
R을 활용한 게임 데이터 분석 #3
by DANBI
이번엔 R와 직접 연관이 있으면서도 좀 더 포괄적인 이야기를 다뤄보도록하겠습니다. 데이터 분석에 있어 가장 중요한 게 뭘까요? 제가 생각하기에 그것은 바로 ‘재현성(reproducibility)’ 과 ‘실행 가능성(actionability)’입니다.
#재현성과 실행가능성
재현성은 어떤 분석 결과에 대해 다른 사람이 같은 방법으로 분석했을 때, 같은 결과가 나올 수 있는 것을 말합니다. 데이터 분석이 소위 말하는 ‘데이터과학’이라 불릴 수 있으려면 이 재현성이 반드시 보장돼야 하죠.
재현성을 충족 시키지 못해 문제가 된 대표적인 사례를 하나 들어볼게요. 2014년, 일반 세포를 줄기 세포로 만드는 법에 대한 논문으로 과학계에 혜성처럼 나타났던 오보카타 하루코 라는 일본 과학자를 기억하시나요?
기존 과학계를 흔드는 엄청난 결과에, 보기 드문 여성 과학자라는 점이 작용해 언론에서 엄청난 스포트라이트를 받았죠. 하지만 다른 사람들이 논문에 나온 방법대로 실험을 해도 재현이 안 되면서 연구 결과의 진위 여부에 대한 의혹이 불거졌습니다. 결국 조작된 결과임이 들통나면서 ‘일본판 황우석’이라는 오명을 얻은 채 사람들의 관심 밖으로 사라졌죠.
 만능 세포사기극으로 열도를 들썩이게 만든 오보카타 하루코
만능 세포사기극으로 열도를 들썩이게 만든 오보카타 하루코
그런데 사실 위 사례는 워낙 언론의 스포트라이트를 받은 연구였기 때문에 더 크게 회자됐던 것이고, 이 사례뿐만 아니라 학계 전반에 재현성 문제가 만연하면서 ‘재현성위기’라는 용어가 등장하기도 했습니다. 그래서 올해 3월에 미국 통계 학회(America Statistics Association)에서 올바른 데이터 분석을 위한 지침서(https://www.amstat.org/newsroom/pressreleases/P-ValueStatement.pdf)를 발표하기도 했습니다(직접적으로는 p-value의 오남용을 막기 위한 지침이지만 포괄적으로는 재현이 안 되는 잘못된 통계 분석을 방지하기 위한 지침이라볼 수 있습니다).
데이터 분석에서도 비슷한 사례가 있습니다. ‘피터 와든’ 이라는 데이터분석가가 페이스북에서 근무하던 당시 페이스북의 친구 관계 네트워크를 분석하던 중 이 연결 정보에 의하면 미국은 7개 지역으로 나눌 수 있다는 내용을 자신의 블로그에 실었습니다(관련링크: https://petewarden.com/2010/02/06/how-to-split-up-the-us/). 그런데 이게 많은 사람들의 흥미를 끌면서 널리 퍼졌고 급기야 뉴욕 타임즈에도 실리게 되었죠. 그러나 한참 후에 피터 와든은 사실 7개 지역으로 구분한 자료는 엄밀한 분석을 통해 나온 것이 아니라 그저 주관적인 감으로 시각화해서 만든 것이라고 고백했습니다(관련링크: https://petewarden.com/2013/07/18/why-you-should-never-trust-a-data-scientist/).즉, 이 분석은 다른 사람에 의해 얼마든지 다른 결과가 나올 수 있는 재현이 안 되는 분석이었던것이죠.
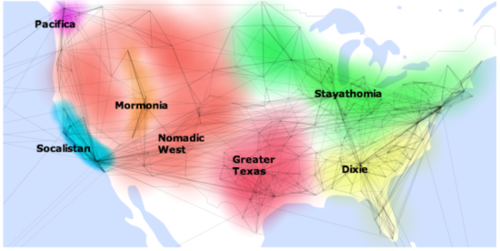 피터 와든이 만든 페이스북 친구 관계에 의해 구분된 미국 지도
피터 와든이 만든 페이스북 친구 관계에 의해 구분된 미국 지도
한편, 실행 가능성은 말 그대로 실제 활용할 수 있는 분석을 해야함을 뜻합니다. 이 실행 가능성은 재현성과도 크게 상관이 있습니다. 재현이 되지 않는 분석을 활용할 수는 없으니까요. 다만 여기서 더 나아가 재현이 될 뿐만 아니라 서비스에 활용할 수 있는 결과물을 만드는 것이 필요합니다. 아마 실제 업무를 수행하고 계신 데이터 분석가들은 다 공감하시리라 생각합니다. 얼마나 많은 노력을 들여 분석한 결과들이 한낱 단 한번의 상급자 보고를 위한 PPT로 산화하여 사라져갔는지…
이렇게 수많은 분석 결과들이 단지 화려한 PPT로 끝나는 이유는 여러 가지 말 못할 이유(!)도 있겠지만 실행 가능성이 고려되지 않은 분석도 책임을 면하기 힘듭니다.
재현성과 실행 가능성. 그런데 사실 이 두 가지 요소를 만족시키는 것은 굉장히 어려운 일입니다(사실 이 주제를 본격적으로 다루기에는 제 깜냥이 안됩니다). 단지 툴을 잘 활용한다고 해서 충족시킬 수 있는 것도 아니고요. 다만 R이 갖고 있는 프로그래밍 언어적인 특성을 최대한 잘 활용하면 이런 문제를 줄이는데 어느 정도 도움이 될 것이라 생각합니다.
저희는 데이터 분석 시, 탐사 분석 단계에서부터 R코드와 여기서 사용한 데이터를 다른 사람이 재현할 수 있도록 코드를 정리합니다.그래서 누구나 담당자가 공유한 R코드와 데이터를 내려 받아서 첫 줄부터 차례로 실행하면서 분석 보고서의 결과와 과정을 그대로 재현할 수 있죠. 일반적인 GUI기반의 분석 도구는 비록 사용은 편리하지만 전체 분석 절차를 체계적으로 정리하기가 어렵습니다. 그러나 R은 모든 것이 코드로 표현되기 때문에 이렇게 분석 결과물 자체가 전체 분석 과정을 담게 되는 것이죠.
물론 이것은 엄밀한 의미의 재현성과는 약간 다릅니다. 그러나 적어도 이런 식의 정리를 통해 다른 사람들이 분석가의 작업을 동일한 절차대로 재현할 수 있게 하면 해당 작업에 대해 리뷰하며 오류를 검증해 볼 수도 있고더 나아가 기존 분석 작업을 변형해서 새로운 결과를 얻을 수도 있기 때문에 유용합니다.
 재현 가능한 결과물의 나쁜 예
재현 가능한 결과물의 나쁜 예
또한 2편에서 설명했듯이 R은 예측 결과를 그대로 서비스에 연동하기에 편리한 언어이므로 실행 가능성 측면에서도 매우 유리합니다(오해가있을까 싶어 첨언하자면, 실행 가능성이 단지 구현 상의 문제만은 아닙니다). 심지어 서비스 서버에서 직접 실행하는 모듈 형태로 서비스할 수 있을 뿐만 아니라, R에서 만든 예측 모델을 다른 서비스나 개발 환경에서 사용할 수 있도록 PMML(PredictiveModel Markup Language) 이라는 형식의 데이터로 제공하는 것도 가능하죠.
지금까지 요즘 대세인 R의 효용성과, 엔씨소프트 데이터분석팀에서 R을 활용해 어떻게 데이터를 분석하고있는지에 대해 다소 장황하게(?) 설명을 드렸습니다.
의도치 않게 글이 길어졌는데, 결론을 아주 깔끔하게 요약해드리자면‘R은 데이터 분석뿐 아니라 그 결과를 활용해 서비스에 적용하는 데에도 아주 훌륭한 도구이다.’라고 할 수 있겠습니다.
다시 한번 말씀 드리자면 R은 보기보다 어렵지 않답니다(글이 어려웠다면 그것은 전적으로 글쓴이의 잘못!). 데이터 분석이나 머신 러닝에 관심 있는 분들이라면, 망설이지 말고! 두려움없이! 기초적인 것부터 도전해 보시길 권합니다. (파이팅!!)