
회귀분석 이해하기 (기하편)
by DANBI
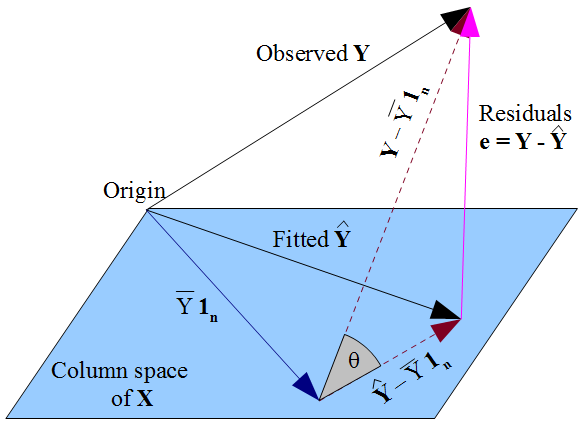
여기서 회귀분석을 해설할 생각은 없다. 이미 너무나 많은 그리고 매우 훌륭한 내용들이 책, 웹, 강의로 넘쳐날테니까. 이 글의 용도는 그림 하나로 지나치기 쉬운 회귀분석의 ‘핵심’을 살피는 것이다. crossvalidated에서 이 그림을 보는 순간 일종의 ‘돈오돈수’가 강림했다. (이렇게 이해하면 쉬웠을 것을…) 먼저 우리에게 익숙한 회귀분석 모델을 매트릭스로 적어보자.
\[\underset{n \times 1}{\phantom{\boldsymbol \gamma}\mathbf{Y}\phantom{\boldsymbol \gamma}} = \underset{n \times k}{\phantom{\boldsymbol \gamma} \mathbf{X} \phantom{\boldsymbol \gamma} }\underset{k \times 1}{\boldsymbol \beta} + \underset{n \times 1}{\phantom{\boldsymbol \beta} \boldsymbol \varepsilon \phantom{\boldsymbol \gamma} }\]식에 관한 자세한 설명 역시 생략한다. 대충 \(n\) 개의 관찰 수과 \(k\) 개의 regressor를 지닌 중회귀분석 모형이라고 생각하면 되겠다.1 앞서 본 그림은 보통 회귀분석의 예시로 많이 활용되는 아래 그림과는 다르다.
위 그림은 1개의 regressor가 존재할 때 이것과 regressand를 그대로 2차원 평면에 관찰 수만큼 찍은 것이다. 첫번째 그림에서 “Observed Y”는 \(n\) 개의 regressand를 모두 포괄한다. \(\mathbf{Y}\)는 \((n \times 1)\) 벡터, 즉 \(n\) 차원 벡터다. 이 벡터 하나가 회귀식 좌변의 관찰값 전체를 나타낸다.
이제 선형대수의 세계로 들어가보자. \(\mathbf X\)의 열(column)이 각각 \(n\) 개의 관찰 값을 지닌 regressor에 해당한다. 이 각각의 컬럼은 \((n \times 1)\) 벡터이다. 이 벡터 \(k\) 개가 생성할 수 있는 공간이 \(\mathbf X\)의 컬럼 스페이스다(앞으로 col \(\mathbf X\)로 표기하자).
col \(\mathbf X\)를 통해 생성되는 공간의 최대 차원, 즉 \(\mathbf X\)의 랭크는 무엇일까? 회귀분석에서는 대체로 \(n > k\)가 일반적이고 이런 상황에서 \(\mathbf X\)의 랭크는 \(k\)를 넘을 수 없다. 다시 말하면, \(\mathbf X\)가 생성하는(span)하는 컬럼 스페이스의 차원은 \(k\)를 넘을 수 없다.
그림에서 색칠된 평면이 \(\mathbf X\)가 생성하는 컬럼 스페이스, 즉 col \(\mathbf X\)를 표현하고 있다. 앞서 보았듯이 \(\mathbf Y\)는 \(n\) 차원 벡터다. 몹시 특별한 경우가 아니라면 \(\mathbf Y\) 벡터가 col \(\mathbf X\)에 속할 가능성은 없다. 만일 속해 있다면 회귀분석이 필요 없을 것이다. col \(\mathbf X\)를 통해서 \(\mathbf Y\)를 완벽하게 예측할 수 있는데 무슨 걱정이 있겠는가? 대체로 우리가 마주하는 상황은 \(n\) 차원 벡터를 \(k\) 차원 공간에 끼워 넣기 힘든 상황이다.
회귀분석의 목표는 regressor를 통해서 regressand를 ‘가장’ 잘 설명하는 것이다. 이를 기하를 통해 풀어보자. 회귀분석이란 regressand와 ‘닮은’ 것을 col \(\mathbf X\)에서 찾는 것이다. 즉 \(\mathbf Y\)와 닮은 무엇을 \(\mathbf X\)의 컬럼 스페이스에 찾아야 한다. 직관적으로 쉽게 떠올릴 수 있는 것은 이 평면과 \(\mathbf Y\)의 (유클리드) 거리를 가장 짧게 만들어주는 벡터일 것이다. 그리고 이 최단거리는 \(\mathbf Y\)에서 \(\mathbf X\) 컬럼 스페이스로 내린 수선의 발이 닿는 col \(\mathbf X\)의 지점이다. col \(\mathbf X\) 내에 있는 수선의 발 벡터를 찾는 연산자(operator)가 회귀분석 계수 \(\hat{ \boldsymbol \beta}\)이다. 즉,
\[\hat{\boldsymbol \beta} = ({\mathbf X}'{\mathbf X})^{-1} ({\mathbf X}' \mathbf Y)\]그리고 이 연산자를 regressor의 모음인 col \(\mathbf X\)에 적용하면 regressand \(\mathbf Y\)의 예측치 \(\hat{\mathbf Y}\)이 계산된다. 그림에서 보듯이 \(\hat{\mathbf Y}\)은 \(\mathbf Y\)와 \(\mathbf X\)의 컬럼 스페이스의 거리를 최소화하는 위치에 존재한다. \(\hat{\mathbf Y}\)는 어떤 벡터일까? \((n \times 1)\) 벡터지만 col \(\mathbf X\) 내에 위치하고 있다.
이제 이 그림을 머리에 넣고서 \(\mathrm R^2\)의 의미를 살펴보자. 결론부터 이야기하면 \(\mathrm R^2\)는 그림에서 \((\mathbf Y - \overline{\mathbf Y})\) 벡터와 \((\hat{\mathbf Y}-\overline{\mathbf Y})\) 벡터가 이루는 각의 코사인 값, 즉 \(\cos \theta\) 다. \(\overline{\mathbf Y}\)는 무엇일까? 그림에서처럼 \(\overline{Y} \mathbf{1}_n\)로 표기할 수 있다. 즉, \(\mathbf Y\)의 평균값 \(\overline{Y}\)만으로 구성된 \((n \times 1)\) 벡터다. 이 벡터는 col \(\mathbf X\) 안에 있을까? 당연히 그렇다. \(\mathbf X\)는 최대한 \(k(<n)\) 차원의 벡터이고, \(\overline{\mathbf Y}\)는 1차원 벡터다. 다시 본론으로 돌아가자. 이 코사인 값의 의미는 무엇일까?
그림에서 보듯이 세 개의 벡터가 직각삼각형을 이루고 있으므로 아래의 식이 성립한다.
\[\underset{\text{TSS}}{\Vert \mathbf Y - \overline{\mathbf Y} \Vert^2} = \underset{\text{RSS}}{\Vert \mathbf Y - \hat{\mathbf Y} \Vert^2} + \underset{\text{ESS}}{\Vert \hat{\mathbf Y} - \overline{\mathbf Y} \Vert^2}\]흔한 피타고라스의 정리다. 그런데 이것 어디서 많이 보던 식이다. 회귀분석 배우면 언제나 나오는 식이다. Regressand의 평균과 관찰의 이른바 총 제곱의 합(TSS: Total Sum of Squares)은 설명된 제곱의 합(ESS: Explained Sum of Squares)과 잔차 제곱의 합(RSS:Residual Sum of Squares)와 같다. 대체로 복잡하게 소개되는 이 식이 기하학적으로 보면 그냥 피타고라스의 공식에 불과한 것이다.
양변을 \(\Vert \mathbf Y - \overline{\mathbf Y} \Vert^2\)으로 나누면 다음과 같다.
\[1 = \dfrac{\Vert \mathbf Y - \hat{\mathbf Y} \Vert^2}{\Vert \mathbf Y - \overline{\mathbf Y} \Vert^2} + \dfrac{\Vert \hat{\mathbf Y} - \overline{\mathbf Y} \Vert^2}{\Vert \mathbf Y - \overline{\mathbf Y} \Vert^2}\]정의에 따라서 \(1 = \dfrac{\text{RSS}} {\text{TSS}} + {\mathrm R}^2\)가 된다. 즉,
\[{\mathrm R}^2 = 1 - \dfrac{\text{RSS}}{\text{TSS}}\]\(\textrm R^2\)는 가끔 회귀분석의 성과 지표로 남용되는 경우가 있다. 이렇게 기하학적으로 보면 col \(\mathbf X\) 내에 표현된 \(\hat{\mathbf Y}\) 가 \(\mathbf Y\)와 얼마나 가깝게 있는지를 \(\overline{\mathbf Y}\)를 기준으로 지표화한 것에 불과하다.
\({\mathrm R}^2\)는 회귀분석의 성과 지표로 어떤 의미가 있을까? 분석의 목표가 회귀분석을 통한 예측이라면, 즉 원래 관찰값과 예측된 값이 얼마나 떨어져 있는지 여부가 중요하다면 \(\textrm R^2\)는 의미를 지닐 수 있다. 반면, 분석의 목표가 회귀분석을 통한 이러한 종류의 예측이 아니라 특정한 regressor의 인과관계에 관한 추정이라면, \(\textrm R^2\)는 거의 무시해도 좋다.
아울러 회귀분석이라는 이름을 달고 있지만 전형적인 회귀분석의 방법을 따르지 않는 기법에서 \(\textrm R^2\)가 정의되지 않는 경우도 있다. 잘 알려진 로지스틱 회귀가 이에 해당한다. 로지스틱 회귀에서 회귀 계수의 추정은 여기서 봤듯이 관찰과 col \(\mathbf X\) 사이의 거리를 최소화하는 방식이 아니라 우도(likelihood)를 극대화하는 방식을 따른다. 따라서 벡터 공간의 피타고라스 정리를 따르는 \(\textrm R^2\)는 정의되지 않는다.2