 위해 필요한 질문 수의 기댓값이다. 즉, \(p_x\)에 대한 추정치 \(q_x\)로 \(p_x\)를 맞출 때까지 소모해야 하는 정보의 크기다. 답을 맞출 때까지 진행하는 스무고개를 떠올리면 되겠다. 연습 삼아서, 예/아니오로 구별되는 이진 분류의 교차 엔트로피를 적어보자. “아니오”가 될 확률은 “예”일 확률을 1에서 뺀 값이므로 결국 필요한 값은 \(p_0\), \(q_0\) 두 개이다.
\[\begin{aligned} H(p,q) = & - \sum_{i=0}^1 p_i \log (q_i) \\ = & -( p_0 \log q_0 + p_1 \log q_1 ) \\ = & -\left( p_0 \log q_0 + (1-p_0) \log (1-q_0 ) \right) \end{aligned}\]의사결정 나무에서 어떻게 활용되는가?
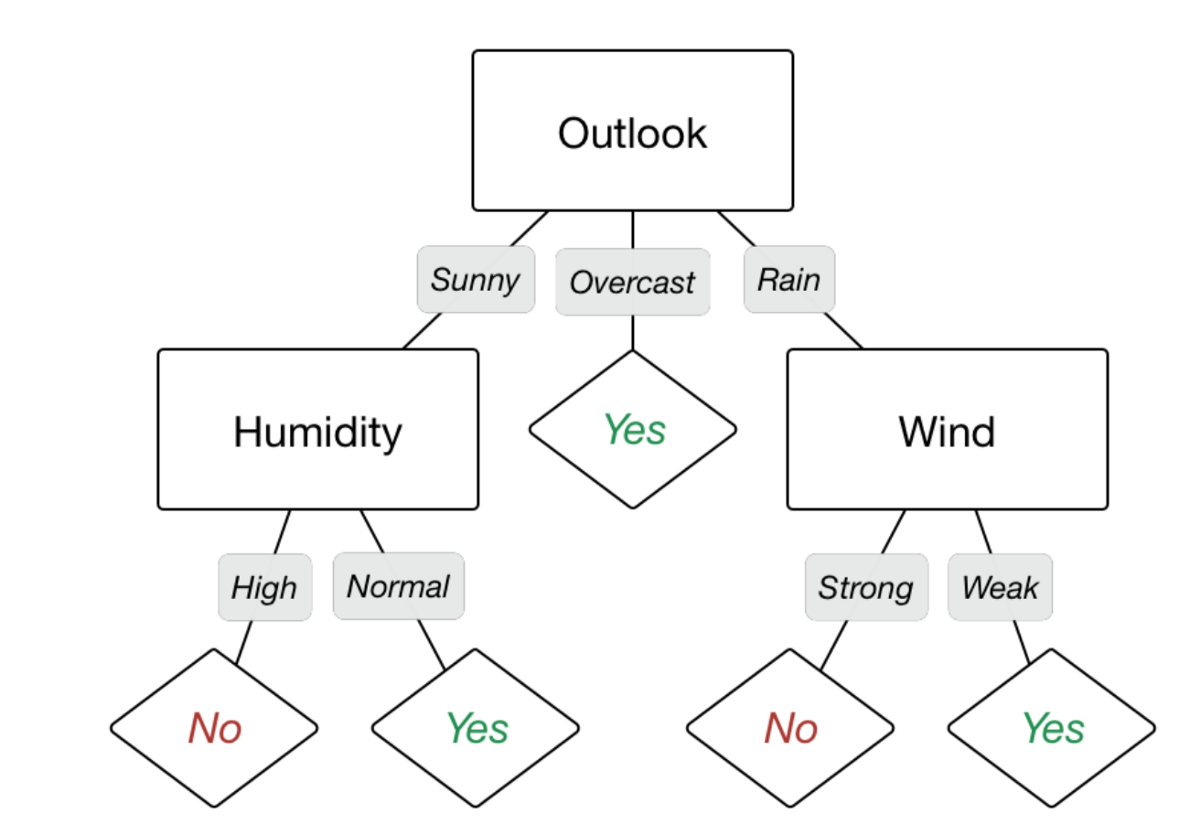
앞서 보았듯이 섀넌은 물리학의 엔트로피 개념을 가져와 정보에 관한 일종의 품질 지표를 만들다. 섀넌의 엔트로피가 가장 잘 활용된 사례가 바로 의사결정 나무(decision tree)다. 이른바 의사결정 나무(decision tree)란 판단을 해야 하는 어떤 분기에서 어떤 기준 혹은 속성으로 자료를 나누는 것을 의미한다. 의사결정 나무라는 게 결국 위에서 내려오면서 스무고개를 묻는 셈이고, 섀넌의 엔트로피 개념과 잘 맞는다.
무엇을 기준으로 나무의 가지를 나눌까? 나무의 결정 지점(노드)에서 가지를 나누는 기준으로 엔트로피를 활용하면 좋지 않을까? 특정 피쳐의 결정지점이 지닌 정보 이득(information gain)을 정의해보면 아래와 같다.
\[IG(S, F) = e(S) - \sum_{f \in F} \dfrac{|S_f|}{|S|} e(S_f)\]- \(S\): 전체 사건의 집합
- \(F\): feature, \(f\): feature 속성
- \(S_f\): \(f\) 속성을 지닌 사건의 집합
- \(\lvert X \rvert\): 집합 X의 크기 (원소의 갯수)
- \(e(X)\): X라는 사건 집합이 지닌 엔트로피
식이 좀 복잡해 보이지만 취지는 간단하다. 마이너스 뒤의 합의 의미는 이렇다. 어떤 속성에 기반해 결정 지점을 나눈다고 할 때, 그 결정 지점에 도달할 무작위 확률에 그 집합이 지닌 엔트로피를 곱한 값을 해당 속성에 대해서 전부 더해준 값이다. 현재 아무런 feature도 활용하지 않은 상태의 엔트로피에서 feature가 지닌 속성들을 통해 통해 분류를 한번 거쳤을 때의 엔트로피를 뺀다. 분류를 거친다는 것은 질문을 추가적으로 하는 것과 같다. 이런 정보를 획득함에 따라서 전체의 엔트로피는 적어도 늘어나지는 않을 것이다. 둘 사이의 차이를 해당 feature가 지닌 정보 품질(혹은 엔트로피 감소의 기여분)로 이해할 수 있겠다.
아래의 사례로 위의 식을 다시 이해해보자.
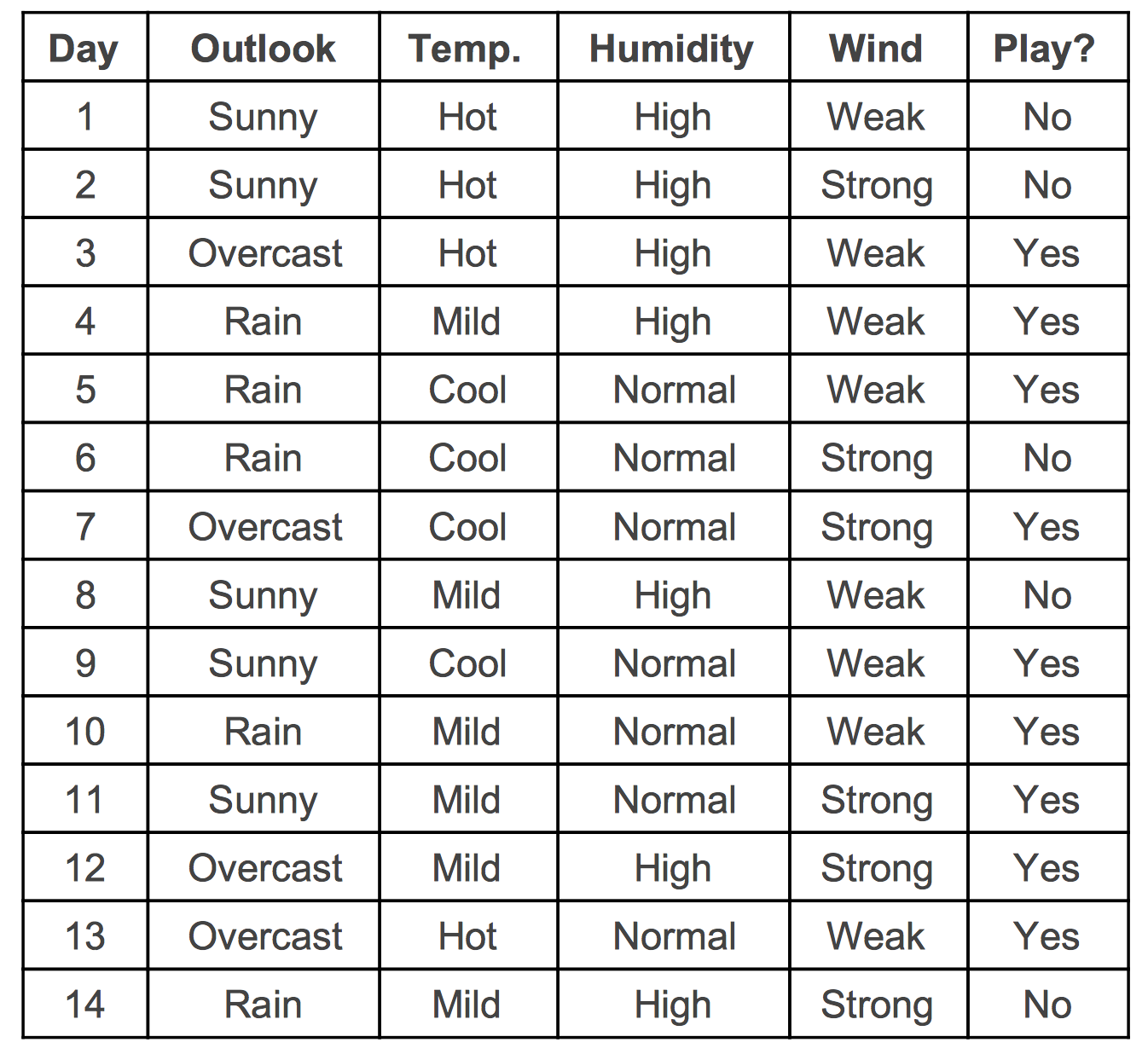
위와 같은 학습 자료가 주어졌다고 하자. 예측하고 싶은 목표 대상은 테니스는 칠 것인지 말 것인지의 여부(PLAY?)다. Feature 통한 분류를 거치지 않았을 때 학습 자료 전체의 엔트로피는 다음과 같다. 전체에서 플레이를 한 횟수는 9번 하지 않은 횟수는 5번이다. 즉.
\[S \equiv \left\{ \text{No, No, Yes, Yes, Yes, , No, Yes, , No, Yes, Yes, Yes, Yes, Yes, No} \right\}\]전체집합 \(S\)의 엔트로피는 다음과 같다.
\[e(S) = -(\dfrac{9}{14} \log_2 \frac{9}{14} + \dfrac{5}{14} \log_2 \frac{5}{14} ) = 0.94\]이제 위의 자료에서 주어진 feature를 활용해서 IG를 구해보도록 하자. 여기서는 참고로 Outlook(날씨)라는 하나의 feature에 대해서 계산하도록 하겠다. 나머지 feature에 대해서는 각자 연습해보시기 바란다. Outlook(날씨) feature가 지닌 속성은 “Sunny”, “Overcast”, “Rain” 세 가지다. 아래의 식에서 Outlook은 Sunny, Overcast, Rain을 원소로 하는 집합의 의미로 사용한다. 이 각각의 속성에 대한 \(e(S_f)\)는 다음 같다.
\[\begin{aligned} e(S_{\text{Sunny}}) &= -( \dfrac{2}{5} \log_2 \dfrac{2}{5} + \dfrac{3}{5} \log_2 \dfrac{3}{5}) \\ e(S_{\text{Overcast}}) & = 0 \\ e((S_{\text{Rain}}) & = -( \dfrac{3}{5} \log_2 \dfrac{3}{5} + \dfrac{2}{5} \log_2 \dfrac{2}{5}) \end{aligned}\]따라서,
\[\sum_{f \in \text{Overlook}} \dfrac{|S_f|}{|S|} e(S_f) = \dfrac{5}{14} e(S_{\text{Sunny}}) + \dfrac{4}{14} e(S_{\text{Overcast}}) + \dfrac{5}{14} e(S_{\text{Rain}})\]이렇게 각 4개의 feature에 대해서 IG을 구하면 어떤 feature가 엔트로피를 더 낮추는지 비교할 수 있다. 계산을 해보면 Outlook이 제일 높은 IG를 지니고 있다. 따라서 Outlook이 의사결정 나무에서 가장 상단에 위치하게 된다. 이제 1차 분류를 거친 후 각각 분류된 하위 집합에 대해서 같은 방식의 분류를 반복한다. 분류는 더 이상 분류될 것이 없을 때까지, 즉 주어진 집합의 엔트로피가 0이 될 때까지 반복한다.
엔트로피가 0이 된다는 것은 무슨 뜻일까? 해당 분류에 속하는 개체의 속성이 모두 동일하다는 뜻이다. 앞서 Outlook이라는 feature에서 Overacast는 엔트로피가 0이었다. 그래서 이 결정 지점에 도달하면 엔트로피를 낮추기 위한 더 이상의 분류가 필요하지 않다. 아래 의사결정 나무에서 보듯이 나무의 최종 결정 지점에 속한 개체들의 목표 결정 사항은 모두 동일하다.