
네트워크 분석기법을 활용한 게임 데이터 분석 #1
by DANBI
0. 시작하며
‘small world network’ 라고 부르는 현상이 있습니다. 아마 사회 생활을 하다보면 처음 보는 사람인데 얘기하다 보니 내 친구의 친구였거나 혹은 직장 동료 결혼식에 가서 대학 동기를 만났는데 알고 보니 그 친구의 친척이더라…와 같은 경험을 해보셨을 텐데요, 이처럼 세상에는 수 많은 사람이 있음에도 불구하고 생각보다 사람들간의 사회적 거리가 짧은 현상을 일컫는 말입니다. 그런데 보통 사람들이라면 이런 경험을 하고 나서 ‘와 신기하다’ 하고 그냥 넘어가고 말텐데, 호기심 많은 몇몇 학자들은 이게 정말 보편적인 현상인지, 만약 그렇다면 왜 그런지 등을 연구하기 시작했죠.
이런 현상을 가장 처음 이론적으로 증명한 것은 영화 ‘Beautiful mind’의 실존인물로 유명한 수학자 에르되시였습니다. 그가 제안한 이론은 랜덤 그래프 (random graph) 모델입니다. 이름으로 짐작할 수 있듯이 확률적으로 노드간에 임의의 선을 긋게 되면 자연적으로 ‘small world’ 현상이 일어난다는 것이죠. 그러나 비록 랜덤 그래프가 단순하고 깔끔하긴 했으나 그 외에 사회 관계 네트워크가 갖는 다른 특징들은 설명해주지 못하는 단점이 있었습니다.
그런데 1998년에 던컨 와츠라는 코넬 대학 학생이 지도교수인 스티븐 스트로가츠와 함께 ‘Collective dynamics of small-world networks’ 라는 제목의 3페이지짜리 짧은 논문을 Nature 에 발표합니다 (<그림1>). 이 논문에서 와츠와 스트로가츠는 격자형 네트워크 (Lattice network) 와 에르되시의 랜덤 그래프의 중간 형태를 취한 'small world network' 모델을 소개합니다. 그리고 (흥미롭게도) 배우들의 영화 출연 관계에 대한 네트워크나 전력선 연결 구조, 심지어 '예쁜 꼬마 선충' 이라고 부르는 선형 동물의 뇌에 있는 뉴런 간의 연결 구조 등을 이 모델을 통해 시뮬레이션할 수 있었죠.
 그림 1. 와츠와 스트로가츠의 논문 - 저도 3페이지만 쓰고 Nature 에 실릴 수 있으면 참 좋겠습니다.
그림 1. 와츠와 스트로가츠의 논문 - 저도 3페이지만 쓰고 Nature 에 실릴 수 있으면 참 좋겠습니다.
이렇게 서로 관련이 없어 보이는 다양한 분야에서 발견되는 네트워크들이 공통적인 특성이 있다는 사실은 곧 여러 사람들의 관심을 끌게 되었고 이 논문은 마이너 학문이었던 네트워크 과학 분야를 주류의 반열에 올려 놓은 일등 공신이 되었습니다. 이후 네트워크 과학은 2000년대 초반을 거치며 크게 발전하였으며, 여기서 탄생한 다양한 이론과 기법들이 다른 분야에 활발히 전파되면서 네트워크 구조를 분석하는 기법들도 점차 대중화되었습니다.
제가 처음 네트워크 분석에 관심을 갖게 된 것은 2010년 경이었는데 그 당시만 해도 분석 기법이나 도구 등이 많이 알려져 있지 않았습니다. 그런데 지금은 꽤 널리 알려져서 인터넷을 조금만 검색해 봐도 다양한 분석 사례들을 찾을 수 있죠.
그러나 또 한편으로는, 막상 외부에 알려진 분석 사례들을 살펴 보면 지극한 피상적인 분석에만 머무는 경우가 대부분입니다. 대개 이런저런 시각화를 통해 네트워크 구조를 눈으로 살펴본 후 정성적인 판단을 하는데 그치거나 혹은 조금 더 나아가면 degree 나 betweenness centrality 를 구한 후 가장 중심이 되는 노드가 무엇인지 찾는 정도가 대부분이죠.
그래서 이 글을 통해 저희가 주로 활용하는 네트워크 분석 기법에 대해 소개하고, 이를 이용해 실제 게임 데이터를 분석했던 사례를 통해 네트워크 분석이 갖고 있는 숨겨진 매력을 보여드리고자 합니다.
1. 네트워크 분석이란?
1.1. 네트워크의 정의
네트워크란 노드 (node) 와 엣지 (edge) 로 이뤄진 자료 구조를 말합니다. <그림2>의 왼쪽에 나와 있듯이 노드는 개체를 의미하며 이 개체들간의 연결 관계가 엣지입니다. 네트워크는 다른 말로 '그래프' 라고도 부르며 노드와 엣지는 각각 버텍스(vertex)와 링크 (link) 라고도 합니다. 좀 더 엄밀히 말하면 보통 수학 분야에서는 '그래프 - 버텍스 - 엣지' 라고 부르고 물리학에서는 '네트워크 - 노드 - 링크' 라고 합니다. 네트워크(그래프) 이론이 수학과 물리학 양쪽에서 진행되다 보니 이렇게 용어가 통일되지 못한 면이 있습니다. 하지만 전 그냥 분야를 구분하지 않고 '네트워크 - 노드 - 엣지' 라고 혼용해서 사용합니다.
네트워크는 보통 행렬 형태로 표현합니다. 예를 들어 <그림2>의 왼쪽과 같이 4개의 노드가 연결되어 있는 네트워크가 있을 때 두 노드 사이에 연결관계가 있으면 1, 없으면 0으로 채워넣은 행렬을 오른쪽과 같이 만들 수 있죠.
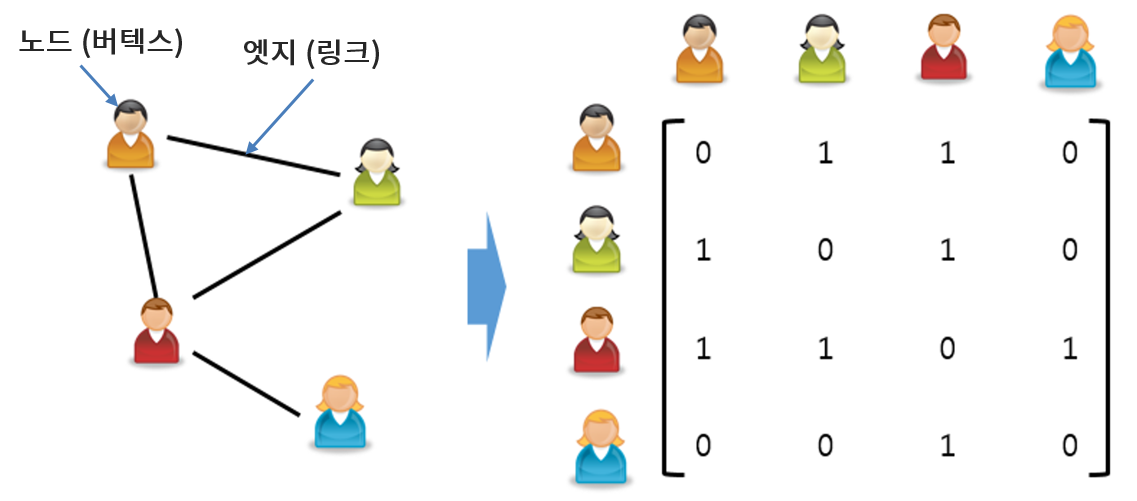 그림 2. 방향성과 가중치가 없는 네트워크
그림 2. 방향성과 가중치가 없는 네트워크
네트워크는 엣지에 방향이나 가중치를 표현할 수도 있습니다. 단순히 친구 관계를 나타내고 싶다면 방향이나 가중치를 구분할 필요가 없겠지만 만약 선물을 주고 받은 관계를 표현하고 싶다면 누가 누구에게 몇 번 선물을 줬는지 표시하기 위해 방향과 가중치를 줄 수 있겠죠. 이런 경우에도 역시 <그림3>과 같이 행렬로 표현이 가능합니다. 위에 친구 관계 네트워크에 대한 행렬은 0과 1로만 이뤄진 대칭 행렬이지만 방향성과 가중치를 넣으면 가중치 값이 들어간 비대칭 행렬이 됩니다. 이런 식으로 어떤 네트워크든 모두 행렬로 표현이 가능합니다.
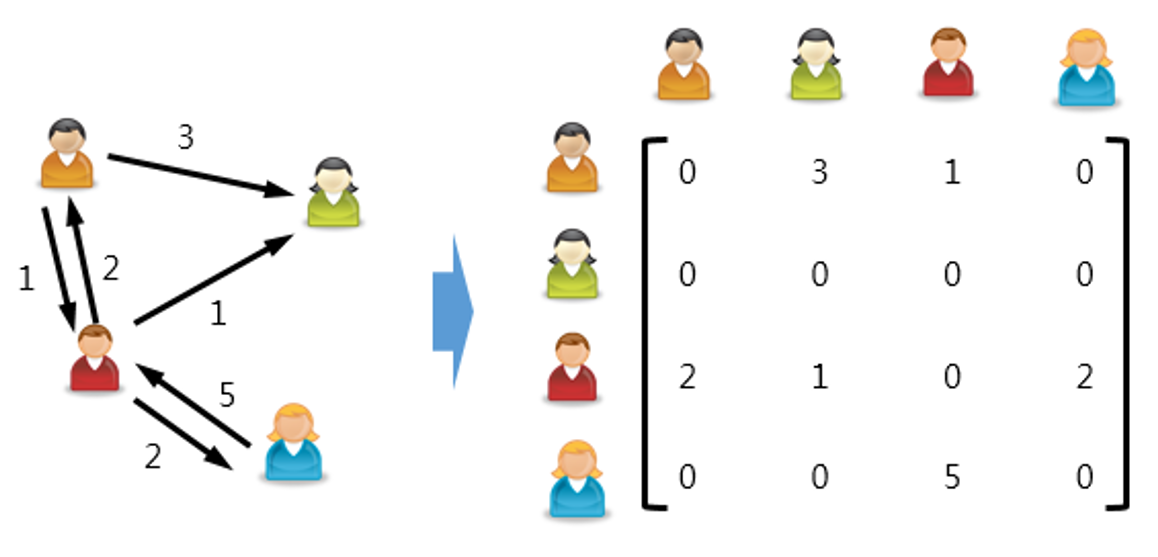 그림 3. 방향과 가중치가 있는 네트워크
그림 3. 방향과 가중치가 있는 네트워크
이런 네트워크 구조를 갖고 있는 데이터를 분석하는 것을 네트워크 분석이라고 합니다. 그런데 대체 왜 이런 데이터를 분석하는 것이 필요할까요?
1.2. 왜 네트워크 분석이 필요한가?
제가 생각하기에 네트워크 분석이 필요한 가장 큰 이유는, ‘환원주의 오류’에 빠지는 것을 피하는데 도움이 되기 때문입니다. ‘환원주의’란 어떤 대상이나 개념을 하위 단계의 요소로 세분화하여 정의하는 것을 말합니다. 많은 과학들이 환원주의를 사용합니다. 이를 테면, 물질을 분자, 원자, 중성자/양성자/전자, … 이런식으로 쪼개어 그 성질을 분석하거나, 생물을 각 신체 부위나 기관, 세포 등의 요소로 나눠서 파악하는 식이죠.
잘 생각해 보면 우리가 데이터를 분석할 때도 데이터를 구성하는 여러 개의 피처(변수)로 나눠 분석하는데 이것 역시 일종의 환원주의적인 분석 방법입니다. 심지어 분석이라는 말 자체도 分(나눌 분)과 析(쪼갤 석) 이라는 한자말로 이뤄져 있죠.
대부분의 경우 이런 환원주의적 분석은 좋은 방법입니다. 그러나 때론 이렇게 하위 요소의 특징에만 집착할 경우 소위 ‘큰 그림’을 놓칠 수 있는데 이런 것을 ‘환원주의 오류’ 라고 부릅니다. 제가 환원주의 오류를 설명할 때 종종 드는 예가 ‘다이아몬드’와 ‘흑연’입니다.
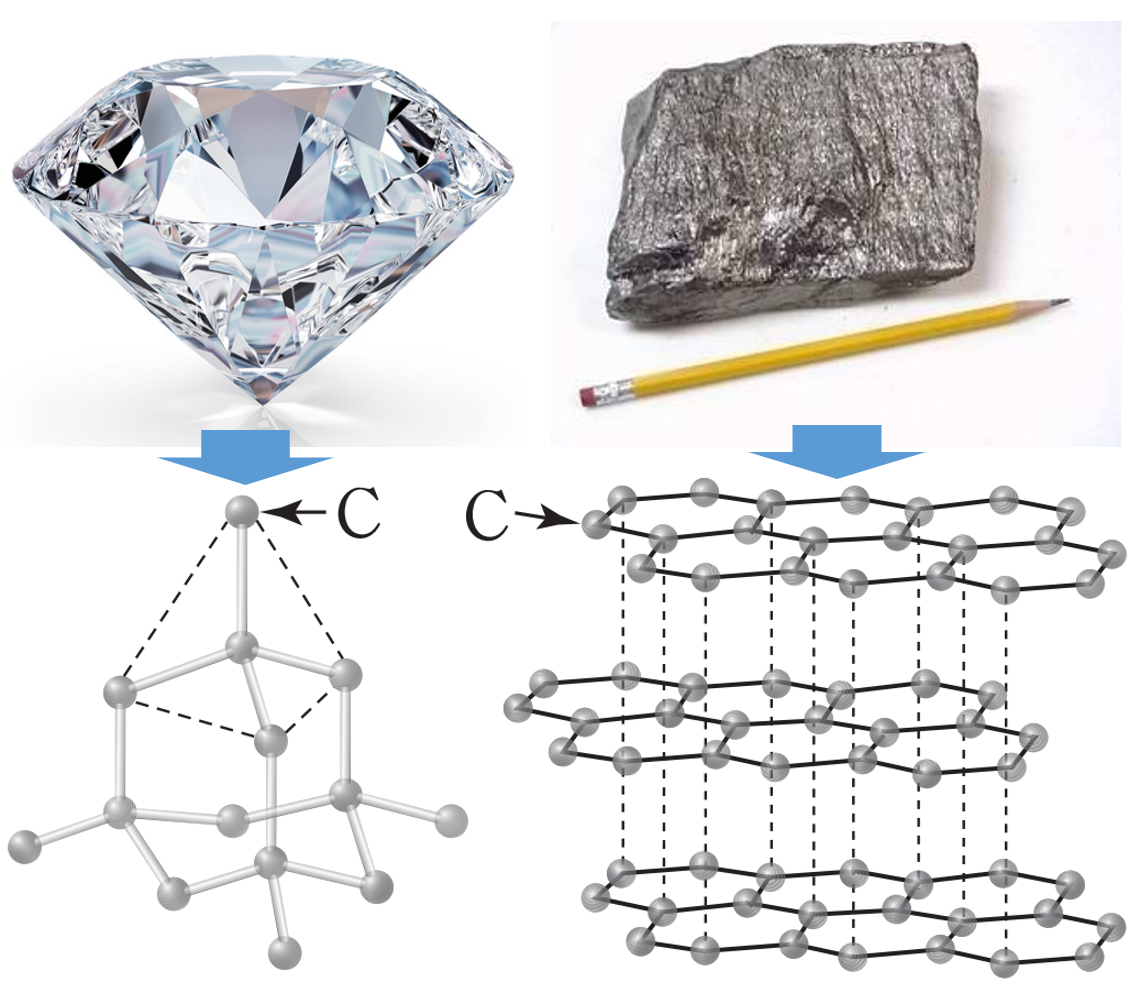 그림 4. 다이아몬드와 흑연의 분자 구조 비교
그림 4. 다이아몬드와 흑연의 분자 구조 비교
아시다시피 다이아몬드와 흑연은 겉으로 보기엔 전혀 다른 물질입니다. 다이아몬드는 반짝거리고 단단하며 비싼 반면, 흑연은 칙칙하고 잘 부스러지며 저렴하죠. 그런데 재미있게도 이 둘은 모두 탄소 분자로 이뤄져 있습니다. 따라서 이 둘을 환원주의적으로 분석하면 하위 요소인 분자가 갖는 특징은 완전히 같기 때문에 동일한 물질이라고 판단할 수 있습니다.
다이아몬드와 흑연이 같은 탄소 분자로 이뤄졌음에도 불구하고 완전히 다른 특성을 갖는 이유는 탄소 분자들의 연결 구조가 다르기 때문입니다 (<그림 4> 참고). 즉, 네트워크 구조가 다른 것이죠. 따라서 단순히 분자 (노드) 의 특징만 분석할 것이 아니라 노드간의 연결 관계인 네트워크 구조도 분석해야 다이아몬드와 흑연의 차이점을 알 수 있습니다. 그럼 네트워크 데이터를 분석하려면 어떻게 해야 할까요?
2. 주요 네트워크 분석 기법
네트워크 분석 기법은 크게 1) 노드 중요도 (node centrality) 측정, 2) 네트워크 구조 추정, 3) 커뮤니티 탐지로 나눌 수 있습니다.
2.1. 노드 중요도 측정
노드 중요도를 측정한다는 것은 ‘네트워크 구조를 고려했을 때 각 노드들이 얼마나 중요한 위치에 있는지를 정량화하는 것’을 말합니다. 예를 들어 어떤 도시에 기차역과 역 사이에 놓인 기차길이 <그림5>와 같이 생겼다고 가정해보죠. 이런 구조의 기차 노선에서 가장 중요한 기차역 (노드) 은 무엇이며 각 기차역의 중요도를 정량적으로 측정하려면 어떻게 해야 할까요?
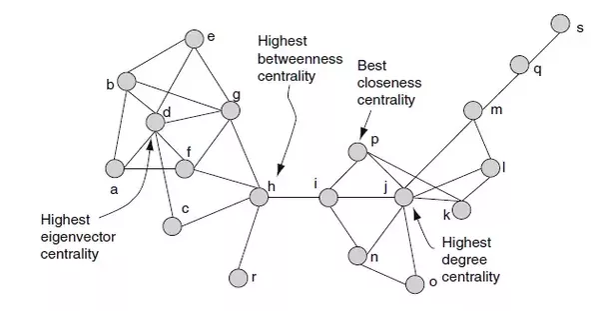 그림 5. 기차 노선을 네트워크 구조로 시각화한 예시
그림 5. 기차 노선을 네트워크 구조로 시각화한 예시
A. Degree centrality
우선 가장 쉽게 할 수 있는 것은 각 역이 다른 역과 얼마나 많이 연결되어 있는지 그 횟수를 세어 중요도를 측정하는 방법입니다. 이걸 ‘degree centrality’ 라고 부릅니다. 그리고 이렇게 하면 <그림5>에서는 j 가 가장 중요한 기차역이 됩니다. 이 역은 인접한 기차역이 일곱 개로 가장 많기 때문이죠.
그런데 한번 j 역을 폐쇄한다고 생각해보죠. 가장 중요한 기차역이니 교통 대란이 발생할 것 같은데, 자세히 보면 해당 역을 이용하던 사람들은 불편할 수 있겠지만 다른 역끼리는 대체 경로가 있기 때문에 (다소 돌아가는 번거로움은 있더라도) 이동하는데 크게 지장이 없습니다.
B. Betweenness centrality
그런데 만약 h 역을 폐쇄하면 어떻게 될까요? 이제 h 역을 기준으로 왼쪽에 위치한 지역과 오른쪽에 위치한 지역은 서로 왕래가 불가능합니다. 왜냐하면 양쪽을 오고가려면 h 역을 만드시 통과해야 하기 때문이죠. 따라서 교통 흐름의 관점에서 보면 (비록 직접 연결된 기차역의 수는 적지만) h 노드가 가장 중요한 노드가 됩니다. 이렇게 노드 간의 흐름을 고려하여 중요도를 측정하는 방식을 ‘betweenness centrality’ 라고 부릅니다.
C. Closeness centrality
한편 p 역은 접근성 면에서 가장 좋습니다. 다시 말해 만약 기차역 간에 거리가 동일하다고 가정하면, 어떤 지역에서든지 p 로 갈 때 걸리는 시간이 평균적으로 가장 짧습니다. 이렇게 접근성 측면에서 노드의 중요도를 측정할 수도 있는데 이런 방식을 ‘closeness centrality’ 라고 부릅니다.
D. Eigenvector centrality
그런데 단순히 가장 거리가 가깝다고 다 좋은 것은 아니겠죠? 우리 나라에서도 단순히 물리적인 거리로만 보자면 충청도가 가장 중앙에 위치하지만, 대부분의 인프라나 사람들은 경기도에 몰려 있기 때문에 충청도에 산다고 해서 가장 편한 것은 아닙니다.
마찬가지로 위 그림에서도 단순히 거리만 따지기 보다는 각 기차역의 이용객 수나 기차역 근처 지역의 특성 등을 고려하여 접근성을 따지는 것이 더 합리적일 수 있습니다. 이렇게 각 노드별 가중치를 고려하여 중요도를 측정하는 방식을 ‘eigenvector centrality’ 라고 부릅니다.
노드의 중요도를 측정하는 방법은 어떤 측면에서 바라볼 것이냐에 따라 이처럼 다양합니다 (여기 소개한 것 외에도 중요도 측정 방식은 많이 있습니다). 따라서 목적에 따라 적절한 방법을 사용해야 합니다. 보통 제 경우에는 한가지 방법만 사용하기 보다는 위에서 소개한 방법 중 몇 가지를 함께 활용합니다.
2.2. Network structure
네트워크를 분석할 때는 해당 네트워크가 어떻게 생겼는지 구조를 파악하는 것도 중요합니다. 그런데 여기서 말하는 네트워크 구조라는 것은 단순히 외형을 말하는 것이 아닙니다. 예를 들어 <그림6>에 있는 세 개의 네트워크는 서로 생김새는 다르지만 완전히 동일한 네트워크입니다. 단지 그리는 방식이 다를 뿐이죠. 이건 마치 동일한 데이터를 막대 그래프로 그리느냐 선 그래프로 그리느냐의 차이와 비슷합니다.
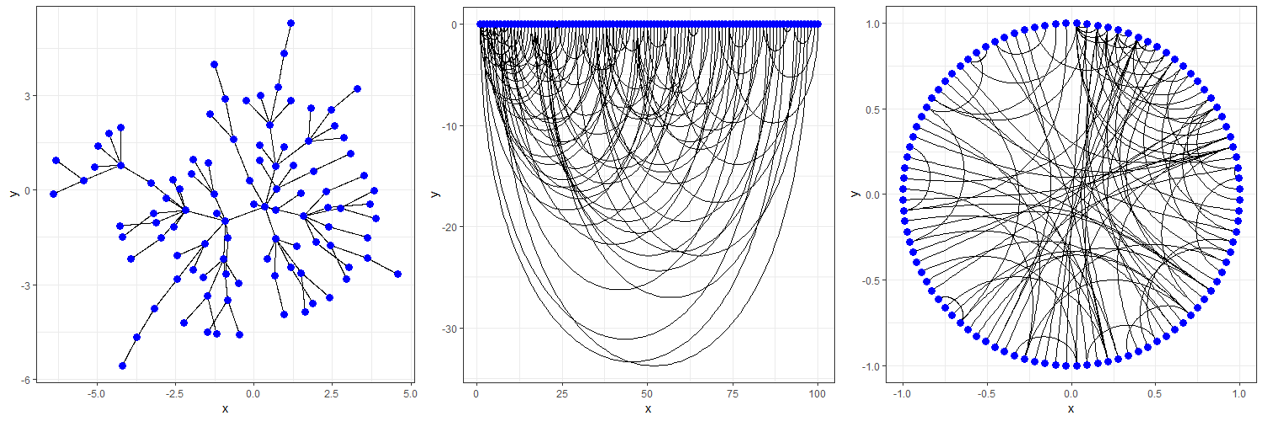 그림 6. 동일한 네트워크에 대해 형태만 다르게 시각화한 예시
그림 6. 동일한 네트워크에 대해 형태만 다르게 시각화한 예시
따라서 네트워크 구조를 파악하려면 단순히 생김새를 눈으로 보고 판단할 것이 아니라 네트워크 구조를 정량적으로 측정해주는 기법을 사용해야 합니다. 그런데 네트워크 구조 역시 노드 중요도를 구할 때처럼 어떤 것을 중점적으로 볼 것이냐에 따라 여러 가지 측정 방식이 있습니다. 제가 주로 사용하는 기법 중 몇 가지를 소개하면 다음과 같습니다.
A. Radius
Radius는 우리말로 하면 ‘반지름’ 입니다. 반지름이란 원의 중심에서 표면까지의 최단 거리를 의미하죠. 이와 비슷하게 네트워크의 반지름이란 closeness centrality 가 가장 높은 노드에서 가장 먼 노드까지의 최단 거리를 의미합니다. 예를 들어 <그림7>에서 왼쪽 네트워크는 여러 개의 노드가 일렬로 쭉 늘어서 있는 구조입니다. 따라서 이런 경우에는 중앙에 있는 노드가 closeness centrality가 가장 높은데, 여기서 가장 끝단에 있는 노드까지의 거리는 전체 노드 개수의 절반인 11이 됩니다. 반면 오른쪽 네트워크는 마치 회사 조직도처럼 계층적인 구조를 갖고 있어서 가장 상위에 위치한 노드가 가장 높은 closeness centrality 를 갖습니다. 그리고 이 노드에서 단 2단계만 거치면 말단 노드까지 도달합니다. 따라서 이 네트워크는 노드의 개수가 왼쪽보다 더 많음에도 불구하고 radius는 훨씬 작은 2에 불과합니다. 이렇게 네트워크의 노드 개수와 radius의 관계를 이용하면 네트워크 구조가 어떻게 되는지 대략적으로 가늠할 수 있습니다.
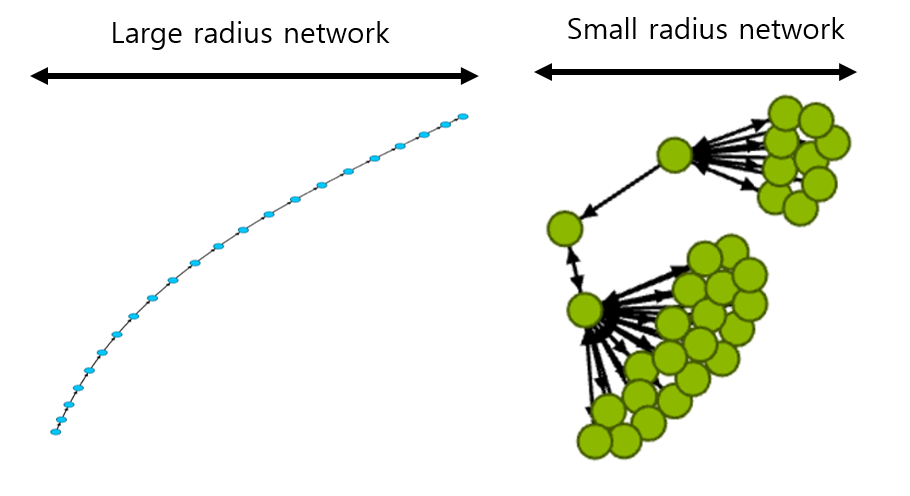 그림 7. Radius가 큰 네트워크(왼쪽)와 작은 네트워크(오른쪽) 예시
그림 7. Radius가 큰 네트워크(왼쪽)와 작은 네트워크(오른쪽) 예시
B. Clustering coefficient
클러스터링 계수는 쉽게 말해 ‘나의 서로 다른 두 친구가 서로 친구일 확률’ 입니다. 즉, 어떤 노드와 연결된 노드들 중에 임의로 두 개를 골랐을 때 이 두 노드도 서로 연결되어 있을 확률입니다. 네트워크 이론에서는 어떤 세 개의 노드가 서로 연결되어 있는 구조를 ‘clique’라고 부릅니다 (<그림8>의 오른쪽). 그래서 어떤 네트워크에서 모든 노드가 완전히 연결되어 있다고 할 때 나올 수 있는 clique 개수 대비 실제 네트워크 구조에 있는 clique 개수의 비율을 구하면 클러스터링 계수가 됩니다.
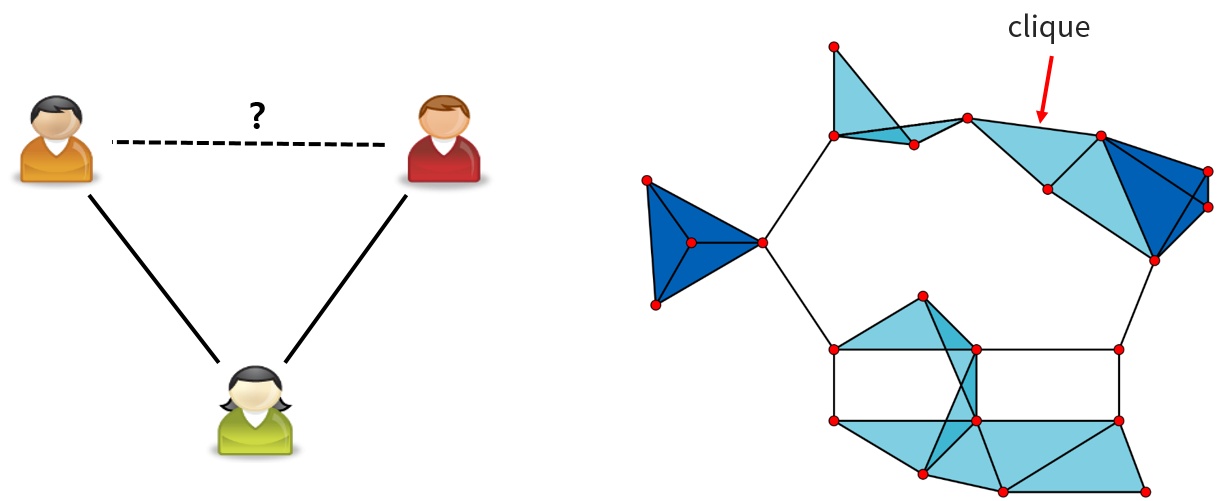 그림 8. 클러스터링 계수와 클리크
그림 8. 클러스터링 계수와 클리크
예를 들어 <그림9>의 두 네트워크 중에서 왼쪽에 있는 것은 한눈에 봐도 clique가 하나도 없죠? 따라서 이 그래프의 클러스터링 계수는 0입니다. 반면 오른쪽 네트워크는 많은 clique를 갖고 있기 때문에 1에 가까운 클러스터링 계수를 갖습니다. 결국 클러스터링 계수를 측정하면 네트워크가 얼마나 많은 clique를 갖고 있는 구조인지 알 수 있습니다.
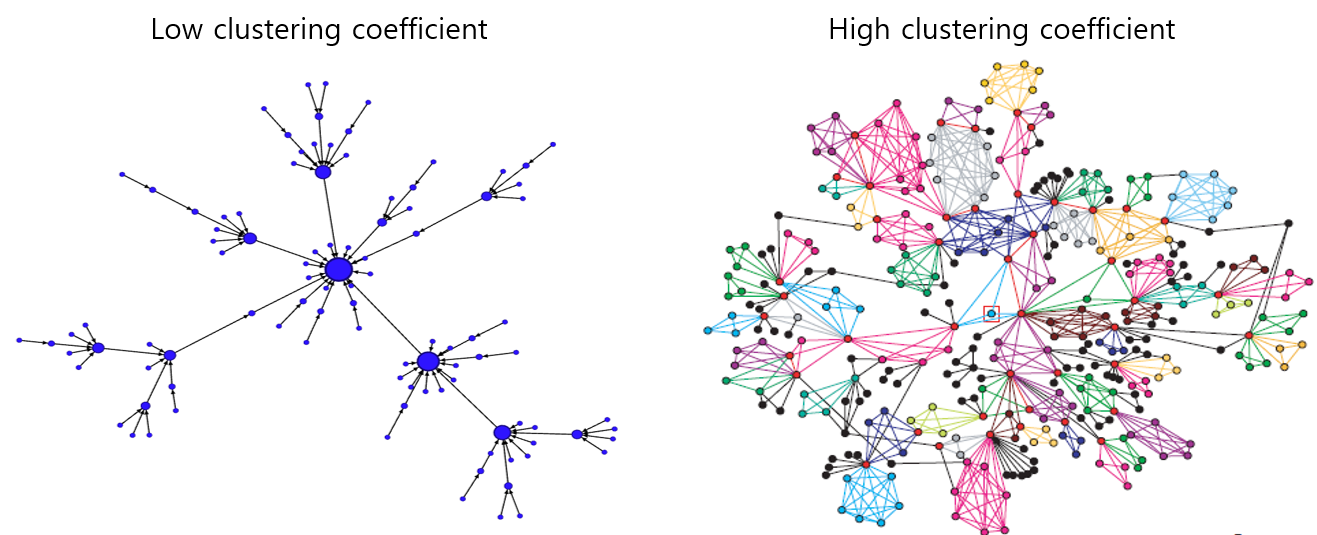 그림 9. 클러스터링 계수가 낮은 네트워크(왼쪽)와 높은 네트워크(오른쪽) 예시
그림 9. 클러스터링 계수가 낮은 네트워크(왼쪽)와 높은 네트워크(오른쪽) 예시
C. Degree assortativity
마지막으로 제가 종종 사용하는 기법은 degree assortativity 입니다. 이것은 서로 연결된 노드쌍에 대해서 각 노드의 degree 에 대한 상관관계를 측정한 값입니다. 쉽게 말해 degree가 높은 노드끼리 서로 연결되고, degree가 낮은 노드끼리 서로 연결되는 경향이 얼마나 강한지를 측정한 수치인데, 상관계수이기 때문에 -1 에서 1 사이의 값을 갖습니다.
예를 들어 <그림10>의 왼쪽 네트워크는 가운데 있는 노드가 나머지 대부분의 노드와 연결된 형태입니다. 따라서 가운데 노드는 degree centrality가 굉장히 높은 반면 이 노드와 연결된 나머지 노드들은 degree centrality가 1에 불과하죠. 따라서 이렇게 서로 상반된 노드끼리 연결된 구조를 갖는 네트워크는 degree assortativity가 -1에 가깝습니다.
반면, 오른쪽 네트워크는 degree centrality 가 같은 노드끼리 서로 연결되어 있는 경향이 강합니다. 따라서 이런 네트워크의 degree assortativity 를 측정하면 1에 가까운 값을 갖습니다.
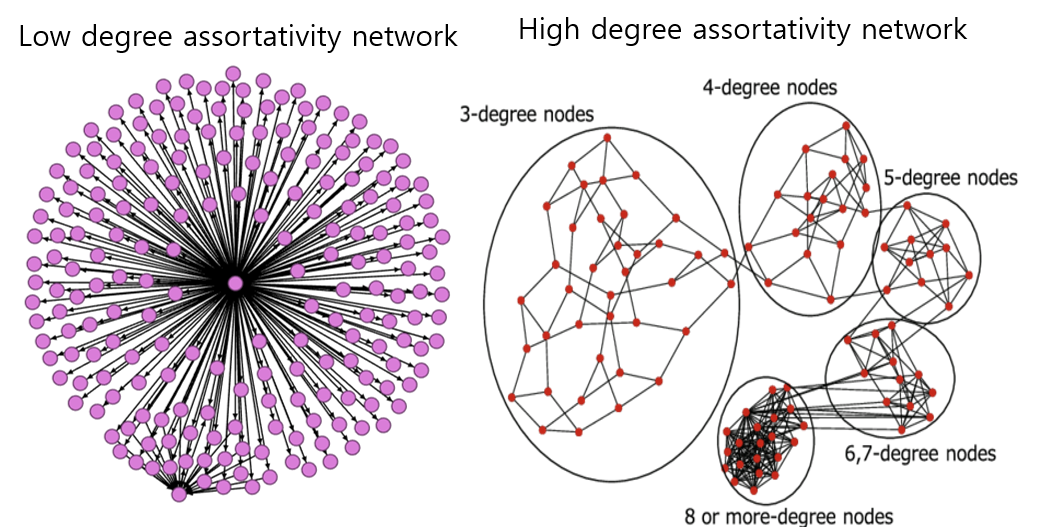 그림 10. degree assortativity가 낮은 네트워크(왼쪽)와 높은 네트워크(오른쪽) 예시
그림 10. degree assortativity가 낮은 네트워크(왼쪽)와 높은 네트워크(오른쪽) 예시
2.3. Community detection
마지막으로 소개할 기법은 ‘커뮤니티 탐지’ 입니다. 이것은 쉽게 말해 전체 네트워크를 연결 밀도가 상대적으로 높은 소집단끼리 묶는 것을 말합니다. 네트워크 이론에서는 이렇게 다른 집단에 비해 상대적으로 연결 밀도가 높은 노드 집단을 ‘community’라고 부릅니다. 그래서 전체 네트워크에서 이런 노드 집단들을 찾는 기법을 ‘커뮤니티 탐지’ 라고 부르죠. <그림 11>은 하나의 네트워크 구조를 세 개의 커뮤니티로 구분한 예입니다.
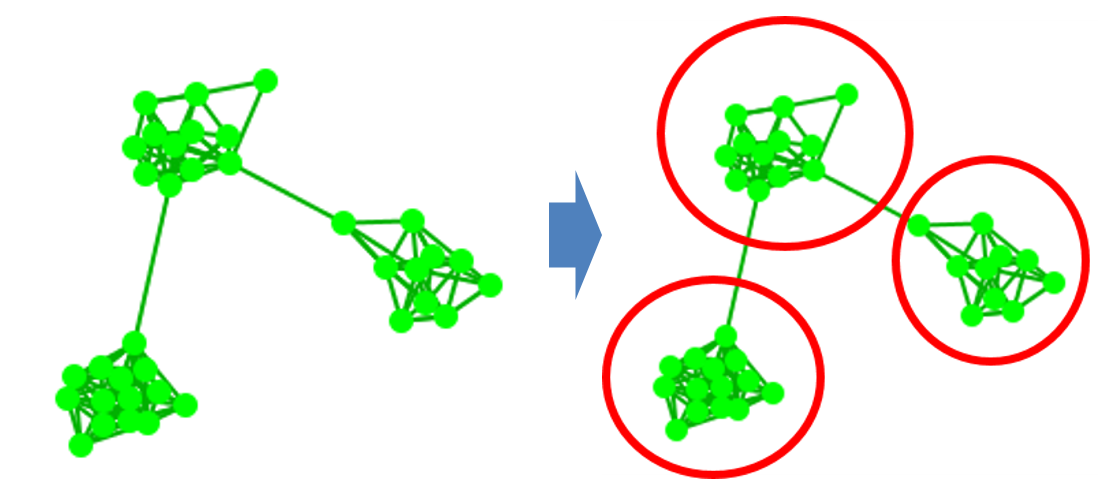 그림 11. 커뮤니티 탐지 예시
그림 11. 커뮤니티 탐지 예시
만약 분석하고자 하는 네트워크의 규모가 커서 분석해야 할 노드 개수가 많고 구조도 복잡할 때는 이렇게 커뮤니티 탐지 기법을 이용해 좀 더 작은 여러 개의 소집단으로 묶은 후 커뮤니티 단위로 분석하는 것이 좋을 때가 많습니다. 더 나아가 각 커뮤니티의 구조 및 각 커뮤니티에 속한 노드들의 평균적인 특징을 구해 커뮤니티 간의 차이를 분석할 경우 전체 구조에서는 발견하기 힘든 여러 가지 정보를 얻을 수 있기 때문에 커뮤니티 탐지 기법은 잘 알아 두시면 많은 도움이 됩니다.
참고로 커뮤니티 탐지 알고리즘은 다양한 종류가 있습니다. 당연히 각각의 장단점이 있을텐데, 저는 Clauset 등이 2004년에 발표한 알고리즘 (https://arxiv.org/abs/cond-mat/0408187) 을 가장 많이 사용합니다. 속도도 빠르고 커뮤니티 분류도 잘 되며 동일한 네트워크에 대해서는 항상 동일한 결과를 내주는데, 심지어 igraph 라는 라이브러리에서 이 알고리즘을 제공하기 때문에 편하게 쓸 수 있습니다. 게다가 igraph 는 무려 파이썬과 R과 C를 지원합니다!
3. 네트워크 기법 적용 사례
3.1. 구글의 페이지랭크
네트워크 이론을 실전에 적용하여 가장 성공한 사례 중 하나를 꼽자면 구글을 예로 들 수 있습니다. 구글 이전에 검색 회사들은 어떤 검색 결과를 가장 상위에 보여줄지를 판단하기 위해 각 웹페이지를 구성하는 하위 요소를 분석하는데 집중했습니다. 웹 페이지에 담긴 텍스트나 제목, 이미지, 혹은 페이지 구성 등의 요소를 분석하고 비교한 것이죠.
그런데 구글은 ‘하이퍼 링크’를 통해 연결된 웹 페이지들의 네트워크 구조를 이용해 중요도를 측정하는 ‘페이지 랭크’라는 알고리즘을 이용했습니다 (<그림 12> 참고). 그리고 이 ‘페이지 랭크’는 위에서 소개한 노드 중요도 측정 방식 중 하나인 ‘eigenvector centrality’의 응용 버전입니다.
![]() 그림 12. 구글의 페이지 랭크 설명 예시
그림 12. 구글의 페이지 랭크 설명 예시
3.2. 악성코드 탐지
네트워크 분석은 악성 코드 탐지에도 사용될 수 있습니다. 악성 코드는 (당연히) 탐지가 되는 것을 피하기 위해 찾기 어려운 위치에 정체를 숨기는 로직이 들어가 있습니다. 따라서 그냥 감염된 컴퓨터의 프로세스나 파일들을 일일이 검사하여 탐지하기는 쉽지 않습니다.
그런데 보통 공격자들은 악성코드를 통해 서버나 PC를 감염시키고 나면 이런 여러 대의 컴퓨터를 제어하거나 감염된 컴퓨터의 상태를 확인하기 위해 통신을 주고 받습니다. 따라서 컴퓨터 간의 통신 네트워크를 분석해보면 감염된 컴퓨터들은 <그림13>처럼 서로 혹은 공격자가 관리하는 중앙 컴퓨터와 연결된 네트워크 구조를 갖습니다. 그런데 이런 구조는 일반 컴퓨터들이 연결되는 네트워크 구조와 뚜렷한 차이를 보이는 경우가 많습니다. 따라서 이런 차이를 통해 악성 코드에 감염된 것으로 추정되는 기기들을 좀 더 쉽게 판별할 수 있죠.
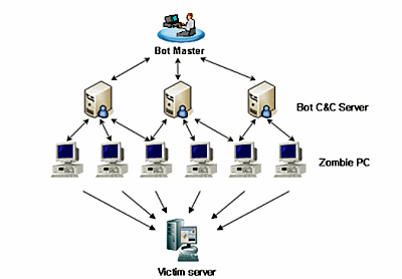 그림 13. 악성 코드 감염 컴퓨터들의 통신 네트워크 예시
그림 13. 악성 코드 감염 컴퓨터들의 통신 네트워크 예시
3.3. 온라인 게임 유저 분석
제가 생각하기에 온라인 게임, 특히 MMORPG 장르는 네트워크 분석이 가장 빛을 발할 수 있는 분야 중 하나입니다. 왜냐하면 MMORPG는 게임 내에서 여러 캐릭터끼리 서로 아이템을 주고 받거나, 전투나 채팅 등의 다양한 상호 작용이 이뤄질 뿐만 아니라 친구 관계나 길드 혹은 혈맹이라고 부르는 사회 조직을 구성하여 활동하는 등의 컨텐츠를 제공하기 때문이죠. 이런 것들은 모두 네트워크 분석에 잘 들어맞는 대상입니다.
반대로 생각해 보면, 바로 이런 특징을 갖고 있기 때문에 유저들을 정확히 분석하려면 단지 유저 개개인의 행동 패턴만 분석해서는 안되며 유저 간의 관계 구조에 대한 네트워크 분석이 대단히 중요합니다. 그렇기 때문에 엔씨소프트에서는 유저 세그먼테이션이나 이탈 예측, 악성 유저 탐지 등의 작업을 할 때 앞서 소개한 다양한 네트워크 분석 기법을 통해 추출한 특징들을 모델링에 활용합니다.
4. 네트워크 분석 도구
제가 네트워크 분석을 위해 사용하는 도구는 크게 두 가지 입니다. 하나는 ‘igraph (http://igraph.org/)’ 라고 하는 네트워크 분석용 라이브러리이고 다른 하나는 ‘gephi (https://gephi.org/)’ 라고 하는 네트워크 시각화 및 탐사 분석용 도구입니다 (참고로 제가 이 연재글을 작성할 때 사용한 네트워크 이미지의 거의 대부분은 gephi 를 이용하였습니다). 둘 다 이미 유명한 도구이기 때문에 구체적인 사용 방법은 인터넷에 많은 자료가 공개되어 있습니다. 이 외에 igraph 와 함께 사용하면 좋은 패키지를 소개하자면, 우선 tidygraph 라는 패키지가 있습니다. igraph 를 tidyverse 문법을 이용해서 사용할 수 있어서 데이터 처리할 때 좀 더 편하게 코딩할 수 있습니다. 또 ggraph 라는 패키지는 ggplot2 와 유사한 문법을 이용해서 네트워크 시각화를 할 수 있는 라이브러리입니다.
위에서 소개한 도구들에 대한 튜토리얼 자료를 몇 가지 추천하면 다음과 같습니다.
- igraph 튜토리얼: http://kateto.net/networks-r-igraph
- gephi 튜토리얼: https://www.slideshare.net/gephi/gephi-quick-start
- tidygraph 튜토리얼: https://www.data-imaginist.com/2017/introducing-tidygraph/
- ggraph 튜토리얼: https://www.data-imaginist.com/tags/visualization/
5. 중간 정리
지금까지 네트워크 분석에 대한 개략적인 내용을 소개했습니다. 정리하자면, 네트워크 분석은 우리가 데이터 분석을 할 때 대개 개체 단위의 분석에 치중하다보면 빠지기 쉬운 ‘환원주의 오류’를 방지하는 역할을 해줍니다. 따라서 데이터를 분석할 때 개체에 대한 분석과 함께 개체 간의 관계를 분석하는 네트워크 분석 기법을 함께 이용하면 좀 더 풍부한 정보를 얻을 수 있으며 이를 통해 좀 더 정확한 모델링이 가능합니다.
실제 다양한 분야에서 이런 네트워크 분석을 활용하고 있는데 온라인 게임 분야 역시 네트워크 분석이 잘 활용될 수 있는 분야입니다. 그럼 다음 글에서는 구체적으로 어떤 식으로 네트워크 분석 기법을 활용하고 있는지 사례를 들어 설명하겠습니다.