
데이터 분석을 이용한 게임 고객 모델링 #2
by DANBI
1편에서 다양한 고객의 특징을 잘 파악하여 세분화하는 방법으로 ‘군집화’ 라는 것이 있다고 했습니다. 군집화는 이름에서 알 수 있듯이 전체 고객을 유사한 특성을 갖는 유형끼리 군집을 묶어주는 데이터 마이닝 기법을 말하는데요, 그럼 이번 편에서는 1편에서 언급한 3가지 관점에서 고객을 어떻게 군집화하는지 구체적인 방법에 대해 소개해 드리겠습니다.
군집화를 위해서 가장 먼저 해야 할 것은 각 유저들이 서로 얼마나 비슷한지 그 비슷한 정도를 정량화하는 것입니다. 이 값을 ‘유사도’ 혹은 ‘거리’ 라고 말합니다. ‘유사도’는 두 개체가 유사할수록 높은 값을 주고 ‘거리’는 반대로 두 개체가 서로 다를수록 높은 값을 준다는 점에서 차이가 있을 뿐 개념은 비슷합니다. 데이터의 속성에따라 여러 가지 ‘거리(혹은 유사도)’를 측정하는 방식이 있으며 이렇게 측정한 값을 토대로 군집화하는 방법 역시 다양하게 있습니다.
이 중에서 가장 널리 사용되는 방법 중 하나가 ‘k 평균 군집화 (k-meansclustering)’ 입니다. 이것은 군집화 대상들을 각각 좌표 상의 점으로 표현한 후 좌표간의 거리를 구해서 가깝게 몰려있는 점들끼리 군집을 묶는 기법입니다.
예를 들어 각 고객별로 일주일 동안 게임을 플레이한 시간과 이 때 획득한 경험치를 이용해 각각 X, Y 좌표 상의 한 점으로 표시했을 때, 아래 그림과 같이 나온다면 서로 몰려 있는 점들끼리 네 그룹으로 묶을 수 있을 것입니다. 그러면 왼쪽 하단부터 시계 방향으로 각각 ‘플레이 시간도 적고 성장도 느린 유형(Type1)’, ‘플레이는 적게 하지만 성장은 빠른 유형(Type2)’, ‘플레이 시간도 많고 성장도 빠른 유형(Type3)’, ‘플레이 시간은 많지만 성장은 느린 유형(Type4)’으로 분류할 수 있겠죠.
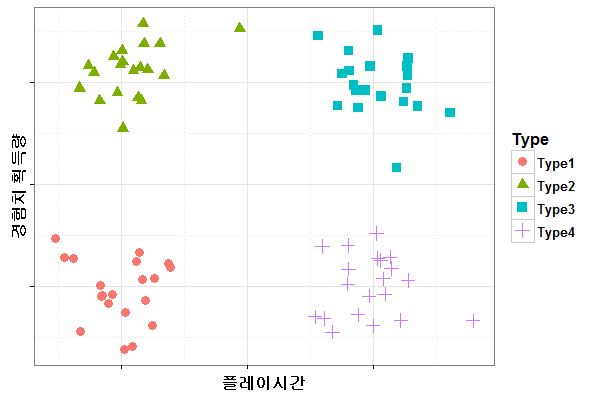
물론 위 예에서는 이해를 돕기 위해 단지 두 종류의 데이터를 이용한 것이고 실제 서비스에서는 수십 가지가 넘는 다양한 활동 정보를 이용합니다.
그런데 1편에서 언급했듯이 고객의 성향이나 활동 패턴은 조금씩 바뀌기 때문에 주기적으로 고객의 유형을 갱신해줘야 합니다. 그 때마다 매번 위 작업을 반복한다면 번거롭기 때문에 최초 군집화 결과를 이용해 이후 유형 분류를 자동화할수 있습니다. 구체적인 방법은 군집화 알고리즘이 무엇인지에 따라 조금씩 다른데요, 예를 들어 앞서 소개한 ‘k 평균 군집화’ 의 경우 각 유형별 개체들의 평균점을 기억하고 있다가 이후 새로운 데이터에 대해서 각 평균점들과의 거리를 측정한 후 가장 가까운 평균점에 해당하는 유형으로 분류할 수 있습니다(참고로 이 알고리즘 이름이 ‘k 평균 군집화’인 이유는 이처럼 k개의 평균점을 이용해서 군집을 만들기 때문입니다).
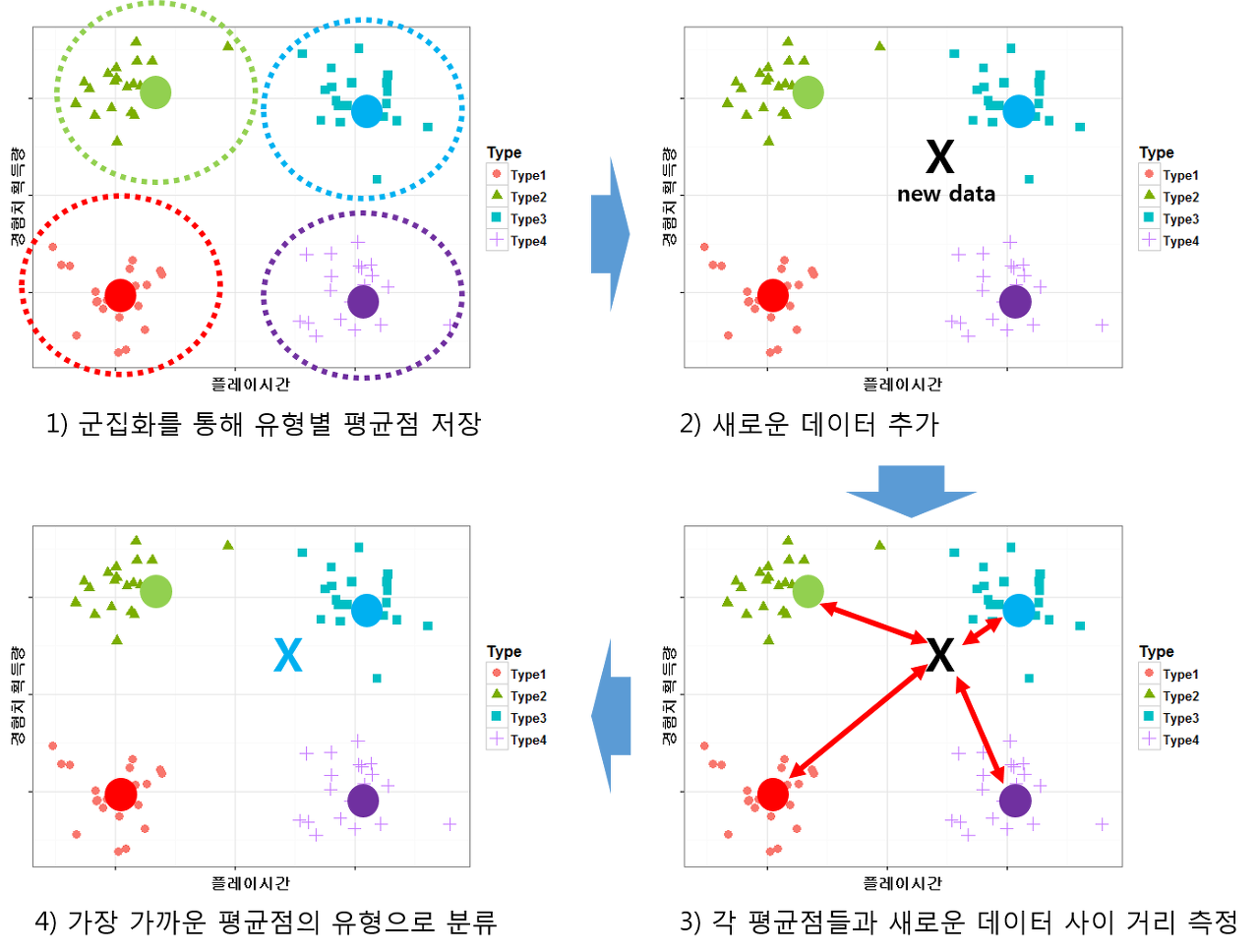 k 평균 군집화 모델을 이용해서 유형을 자동으로 분류하는 예
k 평균 군집화 모델을 이용해서 유형을 자동으로 분류하는 예
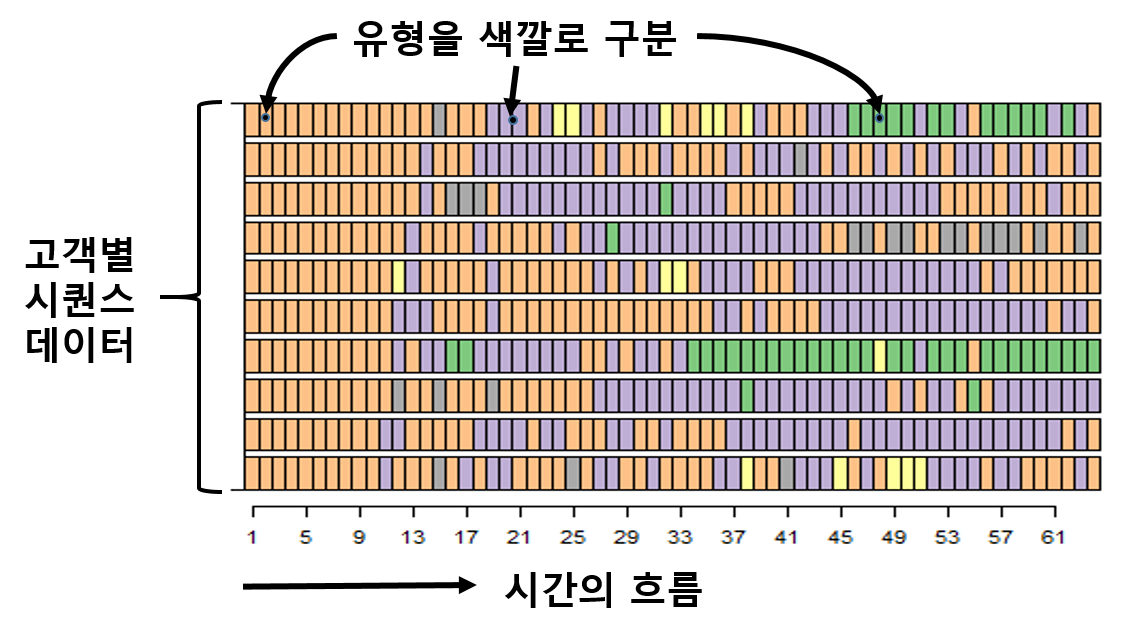
한편, 고객의 게임 활동 유형을 주기적으로 갱신하게 되면 시간이 지남에 따라 매 주기마다 고객별로 분류했던 유형의 이력이 쌓이게 됩니다. 그러면 이 이력 정보를 이용해서 아래와 같은 시퀀스 데이터를 생성할 수 있으며 이 시퀀스 데이터가 서로 비슷한 고객끼리 다시 유형을 분류할 수 있습니다.
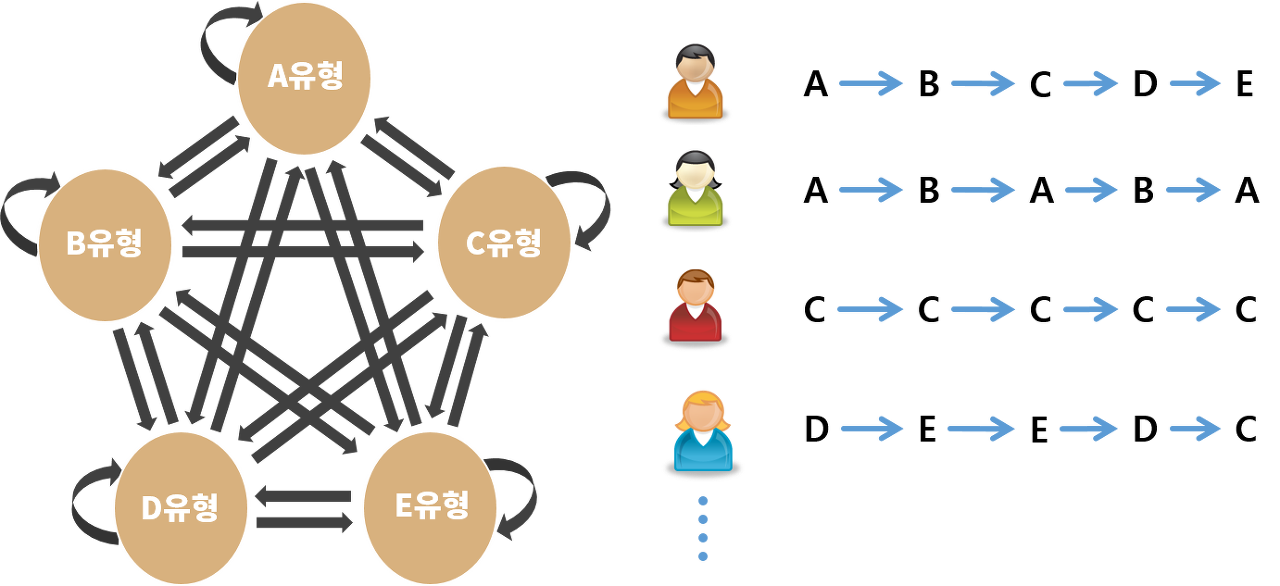 고객별 유형 분류 이력을 시퀀스 데이터로 만든예
고객별 유형 분류 이력을 시퀀스 데이터로 만든예
시퀀스 데이터의 유형을 분류할 때는 주로 ‘계층적 군집화 (Hierarchicalclustering)’ 라는 방법을 이용합니다. 이 알고리즘은 고객별 시퀀스 데이터 간의 유사도를 측정한 후 서로 비슷한 고객끼리 같은 하위 계층에 묶이도록 계층 구조를 만듭니다.
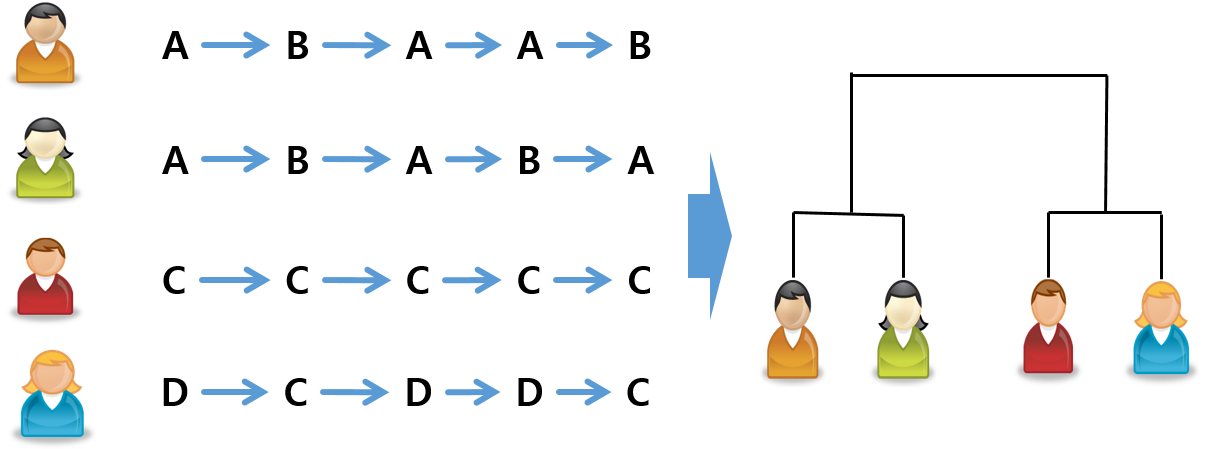 시퀀스 데이터 간의 유사성을 토대로 계층 구조를만든 예
시퀀스 데이터 간의 유사성을 토대로 계층 구조를만든 예
이렇게 계층 구조를 만들고 나면 아래 그림처럼 같은 하위 계층에 있는 고객끼리 군집을 묶어 유형을 분류할 수 있습니다.
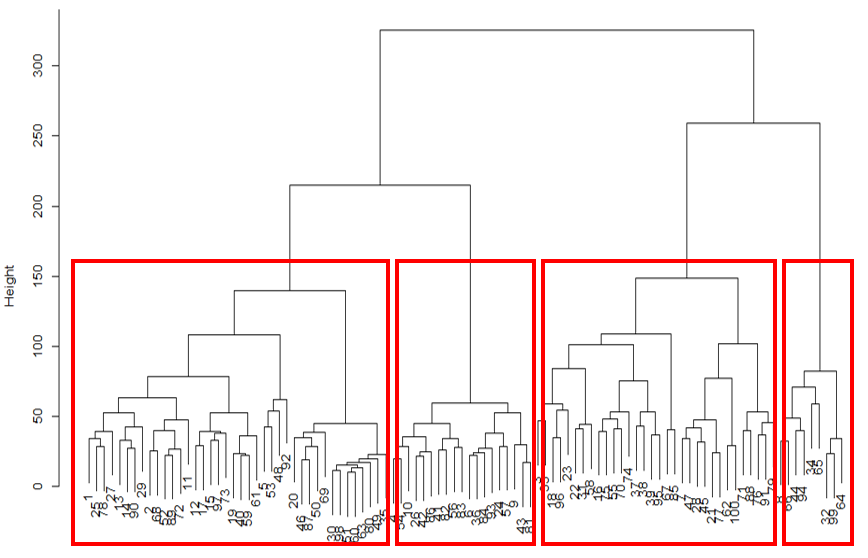 계층 구조를 이용한 군집화 예
계층 구조를 이용한 군집화 예
이처럼 고객별 게임 활동 유형의 변화에 대해 유형을 분류하면 비록 처음에는 동일한 유형이었던 고객들도 시간이 흐를수록 다른 특성을 갖는 것을 좀 더 명확하게 알 수 있겠죠?
예를 들어 아래 그림은 ‘계층적 군집화’ 방법을 이용해서 시간이 지남에 따라 활동 유형이 비슷하게 변하는 고객끼리 군집화한 자료입니다. 처음엔 모두 주황색 유형으로 분류되었던 고객들을 위에서 소개한 계측적 군집화를 이용하면 아래 그림처럼 4가지 형태로 분류할 수 있습니다. 그러면 이를 토대로 각 시퀀스 유형별 고객의 변화 원인을 분석하거나 혹은 게임 활동으로는 탐지하지 못한 어떤 차이가 있는지 등을 좀 더 장기적 관점에서 분석할 수 있죠.
더 나아가 각 시퀀스 유형별 고객들의 1인당 평균 매출을 비교해 보면 빨간색 박스로 표시한 시퀀스 유형(Type3)의 고객 매출이 다른 유형에 비해 유독 높은 것을 볼 수 있습니다. 그러면 Type3 고객과 다른 고객의 차이를 분석해 봄으로써 사업적인 관점에서 의사 결정을 하는데 도움이 될 수 있습니다.
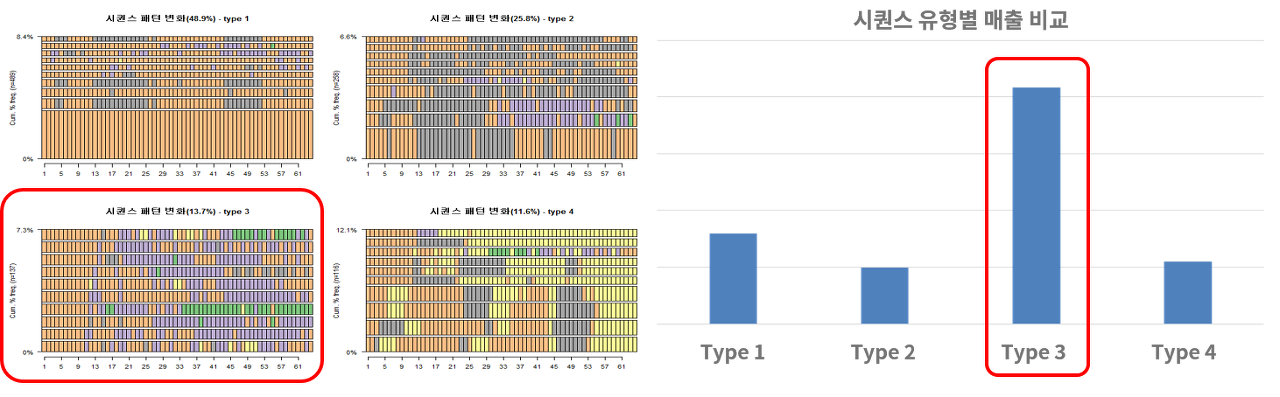 고객의 게임 활동 유형의 변화가 비슷한 집단끼리 분류한 예
고객의 게임 활동 유형의 변화가 비슷한 집단끼리 분류한 예
지금까지 고객 개개인 별로 특정 시점에서의 게임 활동이나 시간에 따른 변화 패턴을 토대로 유형을 분류하는 방법을 소개했는데요, 이렇게 개개인의 특성을 분석하는 것만으로 과연 고객의 모든 것을 파악할 수 있을까요? (물론 이렇게 묻는 것은 아니라는 뜻이죠 ^^)
잠시 머리를 식히는 의미에서 영화 이야기를 잠깐 해보죠. 혹시 제 또래 분들이라면 지금은 고인이 된 크리스토퍼 리브가 주연을 맡았던 ‘슈퍼맨’ 시리즈를 기억하실지 모르겠네요. 이 슈퍼맨 시리즈 중 3편 마지막 부분에 보면 슈퍼맨이 어린 시절 짝사랑했던 여자 친구 주려고 석탄 한 움큼을 꽉 쥐어 다이아몬드로 만드는 장면이 나옵니다.
 비록 지금은 마블이 짱 먹고 있지만 이 당시에는DC의 히어로들이 최고였죠!
비록 지금은 마블이 짱 먹고 있지만 이 당시에는DC의 히어로들이 최고였죠!
뭐 이런 말도 안 되는 설정이 다 있나……라고 생각하시는 분도 계실지 모르겠습니다만 이건 사실 과학적으로도 충분히 가능한 설정이랍니다. 석탄과 다이아몬드는 둘 다 탄소로 이뤄진 물질이기 때문에 석탄에 충분한 압력을 가한다면 다이아몬드로 바꿀 수 있죠(우리도 ‘충분히’ 노오력하면 모두 성공할 수 있어요).
심지어 어린 시절 흔하게 쓰던 연필심도 탄소로 이뤄져 있습니다. 석탄과 연필심은 둘 다 검고 잘 부서지며 손에 검댕이가 잘 묻는다는 점을 생각해 보면 뭐 그럴 수 있겠구나 싶지만 겉으로 보기엔 전혀 다를 것 같은 다이아몬드도 똑같은 물질이라는 것이 믿어지시나요? 이렇게 다이아몬드와 연필심, 석탄이 입자 수준에서 보면 완전히 동일한 물질임에도 불구하고 전혀 다른 외형과 특성을 갖는 이유는 입자끼리 서로 얽힌 구조가 다르기 때문입니다.
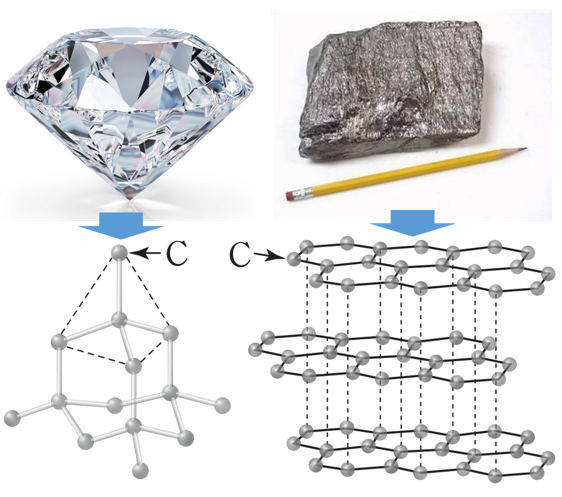 같은 입자로 이뤄진 물질이라 하더라도 서로 어떻게연결되는지에 따라 다른 특성을 가질 수 있습니다.
같은 입자로 이뤄진 물질이라 하더라도 서로 어떻게연결되는지에 따라 다른 특성을 가질 수 있습니다.
게임 고객 역시 마찬가지입니다. 개개인의 데이터를 확인했을 때는 매우 비슷해 보여도 다른 고객들과 어떤 사회 관계를 맺고 있느냐에 따라 전혀 다른 유형의 고객인 경우를 종종 볼 수 있습니다. 따라서 고객을 잘 세분화하려면 개개인의 특성뿐만 아니라 고객 사이의 연결 구조 역시 분석해야 합니다.
1편에서 잠깐 소개해 드렸듯이 이렇게 고객 사이의 연결 구조를 분석하는 기법을 ‘사회 연결망 분석(Social network analysis)’이라고 하는데 이에 대해서는 다음 편에서 자세히 소개하겠습니다.