
인과관계를 찾아서 3: 도구변수
by DANBI
오랜 만에 시리즈의 세번째로 찾아 뵙게 되었다. 앞으로 비교적 정기적인 주기의 연재를 약속하기 싶지만 인생이란 사실 뜻대로 되는 것이 없지 않은가? 지난 번 두 시리즈의 내용을 두 꼭지로 요약해보자.
- 인과관계를 알기 위해서는 자연과학에서 하는 것과 유사한 ‘실험’을 할 수 있어야 한다. 최소한 ATE(Average Treatment Effect)를 확인해야 ‘인과관계’를 논할 수 있다.
- 하지만 대부분의 사회과학(혹은 사회적) 세팅에서는 실험이 불가능하다.
그렇다고 손 놓고 있다면 과학자가 아니겠지. 그간 30 여년에 걸쳐서 사회과학자, 통계학자, 경제학자들은 실험이 불가능한 상황에서 실험에 준하는 상황 혹은 장치를 고안해내기 위해서 애썼다. 이제 그 이야기를 하나씩 풀어보자.
인과관계를 나타내는 OLS
오늘 논할 내용은 도구 변수(Instrumental variable)다. 먼저 도구 변수가 왜 등장했는지 살펴보자. OLS(Ordinary Least Squares 즉, 표준 회귀분석)의 상황을 다들 잘 아시리라고 가정하겠다. 몰라도 괜찮다. OLS를 떠받치는 몇 개의 기둥이 있는데 그중 실용적으로 가장 중요한 것이 일치성(consistency)다. 쉽게 말해서 OLS를 통해 도출된 추정량이 있을 때 샘플사이즈가 커지면서 이 값이 참 값으로 접근한다는 것이다. 일치성이 충족되면 우리는 적당하게 큰 표본에 대해서 추정치가 좋은 속성을 지니고 있다고 말할 수 있다.
그렇다면, 이 일치성을 만족시키는 조건은 무엇인가? 수학적인 정의를 풀어 말하면, 회귀분석의 독립변수 혹은 regressor가 에러와 상관성이 없어야 한다. 이 조건이 깨지만 일치성이 깨진다. 일치성이 결여된 추정량은 쓰임새가 몹시 제한적이다. 그림에서 보듯이 오차항은 말 그대로 우연한 오차로서 종속변수 혹은 regressand에 영향을 주어야 한다는 것이다.
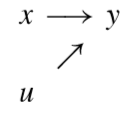
이것이 성립한다면 우리는 OLS에서도 인과관계를 주장할 수 있다! 흔히 학교에서 회귀분석과 인관관계는 별 개의 것이라고 가르치곤 한다. 그런데 조심스럽게 이 주장을 받아들였으면 한다. 교과서에서 배우는 표준적인 OLS의 조건이 성립한다면, OLS를 그대로 인과관계로 이해하도 된다. 즉, \(x\)가 \(y\)의 원인이다!
인과관계를 나타낼 수 없는 OLS
여기가 끝이었다면 삶도 단순해지고 모두 행복했을 것이다. 현실의 데이터가 위 그림과 같은 조건을 어느 정도라도 충족시키는 경우가 오히려 드물다. 즉, 아래의 그림이 일반적이다.
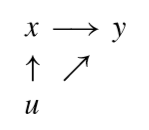
오차항이 독립 변수와 종속 변수에 모두 영향을 주는 경우는 어떤 경우일까? 가장 쉽게 떠올릴 수 있는 경우는 변수가 생략된 경우다. ‘도구 변수’ 연구에 중요한 계기를 이룬 분야가 교육 경제학이다. “교육 수준이 임금에 반영되는가?” 즉, 교육 연수가 높을수록 임금이 높을까, 라는 질문이었다. 뭘 당연한 걸 묻느냐고 생각할지 모르겠지만 이 질문을 데이터로 확인하기는 쉽지 않다. 왜 그럴까? 위 그림을 다시 한번 보자. \(y\)가 임금이고 \(x\)는 교육 수준을 대리하는 교육년수라고 하자. \(x\), \(y\)에 동시에 영향을 미칠 수 있는 \(u\)에 속할 수 있는 것은? 바로 떠오르는 것이 ‘개인의 능력’이다. 능력이 좋은 사람이 높은 임금도 받고 시험도 잘봐서 교육년수도 높을 수 있다.
우리는 교육년수의 ‘외생적인’ 변화가 임금에 미치는 영향에 관심이 있다. 즉, 다른 조건이 동일할 때, 교육년수만 변화시키면서 임금의 변화를 보고 싶은 것이다. 이 목적에 맞게 실험을 설계하면 이 변화를 알 수 있다. 능력치가 비슷한 사람들을 비슷한 조건에서 양육하면서 교육년수만 달리하면 된다. 계속 이야기하지만 이런 실험이 불가능하다.
어떻게 하면 좋을까? 앞서 첫번째 그림에서 봤던 것처럼 \(u\)과 \(x\)의 고리를 끊는 것이 핵심이다. 여기서 도구 변수가 등장한다.
도구 변수
도구 변수는 말 그대로 도구 혹은 수단으로 이해하면 쉽다. \(x\)와 \(u\)의 고리를 끊는 수단이다. 어떤 변수가 이런 역할을 할 수 있을까? 도구 변수로 기능하기 위해서는 두 가지 조건을 만족해야 한다.
- 도구 변수 \(z\)는 \(x\)와 충분한 상관성을 지녀야 한다.
- 도구 변수 \(z\)는 \(u\)와 상관성이 충분히 낮아야 한다.
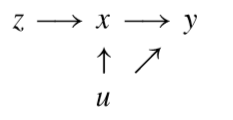
그림을 보며 말로 다시 풀어보자. \(x\)는 관찰되지 않은 독립 변수 혹은 여타의 이유 때문에 \(u\)에 휘둘릴 수 있다. 우리가 제거하고자 하는 교란 요인과 관계가 없다고 믿을 수 있는 변수 \(z\)를 찾고 이 녀석이 \(x\)를 움직이는 것이 얼마나 \(y\)를 변화시키는지를 대신 보겠다는 것이다. 즉, 실험에 준하는 외생성을 확보하게 해주는 것이 도구변수다.
사례
앞서 논했던 교육의 사례는 도구 변수에 관한 연구에 획을 그었다. 계량경제학자 데이비드 카드(David Card)는 교육년수와 임금 간의 인과관계 추정의 난점을 돌파할 도구 변수로 학생들의 집에서 대학까지의 거리를 사용했다.1 이 변수는 앞서 제시한 1과 2를 모두 만족하는가? 우선 1부터 보자. 대학 진학률이 높지 않았던 미국임을 감안하면 지역 대학 혹은 주립 대학과 집의 거리는 대학 진학과 상관성을 지닌다. 다음으로 2를 살펴보자. 대학과 집에의 거리가 해당 학생의 장래 임금 수준과 연관성을 지니게 될까? “맹모삼천지교”가 일반적인 사회적 현상이라면 그렇겠지만, 그럴 가능성이 낮아 보인다.
미디어 경제학자인 매슈 겐츠코우(Matthew Gentzkow)의 연구 하나를 더 소개하겠다. 그는 미디어 업계의 오랜 질문 하나를 던졌다. 취학 전 TV 시청 시간과 취학 후 성적 사이에 어떤 관계가 있을까? 다시 말해, TV는 바보상자일까? 이것 역시 앞서 교육 문제와 비슷한 구조를 지니고 있다. TV 시청 시간과 성적 모두에 영향을 주는 공통의 잠재 요인이 있다면, 성적을 TV 시청 강도의 변수로 회귀하는 것은 적절하지 않다.2
성적에 영향을 주지 않으면서 TV 시청과는 연동된 어떤 도구 변수를 찾아보면 어떨까? 겐츠코우는 1948년부터 1952년 사이 텔레비전 방송국의 신규 면허가 동결되었던 사건에 주목했다. 미국에서는 2차 세계 대전을 전후한 1940–1950년 사이 TV의 보급이 빠르게 이루어졌고 TV 시청 가구도 빠르게 증가했다. 방송국 신규 면허가 중단되었던 저 기간 TV 방송국이 개국되지 못한 지역에 거주한 사람들은 TV를 볼 수 없었으므로 TV 구매를 미뤘다. 따라서 저 기간 동안 거주 가정이 TV를 보유했는지 여부를 나타내는 변수는 티비 방송시간과 높은 상관성이 존재할 것이다. 반면 이 기간 동안 TV 보유 여부가 아이들의 학력에 차별적인 영향을 주었을 가능성은 그리 높지 않다. (물론 겐츠코우 교수는 이 두 가지 대목에 관한 통계적인 증거를 제시했다.)
연구의 결과는 통념과는 반대된 것이었다. (사실 연구는 이런 결과를 제시할 때 더 주목받기 쉽다.) 이 시기 TV를 보면서 자란 아이들의 학력 테스트 표준 점수가 0.02 높았다. 아울러 숙제 하는 시간, 상급 학교 진학 여부에도 악영향을 주지 않았다. 연구에서 흥미로운 또 다른 부분이 있다. 영어가 모국어가 아니거나 어머니의 학력이 낮거나 백인이 아닌 다른 인종의 아이들의 경우 TV 시청의 학력 상승 효과가 두드러졌다. (“세서미 스트리트”를 떠올려보자!)
도구 변수 지옥?
도구 변수는 분명 매력적인 방법이다. 하지만 한계도 존재한다. 도구 변수를 통한 준실험적 상황의 창출이 크게 유행했을 무렵에는 도구 변수를 찾는 것이 연구의 모든 것처럼 비춰지던 때도 있었다. 좋은 도구 변수가 발견되고 이를 통해 인과 관계의 난제가 풀린다면, 이는 멋진 탐정 소설 한 편을 읽는 것 만큼이나 짜릿한 일이다. 하지만 뭐든 과하면 문제가 되는 법이다. 어떤 경우 도구 변수로 제시된 것이 지나치게 기발해서 이 것이 앞서 이야기했던 두 조건을 잘 만족시키는 것인지 의아하게 느껴지는 연구도 종종 제출되곤 했다. 도구 변수는 훌륭한 도구지만, 때로는 이 도구를 휘두르는 사람을 지옥에 빠뜨릴 수도 있는 요물이다.
부록
도구 변수 추정량 도출
도구 변수를 실제로 어떻게 추정하는지 간단하게 살펴보자. 약간의 수학이 동원된다. 아래와 같이 간단한 회귀분석을 생각해보자. 모든 값은 전부 스칼라(벡터나 행렬이 아닌 숫자)다.
\[y = \beta x + u(x)\]앞서 말로 살펴보았듯이, \(u(x)\)를 통해서 오차항이 \(x\)와 연관되어 있다는 점을 명시했다. 이제 \(y\)를 \(x\)에 대해서 미분해보자. 즉, OLS에서 하듯이 회귀 계수를 수학적으로 표현해보자는 것이다.
\[\dfrac{d y}{d x} = \beta + \underset{(*)}{\dfrac{d u}{d x}}\]우리가 알고 싶은 것은 \(x\)의 외생적인 변화에 따른 \(\beta\)인데, OLS 값을 구하면 \((*)\) 부분이 따라 붙는다. 이 부분이 바로 편향이 된다. 이 식의 기호와 크기에 따라서 OLS는 진실은 축소할 수도 있고 과장할 수도 있다.
이제 도구 변수 \(z\)를 활용하는 경우를 나타내보자.
\[\dfrac{d y}{d z} = \dfrac{dx}{d z} \dfrac{dy}{dx}\]미분의 연쇄법칙에 따르면 위와 같이 쉽게 나타낼 수 있다. 여기서 우리가 원하는 외생적인 변화는 다음과 같이 적을 수 있다.
\[\dfrac{d y}{d x} = \dfrac{\dfrac{d y}{d z}}{\dfrac{d x}{d z}}\]약간의 계산을 생략하고 기호도 살짝 도약해보자. OLS의 맥락에서 생각하면, 식의 분자는 \(y\)를 \(z\)로 회귀해서 얻는 벡터가 된다. 즉,
\[\dfrac{d y}{d z} = ({\mathbf z}'{\mathbf z})^{-1} {\mathbf z}'{\mathbf y}\]같은 방식으로 분모는
\[\dfrac{d x}{d z} = ({\mathbf z}'{\mathbf z})^{-1} {\mathbf z}'{\mathbf x}\]따라서 도구 변수를 활용한 추정량은 다음과 같다.
\[\hat {\bf \beta}_{\text IV} = \dfrac{ ({\mathbf z}'{\mathbf z})^{-1} {\mathbf z}'{\mathbf y} }{ ({\mathbf z}'{\mathbf z})^{-1} {\mathbf z}'{\mathbf x} } = ({\mathbf z}'{\mathbf x})^{-1} {\mathbf z}'{\mathbf y}\]Two-stage IV (2SLS)
보통 내생 변수–OLS에서 독립 변수로 활용되어야 하나 앞서 본 것처럼 u가 이 변수에도 영향을 끼치는 변수–가 \(r\) 개 있다고 할 때 이를 보정하기 위해서는 최소한 \(r\) 개의 도구 변수가 필요하다. 사실 위의 추정량을 이러한 가정 아래에서 도출했다. 만일 도구 변수의 갯수 \(K\)가 \(r\) 보다 큰 상황을 “과잉식별overidentified” 상태라고 한다. 즉, 동원할 수 있는 도구 변수가 여러 개 존재하는 상황이다. 이때 어떻게 추정하는 것이 좋을까? 이 경우 2단계 회귀를 활용할 수 있다. 이름이 뜻하는 것처럼,
- 먼저 \(\mathbf x\)를 \(\mathbf z\)로 회귀한 뒤 해당 추정치 \(\hat{\mathbf x}\)를 구한다.
- \(\mathbf x\) 대신 \(\hat{\mathbf x}\)로 \(\mathbf y\)를 회귀한다.
만일 도구 변수와 내생 변수의 수가 같다면, 두 추정량을 동일하다. 2SLS를 왜 쓸까? 보통 \(K > r\)인 상황이라면 \(K\) 중 일부를 버리면 된다. 하지만 이렇게 변수를 버리면 추정량의 분산이 커진다. 즉 효율성을 살리기 위해서 두 단계 회귀분석을 동원한다. $r=K$의 상황에서는 위에서 도출한 IV 추정량과 2SLS 추정량 사이에 큰 차이가 없다.
사실 대부분의 도구 변수 추정이 2SLS를 기본으로 활용하고, 대부분의 통계 소프트웨어들도 이렇게 동작한다. 이는 2SLS가 위에서 제시한 IV 추정량에 비해서 여러모로 ‘유연’하고 2SLS를 써서 밑질 것이 없기 때문이다. 2SLS를 말로 이해하면 다음과 같다. 일련의 regressor 벡터 \(\mathbf x\)가 내생성을 지닌 변수를 포함하고 있다면, 이를 통제하기 위해서 \(\mathbf z\)를 통해서 \(\mathbf x\) 추정치를 생성한다. 이렇게 내생성을 최대한 통제한 변수 \(\hat{\mathbf x}\) 를 \(\mathbf y\)를 추정하는 데 활용하는 것이다.
도구 변수 실제 분석 사례
LINK를 참고하시라.
참고한 책
Jorn-steffen Pischke, Joshua D. Angrist (2014), 고수들의 계량경제학, 시그마프레스.
-
David Card (1995), “Using Geographic Variation in College Proximity to Estimate the Return to Schooling,” in Aspects of Labour Market Behacio~lr: Essays in Honour of John Vanderkamp, ed, by Louis N. Christofides, E. Kenneth Grant, and Robert Swidinsky. Toronto: University of Toronto Press, 201-222. ↩
-
Matthew Gentzkow, Jesse M. Shapiro (2008). “Preschool Television Viewing and Adolescent Test Scores: Historical Evidence from the Coleman Study.” The Quarterly Journal of Economics, 123(1), 279–323. ↩