
HR Analytics와 구조방정식
by DANBI
HR Analytics와 구조방정식
최근 HR Analytics, People Analytics에 대한 관심이 뜨겁다. 기존 조직과 구성원에 대한 문제들을 데이터 분석을 통해 확인하려는 시도가 주목을 받고 있다. HR Analytics는 다양한 분석 주제들을 가지고 있는데, 그 중에서도 ‘성과’, ‘역량’, ‘리더십’, ‘조직문화’ 등의 주제에 관심이 깊고, 관련된 연구나 분석 사례가 많이 소개되고 있다. 구체적인 가설을 생각해보면, ‘조직장의 리더십에 따라 구성원의 조직 몰입은 어떻게 변할까?’, ‘소속 조직 문화의 인식에 따라 구성원의 이직 의도는 어떻게 달라질까?’와 같은 질문들이 있다.
그런데 이러한 연구에서 사용되는 변수들은 모두 추상적인 개념들이다. 다시 말해서, 직접 관찰되거나 혹은 하나의 지표로 표현하기가 어렵다. 예를 들어, 연봉, 근무 연수, 직급, 성별 등은 명확하게 관찰되는 데 반해, ‘조직 몰입’. ‘직무 만족’, ‘이직 의도’는 그렇지 못하다. 이러한 문제를 해결하기 위해 검사, 설문 문항을 통해 데이터를 측정하고 변수 간의 관계를 확인하게 된다. 아래 문항은 국내 한 연구에서 구성원의 조직 몰입도를 측정하기 위해 활용한 문항이다.
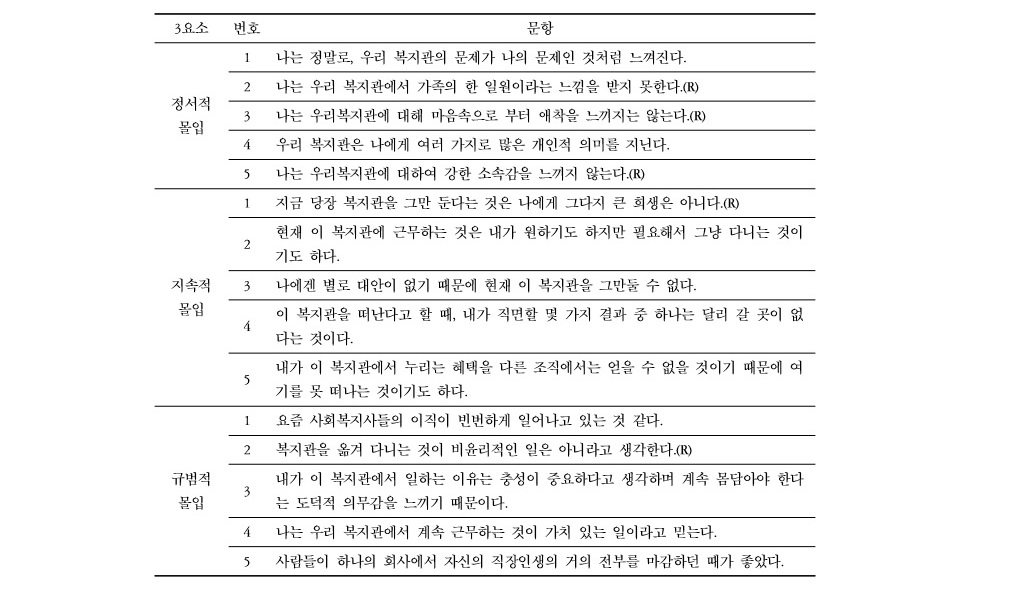
출처. 안정원, 이순묵(2015), 조직몰입 3요소 모형의 내적 구조 검토 : 탐색적 구조방정식 모형(ESEM)의 적용, 한국심리학회지: 산업 및 조직: Vol. 28(4), 795-827.
문항의 구성을 살펴보면, 조직몰입을 정서적 몰입, 지속적 몰입, 규범적 몰입이라는 하위 요인으로 나누고, 해당 요인을 측정하기 위한 문항을 각각 5개씩 사용하여 구성원의 조직 몰입을 측정하고자 하였다.
그런데 이런 식의 문항과 데이터는 HR Analytics라는 거창한 이름을 붙이지 않더라도 HR 현업에서 흔히 활용되고 있다. 구성원의 역량 평가 문항, 리더십 진단 문항, 조직문화 진단, 지원자의 역량 면접 평가표, 교육 만족도 설문 등이 보통 이러한 문항 형태를 활용하고 있다. 확인하려는 개념이 추상적이기 때문에 복수의 문항을 활용하는 것이다.
이렇게 추상적인 개념들을 측정하고, 그 개념 사이의 관계를 확인하려는 상황에서 적절하게 활용할 수 있는 분석 방법론을 이번 블로그에서 소개하고자 한다. 바로 심리학, 교육학과 같은 행동과학 연구에서 주로 활용되고 있는 구조방정식 모형(SEM : structural equation model)이다. 앞서 제안한 상황을 살펴보자. 두 가지의 분석 이슈가 있다. 먼저 추상적인 개념을 여러 문항을 통해 측정한다는 점과 이러한 개념 간의 관계를 확인하고자 한다는 점이다. 구조방정식은 이러한 상황을 측정모형과 구조모형을 결합하여 분석하는 방법을 취한다. 먼저 복수의 문항에서 우리가 관심을 가지고 있는 개념이 잘 측정되었는지를 측정모형을 통해 확인하고, 문항 간의 공통 분산을 활용하여 측정오차를 제거한다. 다음으로 측정오차가 제거된 개념들 사이의 회귀관계를 구조모형을 통해 밝히게 된다.
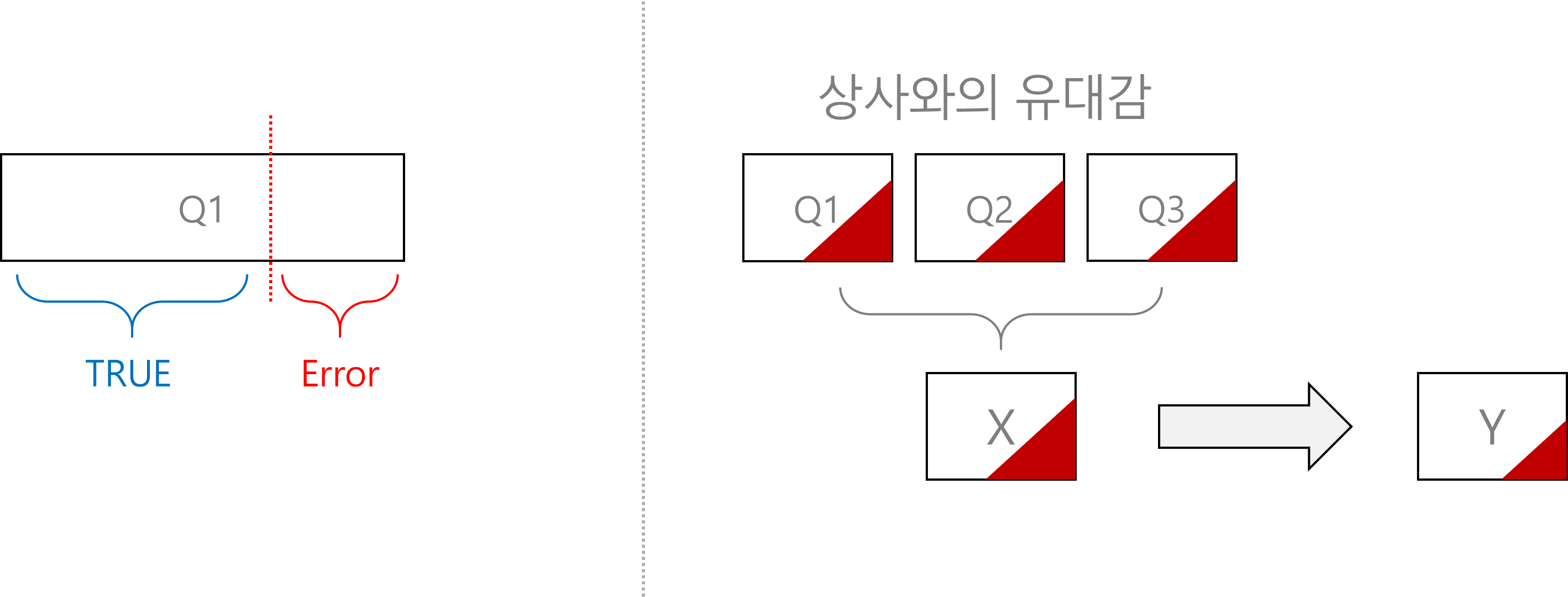
모형에 대한 보다 상세한 설명은 뒤에서 설명하기로 하고, 앞서 제안한 상황에서 구조방정식이 가지는 장점을 가상의 분석 주제를 가지고 설명해보고자 한다. 결론부터 밝히자면, 구조방정식은 ‘잠재변수’를 분석에서 활용할 수 있다. 예를 들어 재택근무의 효과를 분석하면서 상사와의 유대감이 재택근무 만족도에 긍정적인 영향을 미칠 것이라는 가설을 세웠다고 가정해보자. 유대감과 만족도는 추상적인 개념이기 때문에 각각 3개의 문항으로 나누어 측정했다. 상사와의 유대감은 ‘1) 나의 상사는 나와 자유롭게 서로의 아이디어와 감정을 주고받을 수 있는 관계이다.’, ‘2) 나는 직장에서의 애로사항에 대하여 상사에게 허심탄회하게 말할 수 있으며, 상사도 나의 말을 경청할 것이다.’, ‘3) 나의 문제를 나의 상사와 의논한다면, 나의 상사는 내 문제를 진심으로 대하고 건설적이고 사려 깊은 조언을 해줄 것이다.’ 라는 세 가지 문항을 활용했다고 가정하자. (물론 문항은 측정하고자 하는 변수에 대한 이론을 검토하여 설계하여야 한다.) 비슷한 맥락에서 재택근무 만족도를 묻는 3가지 문항이 있다고 가정해보겠다.

일반적으로 HR 현업에서 복수의 문항을 활용한 경우, 해당 응답의 평균을 내서 분석에 활용하곤 한다. 그런데 이런 방식에서는 문제가 있다. 아래 그림을 보자. 상사와의 유대감을 묻는 문항에 대한 답변은 진짜 ‘상사와의 유대감’을 의미하는 실제 값(True)과 우연히 발생했거나 그 문항의 특성에 따라 발생한 측정오차 값(error)으로 이루어져 있다. 검사나 설문 문항을 통해 측정한 경우 필연적으로 발생하는 상황이다. 그런데 해당 문항들의 평균 응답값을 분석에 활용한 경우, 아래 오른쪽 그림처럼 빨간색의 측정오차가 그대로 남아있어 분석 결과가 오염되거나 왜곡될 수 있다.
구조방정식은 같은 개념을 측정하는 문항들에 대한 공통 분산 값을 이용해서 잠재변수(latent variable)를 도출한다. 아래 왼쪽 그림을 보면, 각 문항에 있는 실제 값(True)에 해당하는 부분을 잠재변수로 활용하는 것이다. 이러한 관계를 도식화해서 표현한 그림이 아래 오른쪽 그림이고, 구조방정식 모형에서는 이를 ‘경로도’라고 부른다. 자세히 살펴보면, 각 문항에서 잠재변수를 도출하고, 아래 상사의 유대감으로 설명되지 않는 부분을 오차(e)로 남겨놓는다. 그리고 도출된 잠재변수 간의 영향관계를 화살표로 표현했다.
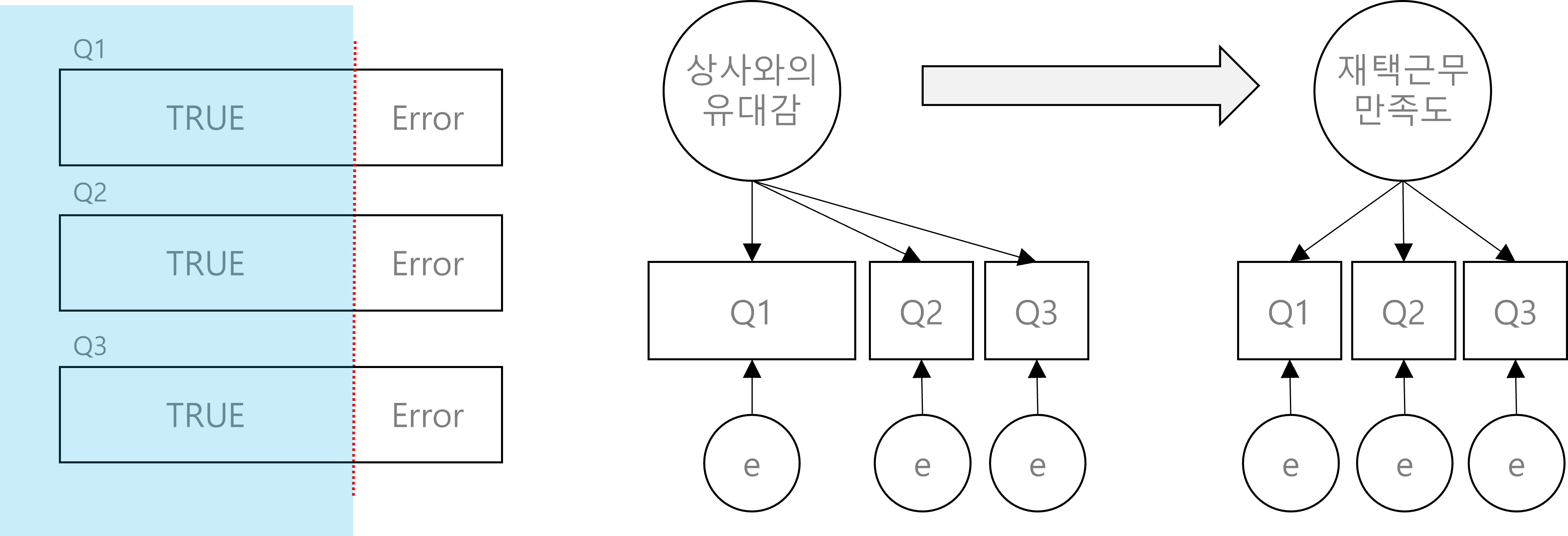
이처럼 구조방정식은 측정오차를 통제할 수 있다는 장점이 있다. 이외에도 구조방정식은 매개변수 활용에 용이하다는 점과 적합도 지수를 활용한 모형 전체의 통계적 평가가 가능하다는 점에서 장점을 가지고 있다(홍세희, 2003). 매개변수의 특성 상 독립변수와 종속변수의 역할을 동시에 수행해야 하는데 구조방정식 모형은 이러한 변수 간의 매개효과를 분석하고 평가하는 데 용이하다. 또한 적합도 지수라는 통계지표를 통해 연구자의 연구모형과 실제 자료가 얼마나 부합하는지 평가하고 필요에 따라 추가 수정할 수 있다는 장점이 있다.
이 글에서는 구조방정식의 기본개념과 HR Analytics 분석에서 활용한 사례를 소개하고자 한다. HR Analytics 특성 상 분석에 활용한 구체적인 문항과 분석 결과를 외부에 공유하기 어려워 관련해서 발간된 국내 연구 사례를 중심으로 소개하고자 한다. 보다 자세한 이론과 개념이 궁금하다면 ‘구조방정식 모형의 기본과 확장(학지사)’ 교재를 참고하길 바란다.
구조방정식의 기본 개념
구조방정식 경로도
경로도는 연구 모형에서 활용하는 변수들 간의 인과 구조를 시각화하여 표현한 그림으로, 구조방정식 모형을 직관적으로 이해하는 데 도움이 된다. 경로도의 모습은 다음과 같다.
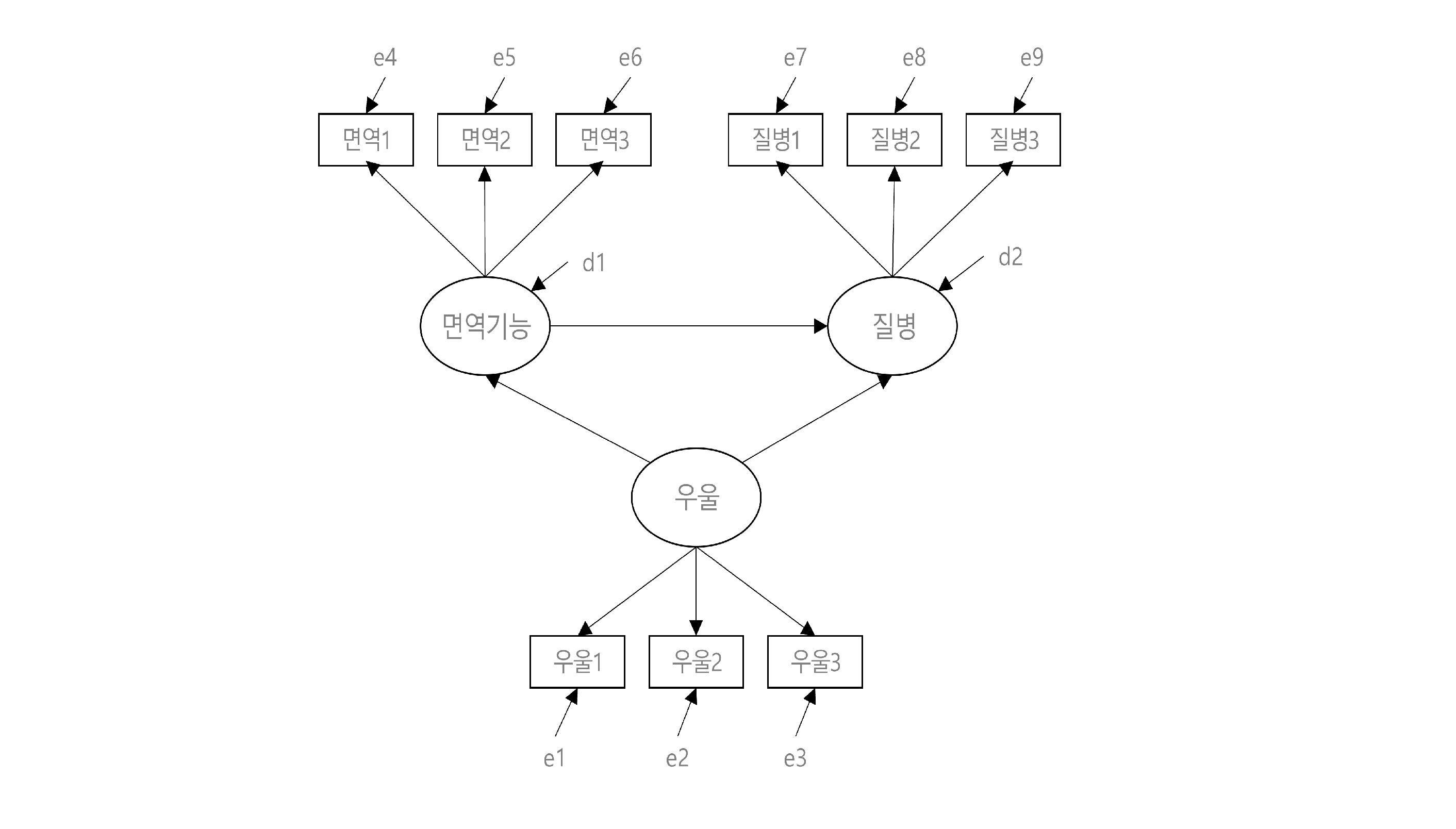
경로도를 이해하기 위해서는 구조방정식 모형에서 사용하는 주요 용어를 살펴봐야 한다. 먼저 관찰변수와 잠재변수이다. 관찰변수는 직접 측정이나 관찰이 가능한 변수로 성적, 소득, 길이, 온도, 기압, 속도처럼 명확하게 측정이 가능한 변수다. 반면 잠재변수는 무력감, 성취, 언어능력 등과 같이 추상성을 가지고 있어 직접 측정이나 관찰이 불가능한 변수를 말한다. 이러한 추상적인 변인은 복수의 문항으로 구성된 검사나 설문을 통해 측정 되는데, 이때 각 문항은 해당 문항에 대한 답변이기 때문에 관찰변수가 되고, 여러 관찰변수 저변에 잠재되어 있는 수준을 추출한 값이 잠재변수가 된다. 경로도에서는 관찰변수는 직사각형, 잠재변수는 타원으로 표시한다.
다음은 외생변수와 내생변수이다. 경로도를 보면 변수들 간의 관계를 화살표로 표현하고 있는데, 직선 일방 화살표는 변수 간의 인과관계를 나타내고 곡선 양방 화살표는 변수 간의 상관관계를 의미한다. 직선 일방 화살표를 기준으로 화살표를 보내는 변수를 외생변수, 화살표를 맞는 변수를 내생변수라고 한다. 외생변수는 다른 변수의 변화에 원인이나 동기의 역할을 하는 변수로, 모형에서 어떤 변수에 의해서도 설명되지 않는 변수다. 반면, 내생변수는 외생변수나 다른 내생변수에 의해 영향을 받는 변수이다.
다음은 오차이다. 오차도 직접 관찰되지 않고 변하는 값이므로 오차 변수(잠재변수)로 표현할 수 있는데, 구조방정식 모형에서 오차는 측정오차와 설명오차 두 가지로 구분할 수 있다. 측정오차는 관찰변수들이 잠재변수를 측정하는 과정에서 발생한 오차이다. 조금 더 풀어서 설명하자면, 각각의 관찰변수들에서 잠재변수를 설명하고 난 나머지 값을 나타낸다. 설명오차는 변수들 간의 구조적인 회귀관계에서 발생한 오차로, 내생변수의 분산 중 외생변수 혹은 외생변수들로 설명하고 난 나머지를 뜻한다. 전통적인 통계에서 오차변수는 서로 독립적인 것으로 가정하지만, 연구 모형에 따라 오차 간의 상관을 가정하여 분석하는 것도 가능하다.
측정모형과 구조모형
구조방정식은 측정모형과 구조모형이 결합된 형태로 구성되어 있다. 측정모형은 관찰변수에 의해서 잠재변수가 어떻게 측정 되는지 원리를 보여주는 모형이다.

측정모형은 잠재변수 사이의 인과적인 가설이 설정되지 않은 모형이다. 잠재변수 간의 양방 곡선 화살표를 사용한 것은 두 변수 간의 상관이 있음을 가정한 모형이라는 의미이며, 따라서 분석되지 않는 관계(unanalyzed association)이다. 오차는 서로 독립적인 것으로 가정하지만, 오차 간의 상관을 가정할 수도 있다. 도식화된 표현을 수식으로 바꾸면 아래와 같다. 이 때 계수는 잠재변수가 관찰변수를 설명하는 정도를 나타내며, 요인 부하(factor loading)라고 한다. 절편은 해당 관찰변수의 평균이며, 오차는 측정오차이다.

구조모형은 잠재변수 사이의 회귀관계를 연구하는 모형을 말한다. 구조방정식은 측정모형 분석한 후, 다음 단계로 경로모형을 분석하게 된다. 아래 그림은 전체 경로도에서 측정모형을 제외한 것으로 잠재변수 간의 영향 관계를 보여준다. 물론 경로모형에서 관찰변수를 분석에 활용할 수도 있다.
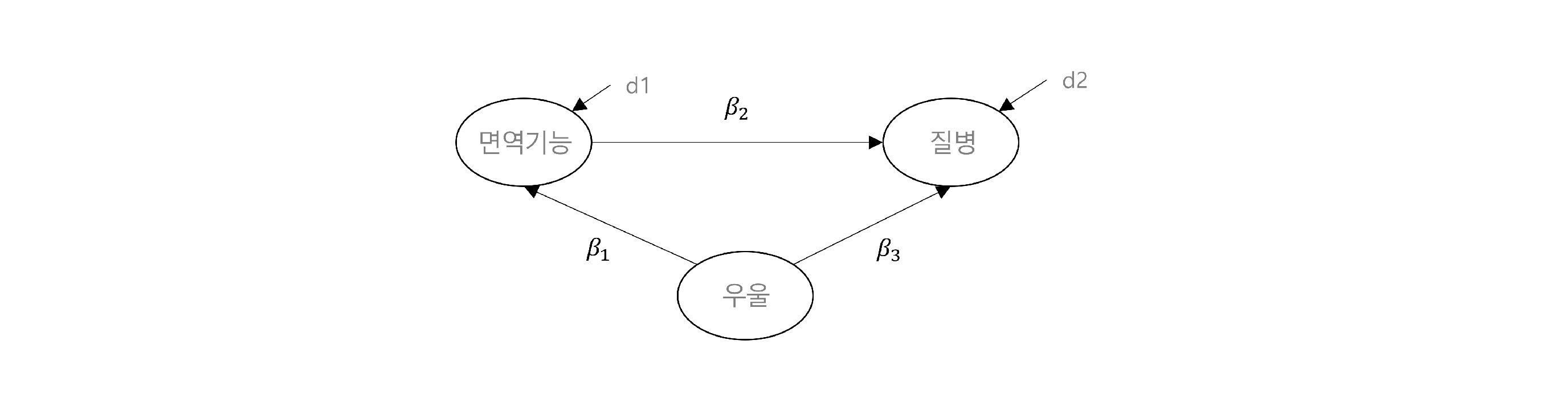
측정된 잠재변수 사이의 영향 관계를 수식으로 표현하면 아래와 같다.

구조방정식 적용 사례
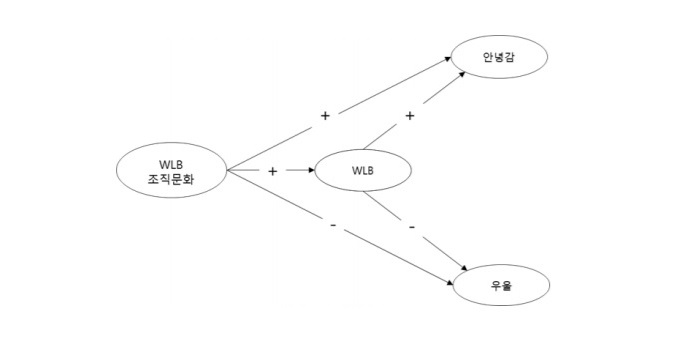
구조방정식의 기본 개념과 용어를 앞서 살펴보았다. 구조방정식 방법론이 분석에 어떻게 활용되는지 실제 사례를 하나 소개하겠다. 참고한 논문은 조직문화가 일과 삶의 균형(Work-Life Balance; 워라밸) 을 매개로 직장인의 안녕감과 우울감에 미치는 영향을 확인한 논문이다. 아래는 잠재변수들 간의 경로모형으로 전체 연구 모형을 나타낸다. 연구에서는 워라밸 조직 문화, 워라밸. 안녕감, 우울감에 대한 복수의 문항을 바탕으로 자료를 수집했다.
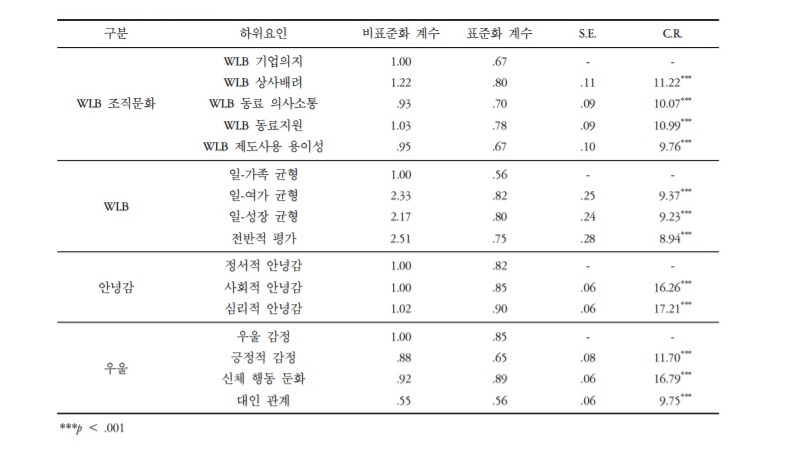
논문에서 제시한 연구 결과를 바탕으로 구조방정식 모형을 활용한 분석이 어떤 절차를 거쳐서 어떤 결과를 보고하는지를 살펴보고자 한다. 첫 번째 단계에서는 활용한 문항과 데이터가 연구자가 관심을 가지고 있는 개념을 잘 측정하고 있는지 확인한다. 이를 위해 앞서 설명한 측정모형으로 ‘확인적 요인분석’을 실시한다. 아래 표는 확인적 요인분석 결과이다. 표준화 계수로 보고하고 있는 값은 앞서 설명한 ‘요인부하’에 해당한다. 해당 연구에서는 표준화된 요인부하가 0.5 이상이며, 통계적으로 유의하며, 각 변수들이 측정하고자 하는 개념을 잘 설명하고 있다고 추정하였다. (보다 엄격한 기준을 적용하는 연구에서는 요인부하를 0.7 이상으로 보고, 기준을 충족하지 못한 문항을 제외하기도 한다.)
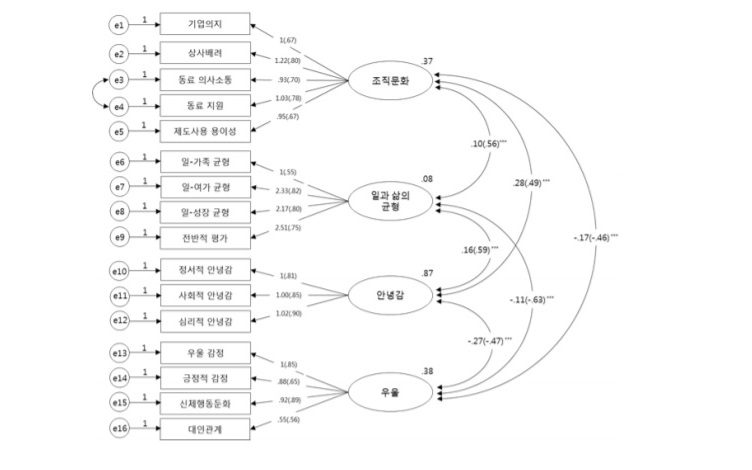
다음 단계에서는 앞서 요인분석을 통해 도출한 잠재변수들 간의 관계를 파악하기 위해 경로분석을 실시한다. 아래 분석에 의하면, 모든 경로가 유의하였고, 워라벨 조직문화가 우울에 미치는 직접효과와 워라벨이 우울에 미치는 영향은 부적인(negative) 영향임을 확인할 수 있다.
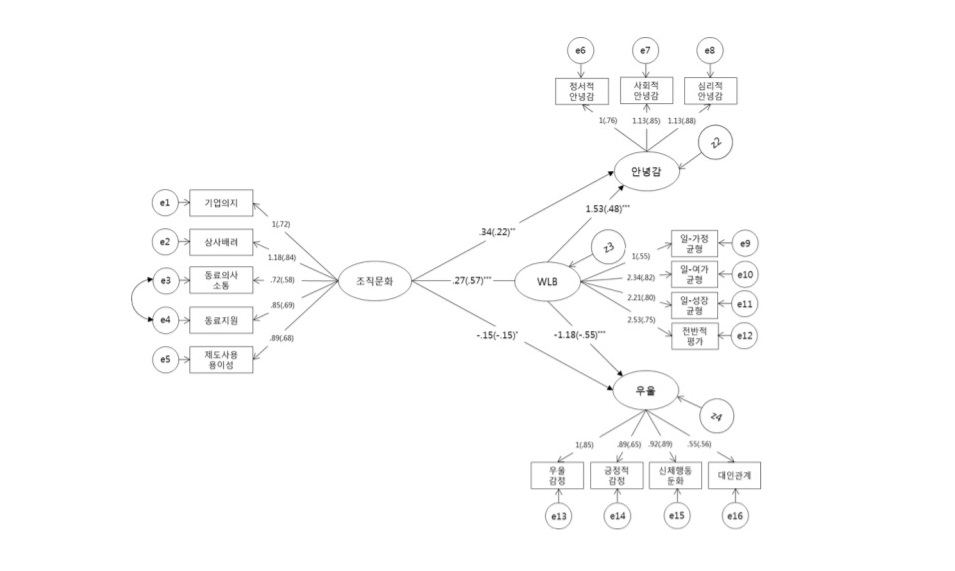
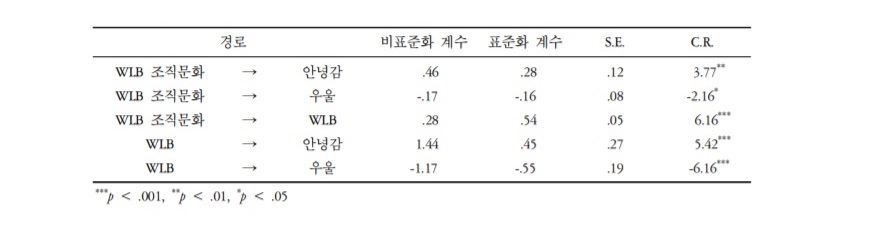
해당 모형은 매개모형으로 워라밸을 매개로 워라밸 지원 조직문화가 구성원의 안녕감과 우울감에 미치는 영향을 확인하고자 하는 연구다. 때문에 간접효과에 대해 검증해야 하는데 확률 분포를 정의할 수 없어서 부트스트래핑을 통해 유의성을 검증한다.

서론에서 밝힌대로 구조방정식은 모형 전체의 통계적 평가가 가능하다. 바로 적합도 지수를 통해 확인 가능하다. 본 연구에서는 적합도 지수 TLI = .910, CFI = .926이 좋은 적합도 기준인 0.9를 넘었고, RMSEA = 0.080으로 좋은 적합도 기준을 충족했음을 보고했다. 적합도 지수는 모형의 적절성을 통계적 지표로 나타내는데 일반적으로 아래 4개 지수를 사용한다. 자세한 내용은 논문(구조 방정식 모형의 적합도 지수 선정기준과 그 근거)을 통해 확인 가능하다.
-
TLI(Tucker-Lewis’ index) : .90 이상일 경우, 좋은 적합도
-
CFI(comparative fit index) : TLI가 0과 1 사이의 값을 갖도록 조정, .90 이상일 경우 좋은 적합도
-
RMSEA(root mean square error of approximation)
- 0.05 이하일 때 매우 좋은 적합도(Close fit)
-
SRMR(standardized root meansquare residual)
- 0과 1 사이의 값, 0.08 이하가 좋은 적합도
해당 연구는 산업조직심리학 학회지에 게재된 논문이기 때문에 안녕감, 우울감과 같은 내생변수를 사용하였지만, 실무에서 HR Analytics 를 수행할때는 조직몰입, 직무만족, 이직의도, 성과 등의 변수를 활용하여 워라벨을 지원하는 조직문화가 조직과 구성원에 미치는 효과를 밝힐 수 있을 것이다. 이처럼 구조방정식 모형을 활용하면, 측정하고자 하는 추상적인 개념과 그 개념 사이의 복잡한 관계를 밝힐 수 있다는 점에서 HR Analytics 분석 주제들을 분석하는 데 있어 활용 가능성이 높다.
지금까지 구조방정식 모형의 기본 개념과 보고된 연구 결과를 통해 어떤 결과를 도출해낼 수 있는지를 확인해보았다. 구조방정식은 기존의 HR 현업에서 수집하고 있었던 데이터를 분석하는 데 용이하며 추상적인 개념 간의 복잡한 관계를 확인할 수 있다는 장점이 있다. 다음 블로그에서는 구조방정식 모형을 응용한 분석 모형 중 HR Analytics 분석의 특수성에 부합하는 모형들을 소개하고자 한다.