
실전 이탈 예측 모델링을 위한 세 가지 고려 사항 #1
by DANBI
0. 시작하며
최근 몇 년간 이탈 예측 모델링 관련 업무를 하고 있습니다. 공식적으로 프로젝트를 진행하거나 팀 내부적으로 조사 및 연구를 진행한 적도 있고, 경진 대회를 통해 다양한 참가자들의 결과물을 심사하기도 했죠. 하지만 아쉽게도 여전히 이탈 예측 모델 결과를 실제 서비스에 적용하지는 못하고 있습니다.
이렇게 다양한 방법을 시도하고 실패하면서 몇 가지 큰 교훈과 깨달음을 얻었는데, 크게 아래와 같이 세 가지로 정리할 수 있겠습니다.
- 예측 모델의 목표는 오차를 최소화하는 것이 아니다 (기대 이익을 최대화하는 것이다).
- Concept drift는 모델링 전반에 걸쳐 고려해야 할 문제이다 (모델의 유지 보수에서만의 문제가 아니다).
- 예측 모델링과 인과 추론 모델링은 다르다 (모델을 통해 알고자 하는 바에 따라 다른 접근 방법이 필요하다).
비록 ‘이탈 예측’ 이라는 분야로 한정하긴 했지만 아마 기계 학습을 실전에 활용하려는 다른 많은 분야에서도 고려해 볼만한 요소이지 않을까 생각합니다. 이 글에서는 이 세 가지 깨달음을 정리해 보겠습니다.
1. 예측 모델의 목표는 오차를 최소화하는 것이 아니다.
현재 대부분의 경우 기계 학습 모델을 만들 때 라벨 정보와 예측 결과 사이의 오차를 최소화하는 것을 목표로 학습합니다. 그래서 모델의 성능을 측정할 때 RMSE 나 accuracy 혹은 F1 score 같은 예측치와 실측치 사이의 오차를 측정하는 방법을 사용합니다.
그러나 실제 서비스에서 예측 모델을 사용하는 본질적인 목적은 정답을 잘 맞추겠다가 아니라 예측 모델을 실전에 적용함으로써 이익을 얻겠다 입니다. 따라서 실제 예측 모델이 목표로 해야할 것은 오차를 최소화하는 것이 아니라 모델 적용을 통해 기대되는 이익을 최대화하는 것이죠 (참고로 이익이 꼭 돈을 의미하는 것은 아닙니다). 물론 오차를 최소화하는 것이 곧 기대 이익을 최대화하는 것과 동일한 경우도 많습니다. 그러나 이 두 가지 목표를 동일시해서는 안됩니다. 적어도 ‘이탈 예측’ 에서는 그렇습니다.
좀 더 구체적인 설명을 위해 [그림 1]과 같은 시나리오를 한번 생각해 보죠.
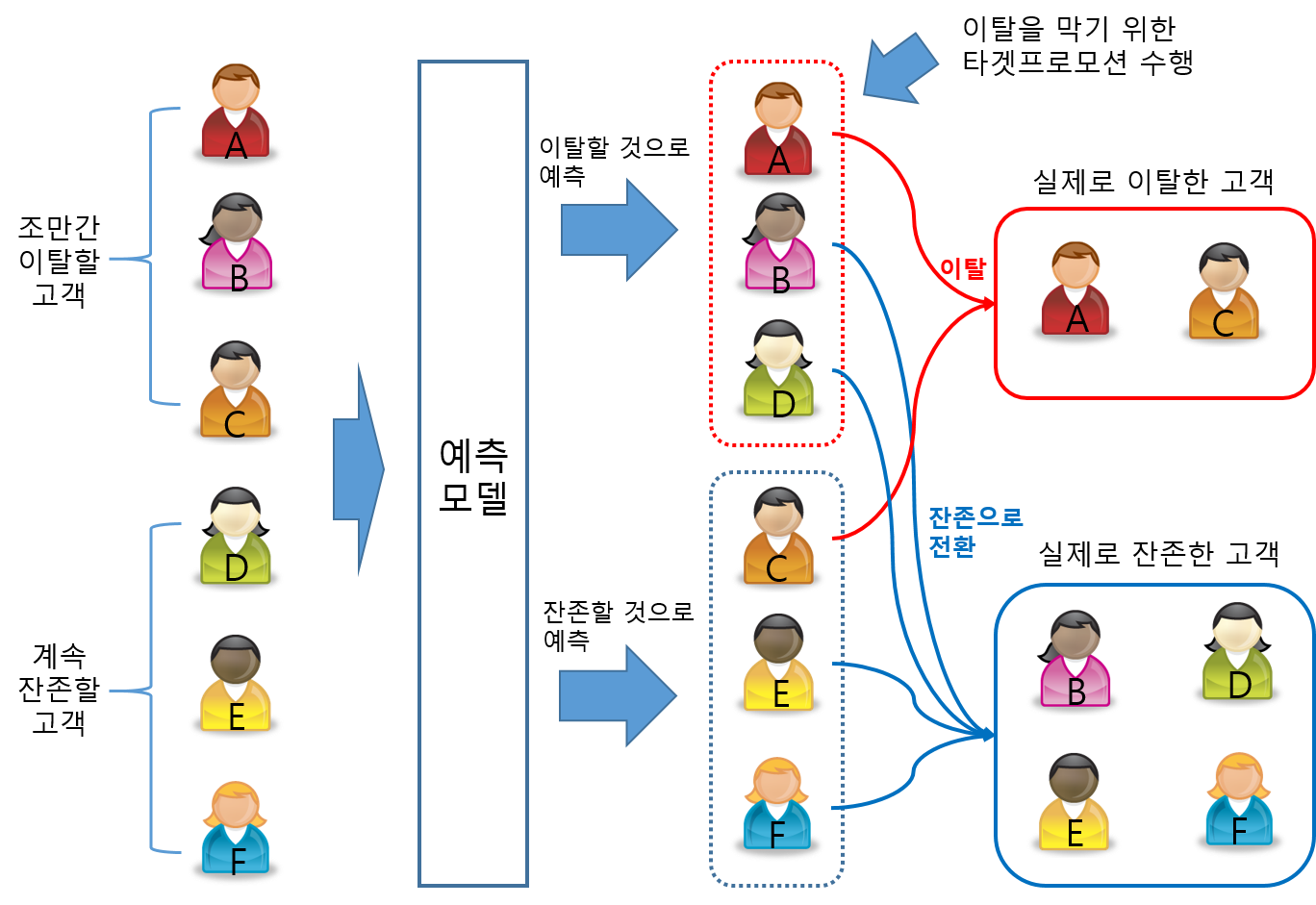 [그림 1] 이탈 예측 모델을 이용한 프로모션 시나리오
[그림 1] 이탈 예측 모델을 이용한 프로모션 시나리오
A 부터 F 까지 여섯 명의 고객이 있습니다. A, B, C 는 각자 어떤 이유로 인해 조만간 더 이상 우리 서비스를 이용하지 않고 이탈하려는 고객입니다. 그리고 D, E, F 는 서비스에 만족하고 있어서 계속 이용하려는 고객이고요. 예측 모델은 이런 고객들의 여러 가지 특성들을 분석해서 조만간 이탈할 것으로 추정되는 고객과 그렇지 않은 고객을 분류합니다. 그런데 이 예측이 100% 정확하기는 현실적으로 거의 불가능하기 때문에 약간의 오차 (사실은 상당한 오차) 가 발생할 수 있습니다. 가령 위 예측 모델은 A, B, D 가 이탈할 것이라고 예측했는데, 이런 경우 A 와 B 는 실제 이탈할 생각이 있었으니 정확히 예측했지만 D 는 잘못 예측했죠. 이것을 각각 ‘true positive (TP)’ 와 ‘false positive (FP)’ 라고 부릅니다. 한편, E 와 F 는 이탈할 생각이 없는 고객이며 예측 모델 역시 이탈할 고객이 아니라는 것을 정확히 예측했습니다. 하지만 C 의 경우 이탈할 생각을 하고 있지만 예측 모델이 이것을 제대로 탐지하지 못했죠. 이 경우에는 E 와 F 를 ‘true negative (TN)’ 라고 부르며 C 를 ‘false negative (FN)’ 라고 부릅니다. 우리말로는 보통 TP 와 TN 을 ‘정탐 (정확히 탐지함)’ 이라고 부르며, FP 는 ‘오탐 (잘못 탐지함)’, FN 은 ‘미탐 (탐지하지 못함)’ 이라고 부릅니다.
- A 와 B - true positive, TP
- C - false negative, FN
- D - false positive, FP
- E 와 F - true negative, TN
이제 마케팅 부서에서는 예측 모델 결과를 토대로 A, B, D 고객에게는 마음을 돌리기 위한 어떤 보상 조건을제시하거나 혹은 타겟팅된 광고를 노출할 수 있습니다. 그런데 이런 광고나 프로모션이 항상 성공하는 것은 아닙니다. 어떤 고객은 이런 프로모션에 반응해 좀 더 서비스를 이용해 보기로 생각할 수 있겠지만 어떤 고객은 원래 생각대로 이탈할 것입니다. 위 시나리오에서 B 는 마음을 바꿔 잔존했고, A 는 프로모션에 반응하지 않고 그대로 이탈했습니다. 이렇게 어떤 프로모션에 반응하는 비율을 ‘전환율 (conversion rate)’ 이라고 부릅니다.
한편, C 는 예측 모델이 이탈할 것을 예측하지 못했기 때문에 방치되었고 그래서 그대로 이탈해 버립니다. 반면 D 고객은 원래 이탈할 생각도 없었는데 예측 모델이 이탈할 것이라고 잘못 예측한 덕분에 프로모션을 통해 어떤 보상을 거저 받을 수 있습니다. 그런데 프로모션이나 광고에는 비용이 발생합니다. 이 비용에는 고정 비용도 있겠지만 대상 규모가 커짐에 따라 커지는 단가 개념이 적용되는 비용도 있습니다. 따라서 D 와 같은 고객이 많아지면 이탈 방지를 통한 기대 이익이 줄어들 것입니다.
더 나아가 각 고객이 발생시키는 기대 가치는 저마다 다릅니다. 가령, C 고객이 매우 큰 매출을 발생시키는 VIP 고객이었다면, 이탈을 탐지하지 못해 발생하는 손실은 C 고객이 평균적인 매출을 발생시키는 고객일때에 비해 훨씬 클 것입니다.
이제 위 시나리오를 토대로 이탈 방지를 위한 프로모션을 도입했을 때 예상되는 비용과 이익을 도식화하여 표현하면 [그림 2]와 같습니다. 아래 도식에서 ‘\(\gamma\) (감마)’는 전환율을 의미하며, \(CLV\) 는 고객에 대한 기대 가치, \(C\) 는 프로모션 비용을 의미합니다. 이탈할 것이라고 예측한 TP 와 FP 에는 프로모션 비용이 발생합니다. FP (위 시나리오에서 D 고객) 는 원래 프로모션과 상관없이 잔존하는 고객이기 때문에 추가적인 이득은 없이 비용만 낭비됩니다. 한편 FN (C 고객) 이나 TN (E 와 F 고객) 은 그대로 방치된 고객이므로 비용과 이익 모두 발생하지 않습니다. TP (A 와 B 고객) 는 원래 이탈하려는 고객이었기 때문에 프로모션을 통해 잔존으로 전환되는 비율 (\(\gamma\)) 만큼의 이익이 발생하는데, 이 때의 이익은 원래의 고객 가치 (\(CLV\)) 에서 프로모션 비용 (\(C\)) 을 제한 만큼이 됩니다.
[그림 2] 이탈 예측 모델에 대한 비용 편익 다이어그램
결국 이탈 예측 모델을 실전에 적용하여 잔존율을 높이기 위한 프로모션을 수행하게 되면 모델의 예측 정확도 뿐만 아니라 기대 가치와 프로모션 비용, 전환율 등을 모두 고려해야 본질적으로 추구하는 기대 이익을 계산할 수 있습니다. 이를 수식화하면 다음과 같으며, 이탈 예측 모델의 최종 목표는 이 값을 최대화하는 것이 되어야 합니다.
\[Profit = CLV(\gamma \times TP) - C(TP+FP)\]이 값(\(Profit\))을 크게 하려면 TP 를 높이거나 FP 를 줄이는 것도 중요하지만 비용을 줄이거나 전환율을 높이거나 혹은 기대 가치가 큰 고객의 이탈 징후를 잘 탐지하는 것도 중요합니다. 예측 모델을 만드는 데이터 분석가의 입장에서 전환율이나 마케팅 비용을 제어하기는 불가능하지만, 대신 기대 가치가 큰 고객의 이탈 징후를 잘 탐지하는 것을 목표로 예측 모델을 만들 수 있습니다.
저희 팀에서 작년에 IEEE Transactions on Games에 발표한 논문(https://ieeexplore.ieee.org/document/8485736)에서는 기대 이익을 고려하여 예측 대상을 선정하고 모델 성능을 평가하는 방법을 제안하고 있습니다. 이탈 예측 모델을 만들고 이를 적용할 때 전체 고객을 모두 예측 대상으로 활용하는 것이 아니라 소수이지만 기대 이익이 큰 고객으로 대상을 한정하는 것이죠. 이렇게 하면 이탈 징후를 찾기 힘든 소수의 데이터만 사용하게 되어 예측 정확도 측면에서는 손해를 봅니다. 그러나 프로모션 비용을 고려하면, 프로모션 단가보다 낮은 기대 가치를 갖는 고객의 이탈을 예측하는 것은 원래의 목표에 맞지 않습니다. 즉, 프로모션 비용 대비 기대 가치가 큰 고객에 집중하면 정확도는 떨어지더라도 기대 이익은 높은 모델을 만들 수 있을 것입니다.
[그림 3]은 위에서 정의한 평가식을 이용해 이런 가설을 실험으로 검증한 자료입니다. 표에서 ‘Test set I’ 이 전체 고객을 대상으로 샘플링한 자료로 이탈 예측 모델을 만들어 테스트한 결과이고 ‘Test set II’ 은 \(CLV\) 가 높은 고객을 선별하여 모델을 만들어 테스트한 결과입니다. 예측 성능을 측정한 ‘accurary’, ‘precision’, ‘recall’, ‘F1 score’, ‘AUC’ 항목을 보면 ‘Test set I’ 이 ‘Test set II’ 에 비해 모든 면에서 훨씬 높은 값을 기록했습니다. 그러나 전환율이나 프로모션 비용을 고려하여 기대 이익을 측정할 경우 ‘Test set I’ 은 프로모션 비용이 없거나 매우 낮게 책정했을 경우를 제외하면 기대 이익은 커녕 오히려 손해를 보는 것으로 나옵니다. 반면 ‘Test set II’ 는 대부분의 시나리오에서 높은 기대 이익이 예상됩니다.
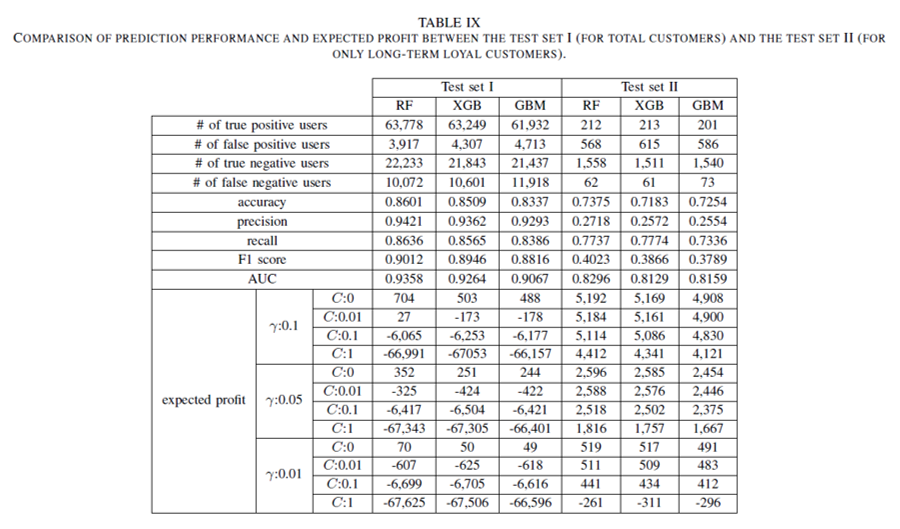 [그림 3] 고객 전체에 이탈 예측 모델을 적용한 경우 (Test set I) 와 기대 이익이 큰 고객 집단만 선별하여 예측 모델을 적용한 경우 (Test set II) 에 대한 예측 성능과 기대 이익 비교 결과표
[그림 3] 고객 전체에 이탈 예측 모델을 적용한 경우 (Test set I) 와 기대 이익이 큰 고객 집단만 선별하여 예측 모델을 적용한 경우 (Test set II) 에 대한 예측 성능과 기대 이익 비교 결과표
그렇다면, 아예 학습 단계에서 기대 이익을 최대로 하는 예측 모델을 만들도록 최적화 함수를 정의할 수는 없을까요? 실제 이런 접근 방법을 제안한 논문이 있습니다. ‘Profit optimizing customer churn prediction with Bayesian network classifiers (https://content.iospress.com/articles/intelligent-data-analysis/ida00625)’ 는 바로 이렇게 기대 이익을 최대로 하는 분류기를 만드는 기법을 제안한 논문입니다.
정리하자면, 기계 학습 모델을 실전에 적용할 때는 모델 적용을 통해 기대되는 이익이 무엇인지를 명확히 정의하고, 이렇게 정의된 기대 이익을 높이는 것을 목표로 한 예측 모델링 및 평가가 이뤄져야 합니다.