
데이터 분석을 통해 하둡 시스템 개선하기 #1
by DANBI
이번 포스팅에서는 기존에 언급된 적 없는 새로운 주제에 대해 이야기해볼까 합니다. 저희 I&I실에서는 게임 데이터 분석뿐 아니라 사내에 쌓이고 있는 각종 데이터를 이용하여 내부 업무나 시스템을 개선하기 위한 분석 프로젝트도 진행하고 있습니다. 그 중 저희가 데이터 분석을 위해 사용하고 있는 하둡(Hadoop) 시스템의 효율화를 위해 최근에 진행했던 분석 프로젝트를 소개하려 합니다.
1. 분석의 배경 및 목표
a. 하둡 (Hadoop) 이란?
하둡은 대규모 데이터를 안정적이고 효율적으로 적재하고 가공하기 위한 분산 시스템입니다. 엔씨소프트 데이터센터에서는 2008년에 처음 하둡을 도입한 이후 지금까지 여러 차례의 인프라 확장 및 개선을 거쳐 현재 약 10페타 바이트 규모의 데이터 분석 인프라를 구축하여 운영하고 있습니다.
하둡에서는 대규모 데이터를 가공하거나 분석할 때 여러 개의 데이터 조각으로 나눈 후 여러 대의 서버에 분산 할당하여 작업을 처리한 후 결과를 취합하는 방식을 사용합니다. 이렇게 하나의 작업을 여러 개로 쪼갠 작은 단위의 작업을 하둡에서는 task 라고 부릅니다. 즉, 하둡은 하나의 작업을 적게는 수십 개에서 많게는 수천 혹은 수만개의 task 로 나눈 후 수백 대의 서버에 분산하여 처리합니다.
그런데 보통 해야 할 일은 많고 시간은 부족한 것이 직장인의 숙명이듯, 하둡 역시 시스템 자원은 한정된 반면 처리해야 할 작업은 계속 들어옵니다. 2019년 12월 기준으로 저희 하둡 시스템에서 하루에 처리하는 작업 수는 약 11만개 정도 되는데, 이건 task 기준으로 보면 수백만 개가 넘는 엄청난 양이죠. 때문에 작업의 규모나 중요도에 따라 적절하게 시스템 자원을 할당하는 것이 중요합니다. 단순히 요청이 들어온 순서대로 작업을 할당할 경우 자칫 더 빨리 처리해야할 중요한 작업이 계속 지연되는 문제가 생길 수 있죠. 그래서 저희는 작업의 중요도나 성격에 따라 차등적으로 자원을 할당할 수 있는 ‘capacity scheduler’ 라는 것을 사용합니다.
b. Capacity Scheduler?
Capacity scheduler의 동작 방식을 이해하기 위해 은행 창구를 예로 들어보겠습니다.
은행에 가면 보통 여러 개의 창구가 있는데, 크게 대출 관련 업무를 전담하는 창구와 일반 업무를 전담하는 창구가 분리되어 있고 대기 번호표를 뽑는 기계 역시 구분되어 있습니다 (그리고 신기하게도 항상 내가 보려는 은행 업무 대기 인원이 다른 쪽 대기 인원보다 많은 법칙이 있죠).
만약 일반 업무 목적의 고객이 많이 몰려서 대기 인원이 많아지고 대출 관련 업무 목적의 고객이 없어서 해당 창구가 여유가 될 때는 보통 고객의 불편을 최소화하기 위해 대출 창구에서도 일반 업무를 분담하여 처리하기도 합니다.
 <그림 1> 먼저 오신 고객님의 용건이 다 끝나면 봐드릴게요~
(이미지 출처: <http://m.fnnews.com/news/201801301728473557>)
<그림 1> 먼저 오신 고객님의 용건이 다 끝나면 봐드릴게요~
(이미지 출처: <http://m.fnnews.com/news/201801301728473557>)
Capacity scheduler의 동작 방식은 위에서 설명한 은행 창구의 업무 처리 방식과 매우 유사합니다. 은행에서 업무 종류에 따라 창구를 구분하듯이 capacity scheduler를 사용하는 하둡 시스템은 실행 예정인 작업이 대기하는 큐를 여러 개로 분리해 놓고 각 큐 별로 task를 수행할 때 사용할 수 있는 시스템 자원을 배분합니다 (각 큐에서 사용할 수 있는 시스템 자원 비율은 운영자가 설정합니다). 작업을 요청할 때는 내 작업이 어떤 큐에 할당되길 원하는지 알려주는 태그를 달기 때문에 해당 태그를 보고 그에 맞는 큐에 작업을 할당합니다.
만약 특정 큐에 쿼리 작업이 몰릴 시에 다른 유휴 큐의 리소스를 사용하는 fair scheduling 정책도 같이 병행합니다. 하지만 전체 시스템이 바쁘게 돌아가고 있는 상태라면 각 큐에 할당된 비율만큼만 시스템 자원을 쓸 수 있기 때문에, 시스템 운영자는 특정 큐에 병목 현상이 발생하지 않도록 업무의 중요도와 평소 처리되는 작업량에 맞게 각 큐의 시스템 자원 비율을 설정해야 합니다.
c. 하이브(Hive)와 데이터웨어하우스(Data warehouse)
하이브는 데이터 분석가들이 하둡을 좀 더 쉽게 사용할 수 있도록 프로그래밍 언어 대신 SQL을 이용해 데이터 추출 및 분석 업무를 할 수 있게 만든 도구입니다. 하둡에 적재된 데이터들을 테이블 형태로 만들어 놓으면 분석가나 게임 개발/사업/운영 담당자들은 SQL쿼리를 통해 여러 개의 테이블을 조합하거나 그룹별로 집계하여 원하는 자료를 직접 추출할 수 있죠.
더 나아가 엔씨소프트 데이터센터에서는 분석가들이 하이브를 좀 더 편하게 사용할 수 있도록 웹 기반의 쿼리 실행 도구와 정기적인 반복 작업을 자동으로 실행할 수 있는 스케쥴링 서비스를 제공하고 있습니다. 이를 통해 회사의 다양한 부서에 있는 수십 명의 게임 서비스 담당자들이 매일 수천 개 이상의 쿼리를 실행하고 있죠.
그런데 분석에 사용되는 원천 데이터는 대개 서비스 운영에 적합한 형태로 구성되어 있는 반면, 데이터 분석 목적으로 사용하기에는 다소 불편한 경우가 많습니다. 비록 하이브를 이용하면 쉽게 데이터를 추출할 수 있다고는 하지만, 원천 데이터가 불편한 구조로 되어 있어 간단한 집계를 위해 복잡한 쿼리를 작성해야 한다면 비효율적이겠죠. 따라서 원천 데이터를 그대로 활용하기 보다는 분석에 용이한 형태로 미리 가공하여 적재해 놓는 것이 좋습니다.
그래서 보통 분석 목적으로 데이터를 활용하는 많은 회사들이 원천 데이터를 적재하기 전에 분석이나 집계에 좀 더 용이한 형태로 변환하기 위한 전처리 작업을 진행하고 있으며 이것을 ETL (Extract, Transform, Load) 이라고 부릅니다. 그리고 이렇게 ETL을 통해 (운영이 아닌) 분석에 적합한 형태로 가공한 테이블들의 묶음을 ‘데이터웨어하우스’ 라고 부릅니다.
일반적으로 데이터웨어하우스는 한번 구축하면 다양한 분석에 여러 번 사용되기 때문에 분석 편의성과 범용성을 모두 고려한 테이블 구조를 만드는 것이 중요합니다.
d. 분석의 목표
저희는 앞서 설명한 배경 지식을 토대로 두 가지 분석 목표를 잡았습니다.
Capacity scheduler 설정 최적화
앞서 설명했듯이 엔씨소프트 데이터센터의 하둡 시스템은 하루에 10만개가 넘는 작업을 수행하고 있습니다. 이렇게 많은 작업이 차질없이 돌아가도록 하려면 각 큐의 시스템 자원 비율을 잘 설정해야 합니다.
현재 큐 별 자원 할당량은 관리자의 경험과 직관을 바탕으로 조정되고 있었습니다. 저희는 데이터 분석을 통해 큐 별로 처리되는 작업량 패턴을 파악하면 쿼리 대기 시간을 최소화하는 스케줄링 정책을 찾는 것이 가능할 것이라 생각했습니다.
데이터 웨어하우스 테이블 구조 최적화
앞서 말씀드렸듯이 하이브로 데이터를 추출할 때는 원천 데이터 대신 이를 가공한 데이터웨어하우스를 활용합니다. 보통 서비스 단에서는 효율적인 트랜잭션 처리를 위해 용도에 따라 데이터를 여러 개의 테이블로 분리해서 관리하지만 분석을 할 때는 가급적 여러 정보가 하나의 테이블에 모여 있는 것이 편리하고 효율적입니다. 그렇다고 해서 모든 정보를 하나의 테이블에 다 합치려고 하면 ETL단계가 지나치게 비효율적이 될 수 있습니다. 더 나아가 하둡 시스템에서도 특정 테이블에 작업 요청이 몰리게 되면 분석 작업에 병목이 생길 수도 있습니다.
이미 저희는 다년 간의 운영 경험을 토대로 체계적인 데이터웨어하우스를 구축한 상태이지만, 실제 데이터웨어하우스를 이용 중인 여러 분석가들의 하이브 쿼리 이력을 분석해 보면 미처 감안하지 못했던 비효율적인 부분을 찾아 개선할 수 있으리라 생각했습니다.
2. Capacity scheduler 설정 최적화
a. 현황 파악 및 탐사 분석
분석에 앞서 현재 운영되는 스케줄링 정책을 파악했습니다. 작업의 특징에 따라 총 4개의 큐가 운영되고 있었는데 각각의 특징은 다음과 같았습니다.
Queue A - 게임 개발/사업/운영 부서에서 현황 분석 및 보고서에 사용할 데이터 집계의 하이브 쿼리 작업을 처리하는 큐. 가장 많은 사용자가 있지만 주로 업무 시간에 대부분의 쿼리 작업이 몰리며 쿼리의 복잡도가 높지 않음.
Queue B - 데이터 분석가들이 사용하는 하이브 쿼리 작업을 처리하는 큐. 주로 오전 시간에 확인하는 보고서 생성을 위해 사용되며 작업 중요도가 높은 편임.
Queue C - 데이터 웨어하우스 구축에 필요한 ETL 작업을 위한 큐. 대부분의 분석 및 서비스에 필수적인 데이터를 생성하는 작업이기 때문에 작업 중요도가 가장 높으며, 대부분의 작업이 가장 이른 새벽 시간에 발생함.
Queue D - I&I실에서 서비스하는 데이터 프로덕트에 사용되는 전처리 데이터를 추출하는 ETL 작업을 위한 큐. 프로덕트 별로 갱신되는 시간이 다르기 때문에 고른 작업 시간 분포를 갖고 있으며 작업이 지연되면 서비스 장애로 연결될 수 있어 중요도가 높은 편임.
또한 하둡 클러스터 운영팀에서는 위 4개 큐가 갖고 있는 특징을 고려하여 자원 할당 비율을 두 개의 시간대로 나눠서 관리하고 있었습니다.
Night (자정 ~ 오전 9시) - 일반적인 분석 업무나 데이터 프로덕트에서 필요한 ETL 작업을 위한 Queue C 와 D 비율을 높임
Day (오전 9시 ~ 자정) - 업무 시간에 대부분의 작업이 몰리는 Queue A 와 B의 비율을 높이고 C와 D 비율은 낮춤
이런 사전 정보를 바탕으로 실제 큐 별 시스템 자원 사용 현황을 탐사 분석한 결과 다음과 같은 개선점을 도출할 수 있었습니다.
첫째, <그림2>를 보면 알 수 있듯이, 각 큐 별, 시간대 별 시스템 사용량의 변화 패턴은 오전 9시를 기준으로 하고 있는 현재의 Night/Day 자원 할당 정책에 딱 맞지 않고 있었습니다. 따라서 큐 별 사용량 변화에 좀 더 적절한 관리 정책을 다시 정하는 것이 좋겠다고 판단했습니다.
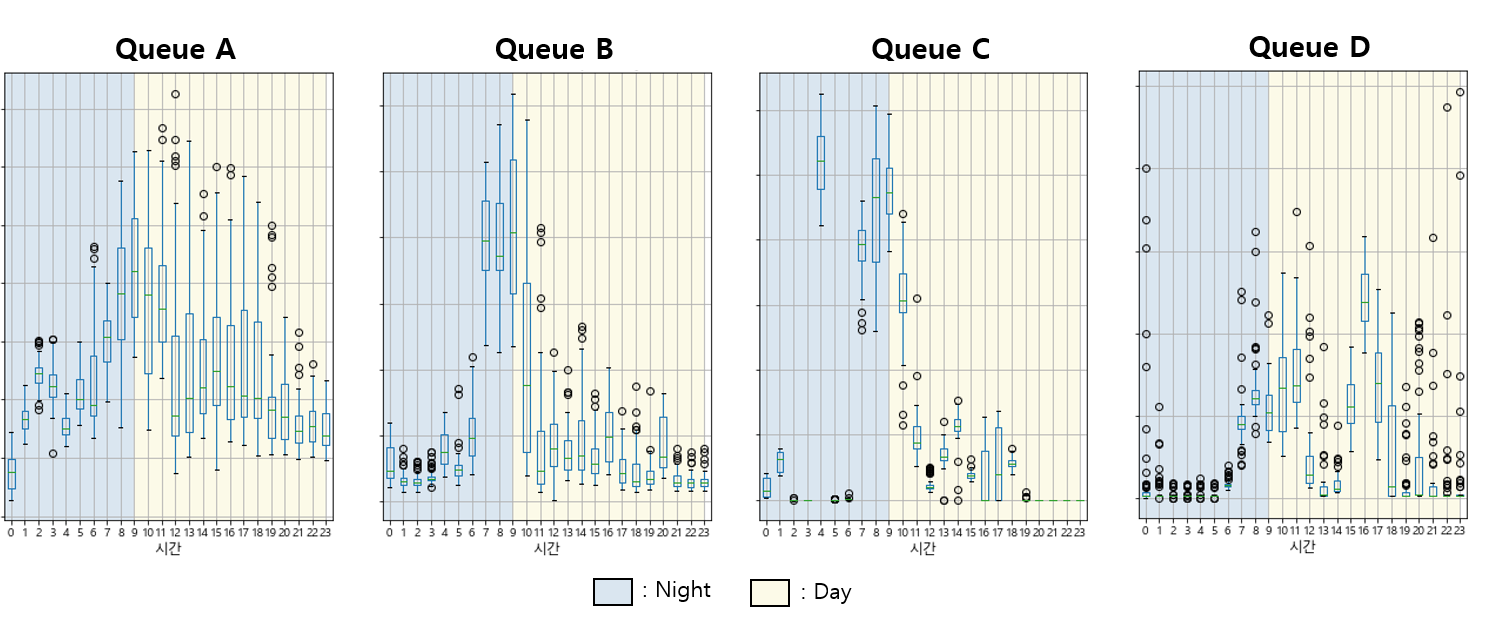 <그림 2> 시간대 별, 큐 별 시스템 사용량
<그림 2> 시간대 별, 큐 별 시스템 사용량
둘째, 현재 설정된 큐별 시스템 자원 할당 비율과 실제 사용량 비율에 차이가 있었습니다. 가령, 현재 정책에서는 Queue B의 할당 비율이 가장 컸으나 실제 사용량에서는 Queue A의 비율이 가장 높았습니다 (그림 3 참조). 물론 중요도로 봤을 때 B에 할당되는 작업이 A보다 더 중요한 작업이기 때문에 이것을 감안한 정책이긴 했지만 현재의 할당 비율이 적절한지 데이터 분석을 통해 확인해 볼 필요가 있겠다고 생각했습니다.
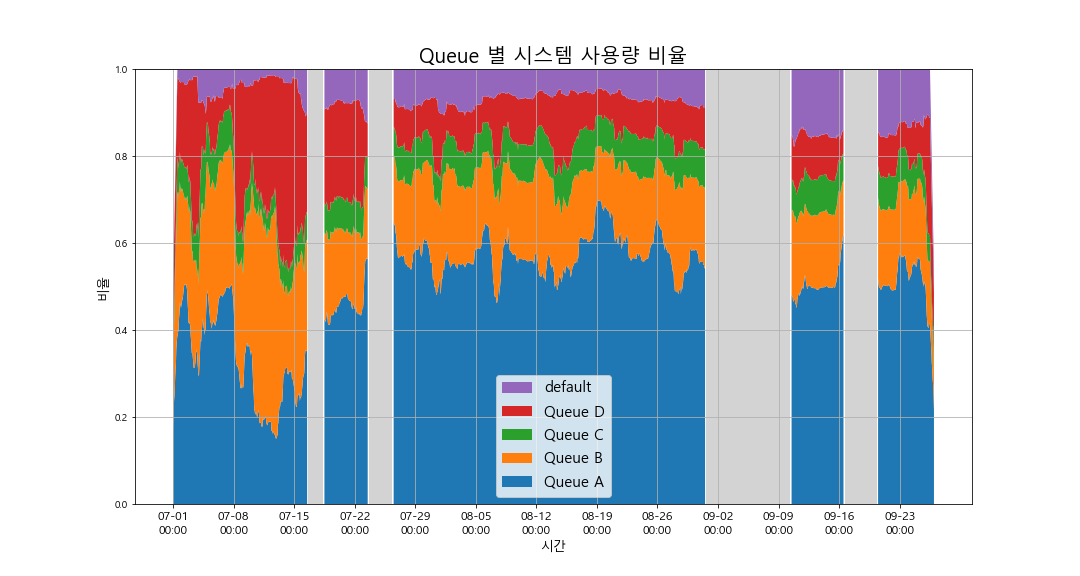 <그림 3> 시간대 별, 큐 별 시스템 사용 비율 (작업 요청 시 큐를 지정하지 않으면 default 큐로 할당됨)
<그림 3> 시간대 별, 큐 별 시스템 사용 비율 (작업 요청 시 큐를 지정하지 않으면 default 큐로 할당됨)
b. 큐별 자원 할당 비율 최적화
우선 Night/Day 시간대로 나누고 있는 현행 정책 대신 큐별로 사용량이 가장 높은 시간대를 고려하여 4개의 시간대 (자정 ~ 오전 6시, 오전 6시 ~ 12시, 오전 12시 ~ 오후 6시, 오후 6시 ~ 자정) 로 더 세분화하는 방식을 제안했습니다.
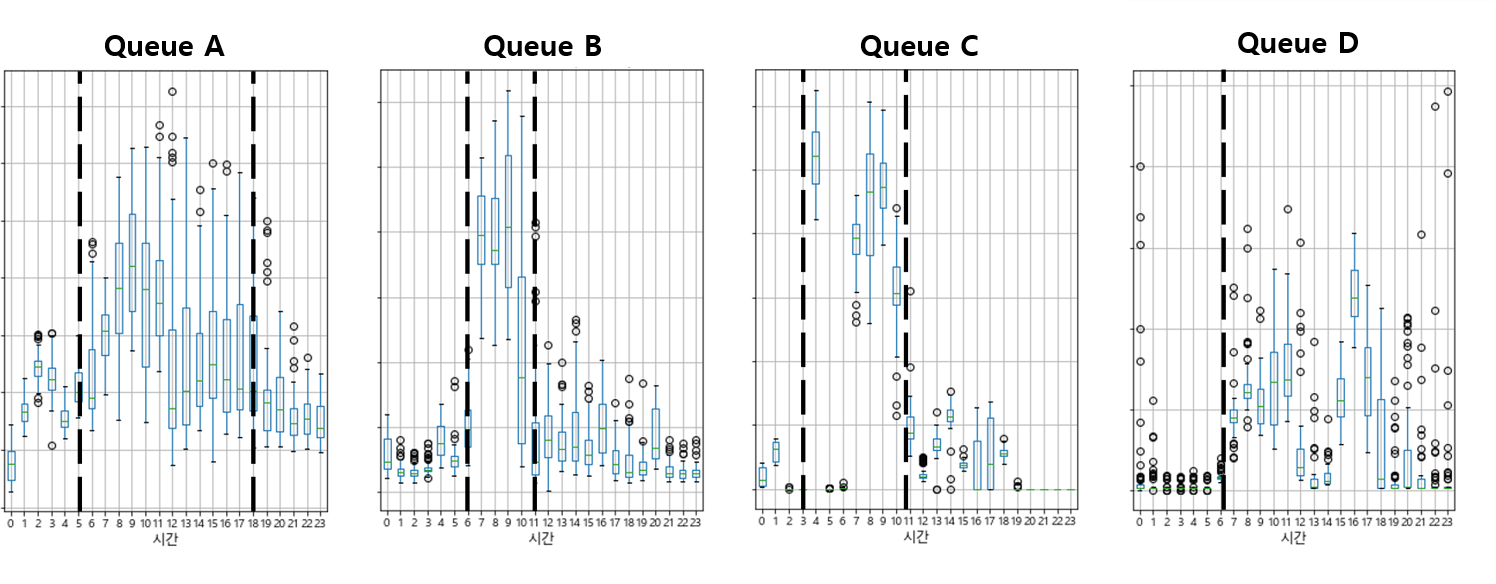 <그림 4> 큐 별 사용량이 가장 높은 시간대
<그림 4> 큐 별 사용량이 가장 높은 시간대
이제 이렇게 구분된 시간대를 중심으로 각 큐별로 매시간마다 할당된 현재의 자원 비율과 실제 시스템 사용 비율의 차이가 얼마나 큰지를 나타내는 ‘자원 사용 효율’ 이라는 지표를 아래와 같이 정의하였습니다.
\[자원~사용~효율 = \frac{실제~시스템에서~사용한~자원~비율}{할당된~자원~비율}\]위 수치가 1보다 크면 할당된 자원에 비해 작업 수행에 필요한 자원이 많은 (즉, 할당된 자원이 부족한) 것을 의미하며 1보다 작으면 실제 작업량에 비해 자원이 과다 할당된 상태를 의미합니다. 다시 말해, 큐별로 자원 할당 비율이 적절하다면 이 ‘자원 사용 효율’ 지표가 1에 가까운 값을 갖게 되겠죠. 이때 각 큐의 사용량을 시간대 별 사용량의 중간값으로 정의하되 중요도가 높은 Queue C와 D의 경우 시스템 자원이 부족하여 작업이 과도하게 지연되면 안되기 때문에 백분위 75%로 차등 고려했습니다.
<그림 5>의 왼쪽 그래프가 이 지표를 시간대별로 측정한 그래프인데요 보다시피 대부분의 시간대에서 큐별 ‘자원 사용 효율’ 지표가 1에서 크게 벗어나 있는 것을 확인할 수 있습니다. 특히, Queue A의 경우 대부분의 시간대에서 수행하는 작업량에 비해 할당된 자원 비율이 크게 부족한 상태였습니다.
이후 4개의 시간대를 기준으로 각 큐의 자원 할당 비율을 조정할 수 있는 모든 경우의 수를 나열한 후, 각각에 대해 ‘자원 사용 효율’ 지표를 구했을 때 시간대별 총합이 최소가 되는 정책을 찾는 최적화 로직을 작성하였습니다. 이를 수식으로 표현하면 아래와 같습니다.
\[arg\min_{k}\sum_{i=0}^{23}{\sum_{q=A}^{D}{\{f_{k,i}(q)-1\}^2}}\]위 식에서 \(f_{k,i}(q)\)는 큐\(q\)에 대해서 정책 \(k\)를 적용했을 때 \(i\)시간대에 계산된 자원 사용 효율 지표를 의미합니다. 즉, 위 식은 모든 시간대 모든 큐에 대해서 자원 사용 효율 지표와 1 사이의 차이의 총합이 최소가 되는 정책\(k\)를 찾는 최적화 수식을 의미합니다.
<그림 5>의 오른쪽 그래프는 최종적으로 찾은 자원 할당 정책을 적용할 경우 예상되는 자원 사용 효율 그래프입니다. 왼쪽 그래프에 비해 상대적으로 모든 시간대에서 전체 큐의 자원 사용 효율 지표가 1에 가깝게 몰려 있는 것을 확인할 수 있습니다.
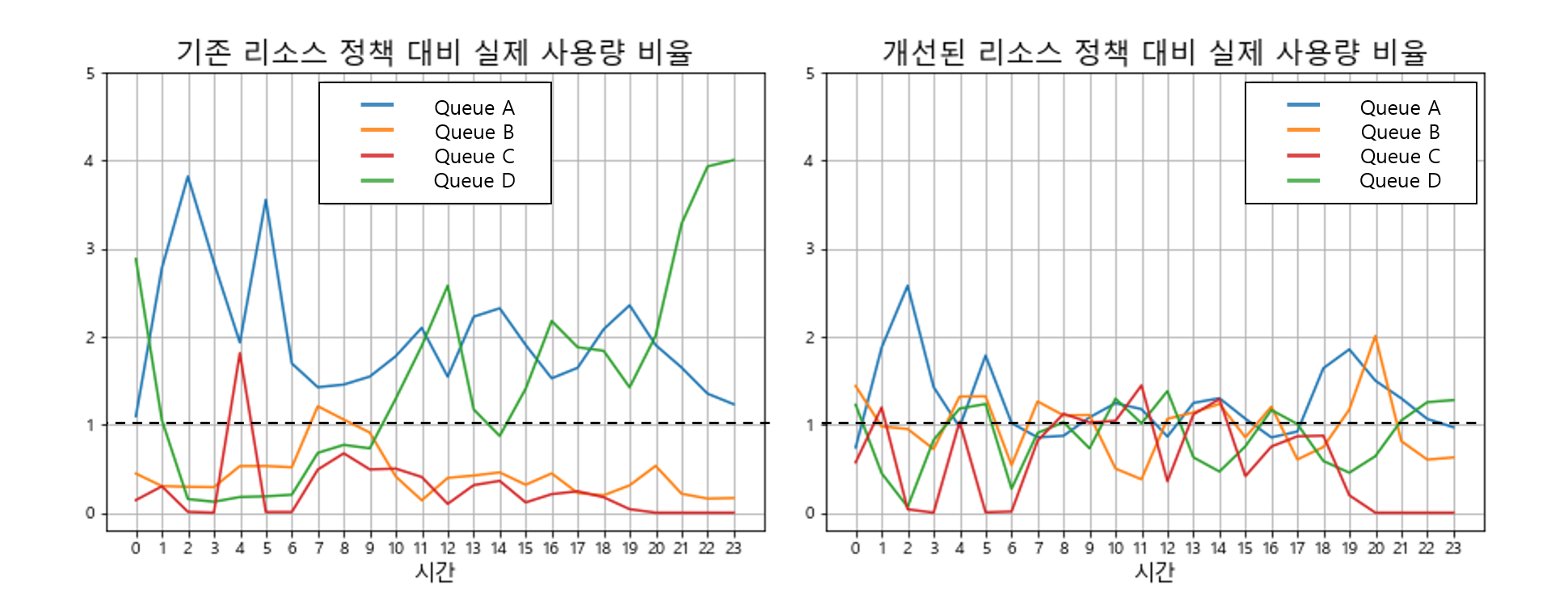 <그림 5> 시간대 별, 큐 별 자원 사용 효율 그래프
<그림 5> 시간대 별, 큐 별 자원 사용 효율 그래프
지금까지 데이터 분석을 통한 하둡 시스템 개선 프로젝트의 목적과 그 중 하나의 주제인 큐별 자원 할당 비율 최적화 분석 내용을 살펴보셨습니다. 해당 내용이 실제 적용되었을 때 시스템이 얼마나 개선되었는지에 대한 검증 내용과, 시스템 개선을 위한 두번째 주제인 데이터 웨어하우스 테이블 구조 최적화의 내용은 다음 포스트(데이터 분석을 통해 하둡 시스템 개선하기 #2)에서 찾아 뵙겠습니다.