
Snorkel을 활용해 라벨 보정하기
by DANBI
배경
이번 글은 Fraud Detection System 개발 과정 중 탐지 모델 라벨 보정 도구를 적용한 작업에 대해 소개해 드리려 합니다. 게임 서비스에서 Fraud Detection이란 매크로나 핵등의 불법 프로그램 사용이나 계정 도용과 같은 부정 행위를 탐지하는 것을 말합니다. 이러한 행위를 하는 집단을 부정 사용자라 정의하며 일반 고객에게 악영향을 끼치기 때문에 적절한 제재 조치가 필요합니다. 부정사용자 예측 모델은 이러한 제재 프로세스를 자동화 하고자 하는데에 목적이 있습니다.
라벨 신뢰도에 대한 문제의식
그러나 실제 ML 서비스를 개발하는 과정에서 라벨 정보를 확보하기 어려운 경우가 많습니다. Fraud Detection System 분야가 대표적인 경우인데, 다음과 같은 문제가 있기 때문입니다.
- 이미지나 텍스트, 음성 데이터의 라벨링과 달리 도메인 지식이 없는 비전문가 다수를 이용한 라벨링이 어렵습니다.
- 기존에 확보한 탐지 규칙이나 이력을 이용해서 학습 데이터를 만들 경우, 이미 알고 있는 탐지 규칙이나 이력을 전체 부정 행위 중 일부분에만 해당하기 때문에 나머지 데이터가 모두 정상 행위라고 단정할 수 없습니다.
- 심지어 운영 부서에서는 탐지를 회피하려는 집단에게 혼동을 주기 위해, 제재 정책을 가변적으로 시행하는 경우도 있어서 시점에 따라 라벨 데이터의 분포가 달라져 모델 학습이나 평가가 어려워집니다.
위의 이유로 부정 행위 탐지 모델을 위해 단순히 제재가 된 이력이 있는지, 없는지를 라벨 정보로 사용하는 것은 문제가 있다고 생각했습니다. 즉, “제재 이력 없음”을 그대로 탐지 모델 라벨에 활용하는 것은 노이즈 라벨을 사용하는 것이기 때문에 보정이 필요합니다. 저희는 이 문제에 Weak Supervision 방법을 적용해보았습니다.
Weak supervision
Weak supervision이란 대규모의 학습 데이터 셋에 라벨을 지정하기 위해, 노이즈가 있거나 제한적이거나 일부 부정확한 소스(Weak Label)를 사용하는 기계학습의 한 분야 입니다. 즉, 라벨이 지정된 데이터의 부족, 라벨링에 대한 시간과 비용등의 문제에 대응하기 위한 라벨링 자동화 방법입니다. Weak Label의 종류에는 도메인 전문가에 의한 휴리스틱 규칙, 기존 리소스(지식 기반 정보, 사전 학습된 모델의 결과) 등이 이에 포함됩니다. 쉽게 말해, 각각의 Weak label을 바로 학습 라벨로 사용하기는 어렵지만 여러 취합한 태깅 정보들을 통해 학습 라벨로 쓸만한 결과를 만들어 주는 시스템입니다. 좀 더 자세한 정보는 이 링크를 참조하시길 바랍니다.
부정사용자 탐지 작업의 경우에도 직접적으로 라벨로 활용하기는 어렵지만 충분히 이상패턴으로 볼 수 있는 태깅 정보(Weak label)가 있었으므로 Weak supervision을 적용해볼 만하다 판단했습니다. 그 중 Snorkel이라는 관련 기법이 구현된 Python 라이브러리를 적용했습니다. 각 과정을 간단히 요약하자면 아래와 같습니다.
- 사용자가 직접 라벨을 지정하지 않는 대신, 임의의 도메인 지식들을 표현하는 Label function을 작성
- 작성한 Label functions을 토대로 라벨 생성 모델을 학습
- Unlabeled 데이터에 위의 생성 모델을 적용하여 레이블링 자동화
앞서 말씀드린 바와 같이 부정 사용자 탐지 모델링의 경우에는 ‘제재 이력 없음’이 확실한 일반 고객에 대한 라벨이 아닌 노이즈 라벨인 상황이기 때문에 Unlabeled data로 간주하여 작업을 진행했습니다. 그렇다면 snorkel에 적용된 원리와 부정사용자 탐지 모델에 어떻게 적용했는 지 다음 본문에서 계속 설명 드리겠습니다.
원리 소개
전체 과정에 대한 요약
snorkel의 각 과정은 아래 3단계로 간단히 도식화 할 수 있습니다.
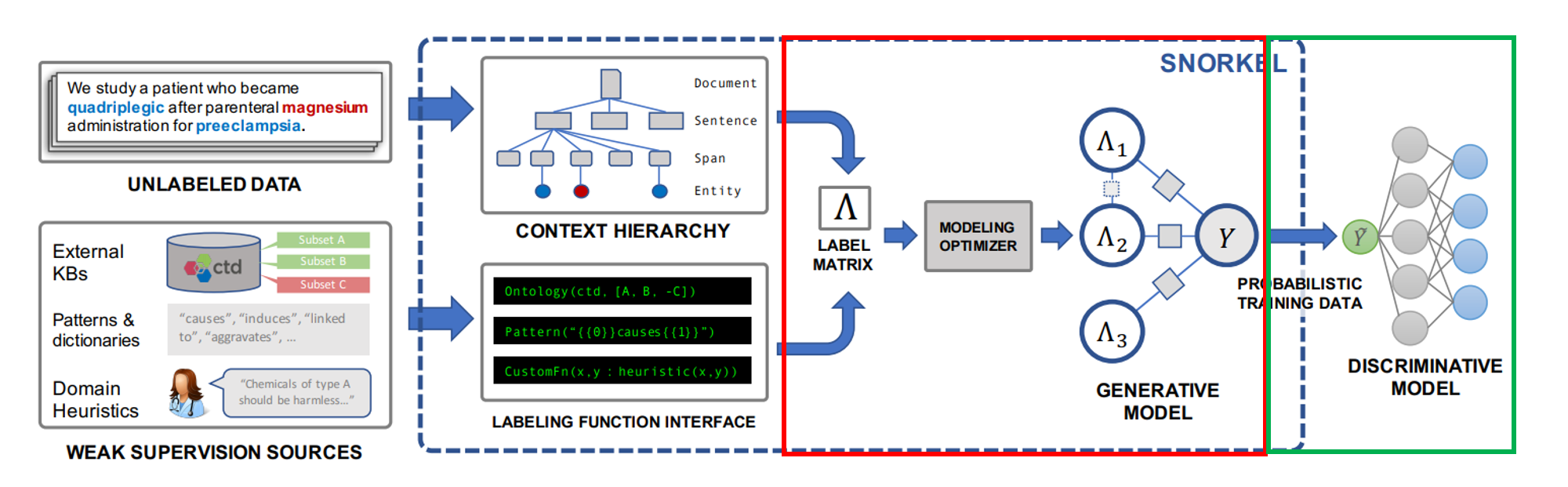 [그림1] snorkel 각 과정에 대한 도식화
[그림1] snorkel 각 과정에 대한 도식화
-
도메인 전문가에 의한 Label function 작성
-
라벨 함수를 토대로 라벨을 생성해 주는 모델 학습
-
생성 모델의 확률 라벨을 최종 분류기에 활용
각 과정에 대해 하나씩 짚어보도록 하겠습니다.
1.라벨함수 작성
먼저, 도메인 전문가가 라벨 생성 규칙을 작성합니다. 각 Label funtion이 출력하는 카테고리 값은 Positive, Negative, Unknown으로 이루어져있습니다. 예를 들어, 스팸 분류 문제라고 한다면 광고 문구에 단골로 들어가는 “check out” 같은 문구가 들어 있다면 이상 태깅(Pos) 아니면 기권으로 태깅(Unk)합니다.
from snorkel.labeling import labeling_function
import re
@labeling_function()
def check(x):
return SPAM if "check" in x.text.lower() else ABSTAIN
@labeling_function()
def check_out(x):
return SPAM if "check out" in x.text.lower() else ABSTAIN
@labeling_function()
def regex_check_out(x):
return SPAM if re.search(r"check.*out", x.text, flags=re.I) else ABSTAIN
이렇게 다양한 이상 패턴에 대한 도메인 지식을 활용하여 패턴을 함수 형태로 정의한 뒤 각 함수마다의 summary 정보를 확인할 수 있습니다.
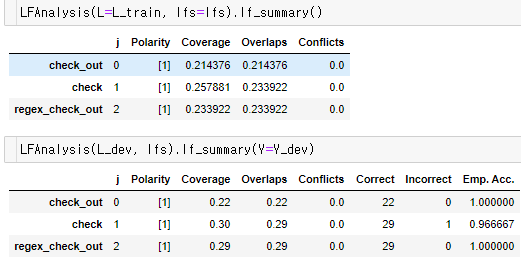 [그림2] 취합한 Label Functions의 Summary 정보
[그림2] 취합한 Label Functions의 Summary 정보
- Polarity: LF결과 유니크 labels
- Coverage: 데이터셋의 LF labels 비율
- Overlaps: 해당 LF 태깅 결과와 다른 하나 이상의 LF 태깅 결과가 같은 데이터 세트의 비율
- Conflicts: 해당 LF 태깅 결과와 다른 하나 이상의 LF 태깅 결과가 다른 데이터 세트의 비율
- Correct, Incorrect, Emp. Acc.: 실제 True 정답지가 존재했을 때의 일치, 불일치, 경험적 정확도
위의 summary 정보를 통해 작성한 라벨함수 간의 종속적인 관계가 있다는 정보와 주어진 데이터 내에서 얼마 만큼의 태깅이 가능한 지 참조 정보로 활용할 수 있습니다. 예를 들어, 어떤 Label funcion의 Coverage가 아주 낮으면서 다른 Label function의 결과와 동떨어진 결과만 출력한다면 올바른 패턴 태깅 함수라 볼 수 없으므로 로직을 재검토해봐야 합니다. 이러한 극단적인 경우가 아니라면 사용자가 직접 종속성을 제어할 필요는 없을 것입니다.
2.생성 모델 학습
두번째 과정은 snorkel의 과정 중 빨간색 박스에 해당하는 생성 모델 학습 과정입니다. 이 과정에서는 여러 도메인 지식에 근거한 Label function들을 모은 뒤 최종 취합하는 생성 모델을 통해 각 함수마다의 적합한 계수를 학습하게 됩니다. 가장 단순한 방식을 생각해보면 라벨 함수의 계수를 1로 생각하는 것(다수결 투표) 이지만 라벨 함수의 각 계수를 라벨 함수 간의 종속적인 관계, 설정한 Loss function를 고려하여 노이즈가 덜 포함된 데이터 세트로 계수를 학습하고자 하는 것이 생성 모델 학습의 목적입니다. snorkel 내에 구현된 계수를 학습하는 알고리즘은 아래 두 논문에서 개발되었습니다.
- 1.Data programming: creating large training sets, quickly’ (Ratner 2016)
- 생성모델의 기본 학습 원리는 위에서 개발
- 2.Learning the structure of generative models without labeled data’ (Bach 2017)
- 라벨 함수간의 종속성 구조를 자동으로 찾아주는 알고리즘(Structure Learning)을 추가한 것
기본 원리는 각 함수가 태깅을 달 확률, 함수 간의 태깅 결과가 고른지에 대한 확률을 모수로 하는 확률 분포를 정의 한 뒤, MLE를 통해 확률분포에 대한 두 모수를 추정합니다. 그 다음 정의한 Loss function(logistic loss)를 최소화 하는 매개변수를 학습하게 되는데, 이때 앞서 학습한 확률분포를 참고해 Loss에 대한 기대 값을 구하게 됩니다. 이렇게 되면 주어진 데이터 세트 중 노이즈가 덜 포함된 정보(정의한 확률 분포의 확률 값이 높은 값 위주)로 각 Label function의 계수를 학습하게 됩니다. 알고리즘 상세 과정은 Appendix를 참고 바랍니다.
이 과정을 통해 학습된 생성 모델을 통해 학습된 계수로 한 데이터 포인트가 들어왔을 때, 양성에 가까운지, 음성에 가까운지 확률 벡터를 만들 수 있습니다. 확률 벡터는 판별 모델의 라벨 정보로 사용하게 됩니다.
3.판별 모델 학습
마지막으로 위 도식화 그림에서 초록색 박스에 해당하는 판별 모델 학습 과정입니다. 이 과정에서는 데이터 포인트마다 얻어낸 클래스에 대한 확률 라벨 벡터 정보로 최종 모델 지도 학습을 하게 됩니다. 일반적인 지도학습 과정과 달리 loss 값을 계산할 때, One-hot 인코딩 된 라벨이 입력으로 들어가는 것이 아닌 확률 벡터가 입력으로 들어간다는 차이점이 있습니다.
상세 분석 내용
그러면 부정사용자 탐지 모델에 snorkel을 적용한 상세 분석 과정에 대해 소개해 드리겠습니다. 분석 과정은 모델링에 필요한 특성 및 데이터 추출, Label function 작성, 그리고 snorkel 적용 전의 결과와 적용 후에 대한 효과 검정으로 구성되어 있습니다.
데이터 구성 및 특성 추출
| Train 데이터 | Test 데이터 | |
|---|---|---|
| 특성 추출 기간 | 일정 기간 캐릭터들의 각종 활동 정보 특성 | Train 시점으로 이후로 부터 데이터 추출 |
| 이상/정상 태깅 정보 | 일정 기간 캐릭터들의 이상/정상 태깅 정보 | Train 시점으로 이후로 부터 데이터 추출 |
| 제재 여부 정보 | 특성, 태깅 정보 추출 날짜 기준 이후 일정 기간 내 제재 당한 이력이 있는지 여부 | Train 시점으로 이후로 부터 데이터 추출 |
위에서 추출한 피쳐와 이상/정상 태깅 정보에 사용한 변수 목록은 독립적이며 이상/정상 태깅 조건에 사용한 변수와 제재 여부와의 직접적인 상관관계는 없습니다(이상 태깅 조건이 제재룰에 직접 포함되지는 않습니다).
정상/이상 패턴 분석을 통한 라벨 함수 정의
도메인 지식과 사전 분석을 통해 정상/이상 패턴이라고 판단되는 항목 등을 라벨 태깅 함수로 등록하는 과정입니다.
참고로 정상/이상 패턴에 사용한 정보는 인게임 및 게임 외적 다양한 로그 분석을 통해 부정사용자가 할만한 행동 패턴과 행위를 사용합니다. 이렇게 패턴 태깅에 사용할 모든 Label functions들을 정의 하면, 각 데이터 포인트마다 Label function의 결과(Pos, Neg, Unk)를 취합한 Label Matrix를 얻을 수 있습니다. (분석에 사용한 상세 피쳐 항목과 로직은 대외비이므로 생략하오니 양해바랍니다. )
Label function 태깅 결과 클래스
-
부정사용자 : Pos
-
일반 고객 : Neg
-
알 수 없음 : Unk
생성/분류 모델 학습
다음은 생성/분류 모델 학습 과정입니다. 먼저 취합한 Label Matrix의 summary 정보는 아래와 같습니다.
| 패턴 태깅 유형 | 적용 함수 | Coverage | Overlaps | Conflicts |
|---|---|---|---|---|
| 이상 | LF1 | 0.2630 | 0.1560 | 0.0271 |
| 이상 | LF2 | 0.0241 | 0.0349 | 0.0003 |
| 이상 | LF3 | 0.1442 | 0.0031 | 0.0007 |
| 이상 | LF4 | 0.0580 | 0.0830 | 0.0030 |
| 이상 | LF5 | 0.0380 | 0.0008 | 0.0003 |
| 이상 | LF6 | 0.0021 | 0.0001 | 0.0001 |
| 이상 | LF7 | 0.1751 | 0.1753 | 0.0453 |
| 정상 | LF8 | 0.0290 | 0.0686 | 0.0031 |
| 정상 | LF9 | 0.3235 | 0.1573 | 0.0537 |
| 정상 | LF10 | 0.0510 | 0.0810 | 0.0163 |
이 Label Matrix를 생성모델의 인자로 넣어주어 학습을 진행하게 됩니다.
LFs = [LF1, LF2, LF3, LF4, LF5, LF6, LF7, LF8, LF9, LF10]
applier = PandasLFApplier(lfs=LFs)
LF_mat = applier.apply(df=train_df)
label_model = LabelModel(cardinality=2, verbose=True) # cardinality(클래스 갯수)
label_model.fit(L_train=LF_mat, n_epochs=50, lr=0.01, log_freq=100, seed=123)
학습된 생성모델로 부터 각 데이터 포인트의 Pos일 확률 벡터를 얻을 수 있고 이 확률 벡터를 판별 모델의 확률 라벨 벡터로 사용할 수 있습니다. 분류기는 RandomForest, DNN 등 일반적인 지도학습의 다양한 방법을 사용하면 됩니다.
라벨 보정 전/후의 효과 측정
이 과정은 라벨 보정 전의 분류기와 snorkel 생성 모델을 통해 라벨 보정 한 분류기를 학습한 뒤 효과를 검정하는 작업입니다. ‘제재 이력을 라벨로 이용하여 학습한 방식’과 ‘snorkel을 이용하여 라벨을 생성한 후 학습한 방식’을 비교했으며, 두 모델의 피쳐는 동일합니다.
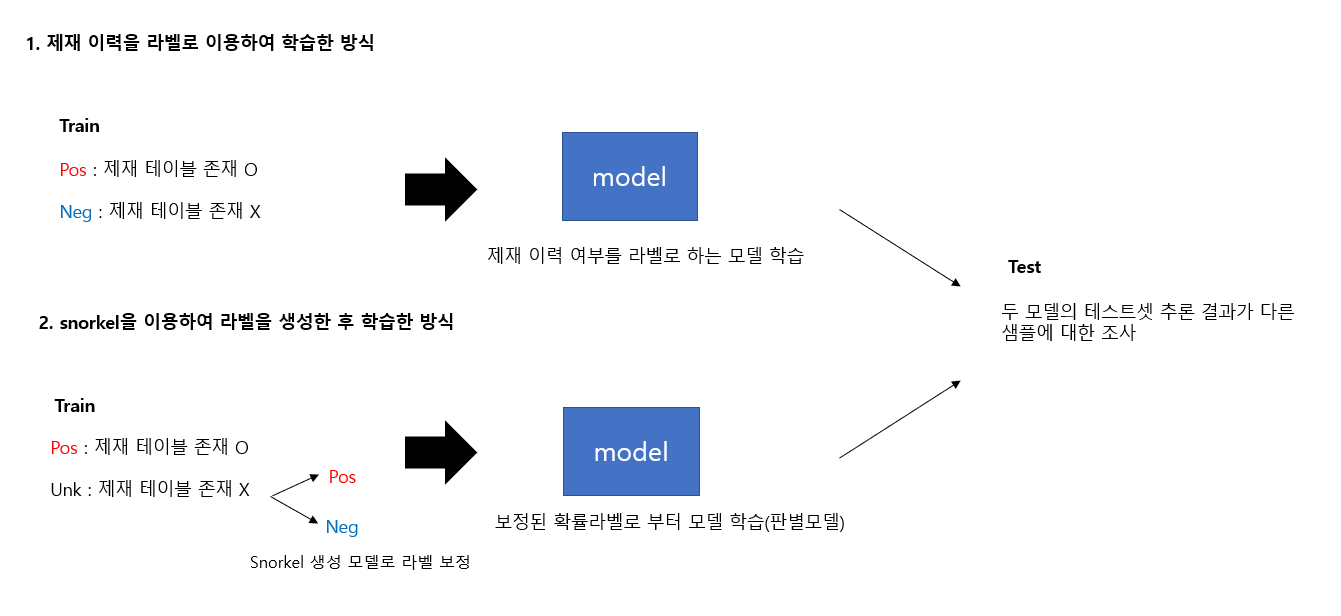 [그림3] 라벨 보정 전/후의 모델링 방식 비교
[그림3] 라벨 보정 전/후의 모델링 방식 비교
효과 검정 방법으로는 제재 이력을 라벨로 이용하여 학습한 방식과 snorkel을 통해 라벨 보정 뒤 학습한 분류 모델의 결과 비교했습니다. 이렇게 진행한 이유는 노이즈가 없는 깨끗한 정답지 마련이 어렵기 때문에 두 모델의 결과가 다른 샘플에 대하여 추가 확인하는 작업을 진행했습니다. 즉, 기존모델은 일반 사용자라 분류했지만 개선모델이 부정 사용자라 분류한 표본에 대한 검정을 시행했습니다.
(분류 결과에 대한 갯수는 직접 표기 대신 비율로 간접 표기하였습니다. )
| 제재 이력 라벨 사용 모델 Pos | 제재 이력 라벨 사용 모델 Neg | |
|---|---|---|
| snorkel 라벨 보정 후 학습한 모델 Pos | 0.312 | 0.144 |
| snorkel 라벨 보정 후 학습한 모델 Neg | 0.002 | 0.540 |
위의 분류 결과 표는 두 모델의 분류 결과를 비교한 표입니다. 두 모델의 판정결과가 엇갈린 영역 중 snorkel 라벨 보정 후 학습한 모델을 통해 추가적으로 부정사용자라 분류된 샘플(빨간색 폰트 영역 0.144)이 많습니다. 제재 이력 라벨 사용 모델이 Pos라 분류했으나 snorkel 라벨 보정 후 학습한 모델이 Neg라 분류한 결과는 0.002로 상대적으로 적습니다. 또한 부정사용자 탐지 모델링의 경우 recall 보다는 precision(부정사용자라 판단 내린 결과)에 대한 조사가 더 중요한데, 부정사용자를 일반 고객으로 판정하는 경우보다 일반 고객을 부정사용자라 판정내리는 오탐이 더 위험하기 때문입니다. 따라서 빨간색 폰트영역이 실제 오탐인지 아닌지를 확인하는 상세 분석을 진행 했습니다.
추가 검출한 샘플에 대한 Pos/Neg 판단
snorkel 라벨 보정 후 학습한 모델이 추가 검출한 샘플이 부정사용자인지 일반 고객인지 판단하기 위해, 유형을 나눠 생성모델의 태깅 결과와 데이터를 확인하는 과정을 거쳤습니다. 먼저, 생성모델의 태깅이 Pos인데 제재 이력이 없는 경우입니다. 이 샘플들에 대한 조사를 진행해보니 적어도 1개 이상 패턴 태깅 함수에 속했으며 실제 데이터를 확인해보니 일반 고객이 하기 어려운 이상 패턴이 존재하는 것을 확인했습니다. 따라서 제재 이력이 없더라도 탐지 모델의 결과가 Pos이면서 생성모델도 Pos로 태깅된 경우는 부정사용자로 간주했습니다. 다음은 생성모델의 태깅은 Neg인데 제재 이력은 없는 경우가 있습니다. 이 샘플들은 조사 결과 이상 패턴 함수에서의 태깅 결과에 속하지 않으면서 일반 고객들에서도 나오는 정상 패턴이 존재했습니다. 따라서 이 유형의 경우는 현재 주어진 정보 상 오탐으로 판단했습니다. 이러한 판단 논리로 각 유형에 대해 확인한 결과를 아래에서 살펴보겠습니다.
아래 표는 위 표의 빨간색 폰트 샘플 0.144에 대한 제재 이력과 생성모델(취합한 Label Matrix를 통해 Pos, Neg, Unk로 분류해주는 모델)의 확인 결과 표입니다.
| 유형 1. 생성 모델 태깅 결과 Pos | 유형 2. 생성 모델 태깅 결과 Neg | 유형 3. 생성 모델 태깅 결과 Unk |
|---|---|---|
| 0.76 | 0.08 | 0.15 |
-
유형 1. 생성 모델 태깅 결과 Pos
-
추가 검출된 0.144에 해당하는 샘플 중 유형1은(76%) 주어진 피쳐 상 부정 사용자와 비슷한 패턴을 보이며, 부정 사용자라 판단할 만한 이상 태깅도 존재
-
이 유형 샘플들에 대해 이상 태깅 정보를 집계한 결과, 적어도 1개 이상의 이상 태깅에 해당되었음
-
각 이상 태깅에 대한 실제 데이터를 확인해보면 일반 고객이 할 수 없는 매크로적인 행동을 관찰
-
-
유형 2. 생성 모델 태깅 결과 Neg
-
추가 검출된 0.144에 해당하는 샘플 중 유형2는(8%) 주어진 피쳐는 부정 사용자와 비슷하나, 일반 고객에서도 발견되는 특성이 나타남
-
이 유형 중 정상 태깅 조건에 하나라도 해당되는 유저는 99%이고 이상 태깅 조건에 하나라도 걸린 샘플 수는 17%
-
즉, 대부분 이상 태깅은 없고 정상 태깅 중 한 가지 조건에 해당했기 때문에 snorkel 라벨링 결과 Neg으로 태깅된 것
-
실제 데이터를 확인해보면 일반 고객의 특징을 갖는 샘플도 섞여있음
-
-
유형 3. 생성 모델 태깅 결과 Unk
-
추가 검출된 0.144에 해당하는 샘플 중 유형3은(15%) 주어진 피쳐는 부정 사용자와 비슷한 패턴을 보이나, 이상 태깅 정보로는 부정/일반 유저를 판단하기 어려운 샘플
-
이 유형의 샘플 중 정상/이상 태깅이 단 한개라도 존재하는 샘플이 1% 뿐임
-
Label functions의 Coverage의 한계가 드러난 영역
-
위의 결과는 생성 모델의 태깅 정보가 신뢰할 수 있다고 가정했을 때, 아래의 결론으로 요약할 수 있습니다.
-
유형1 (생성 모델 태깅 결과 Pos 인 경우) – 제재 이력은 없지만 테스트 데이터의 생성 모델의 태깅 정보도 Pos 이니 부정사용자로 판단됨
-
유형2 (생성 모델 태깅 결과 Neg 인 경우) – 생성 모델의 태깅 정보가 Neg 인데 Pos 라고 잘못 분류한 것인데 실제 데이터를 보니 일반 고객의 특징이 많이 보이기 때문에 잘못 분류한 것으로 판단됨
-
유형3 (생성 모델 태깅 결과 Unk 인 경우) – 생성 모델의 태깅은 Unk 인데 Pos 라고 분류한 경우인데 실제 데이터를 보니 판단하기 어려움
아래의 Confusion Matrix는 생성 모델의 태깅 정보를 신뢰하였을 때, ‘제재 이력을 라벨로 이용하여 학습한 모델’과 ‘snorkel을 이용하여 라벨을 생성한 후 학습한 모델’을 비교한 결과입니다. (전체 테스트 데이터 개수를 백분율로 표기)
제재 이력을 라벨로 이용하여 학습한 모델
| 예측 Neg | 예측 Pos | |
|---|---|---|
| 정답지 Neg | 62.5 | 5.0 |
| 정답지 Pos | 5.9 | 26.6 |
- f-1 score : 0.830
- precision : 0.819
-
recall : 0.842
snorkel을 이용하여 라벨을 생성한 후 학습한 모델
| 예측 Neg | 예측 Pos | |
|---|---|---|
| 정답지 Neg | 51.5 | 5.1 |
| 정답지 Pos | 2.7 | 40.7 |
- f-1 score : 0.914
- precision : 0.892
- recall : 0.937
유형1번의 경우 부정사용자가 맞다고 판단되는 유형이고, 2번 유형의 경우 오탐을 의심, 3번의 경우 현재 주어진 정보로 판단이 어려운 영역입니다. 이 논리대로 성능평가를 진행한다면 제재 이력만을 라벨로 이용한 결과 보다 f1 스코어 기준 0.084의 향상을 이룰 수 있습니다. 유형 2번, 3번의 경우는 현재 고려한 Label funtions의 Coverage 문제, 피쳐의 한계가 있는 영역입니다. 따라서 이 두 유형의 샘플에 대한 상세 분석을 통해 앞으로의 모델링 고도화 작업이 필요할 것입니다.
마치며
지금까지 부정사용자 탐지 모델 작업에서 snorkel 을 적용한 결과를 소개 해드렸습니다. Weak supervision의 사용 가능성을 보았지만 앞으로 보완 및 고민해야 할 부분도 많습니다. 예를 들어, Label funtion에 대한 지속적인 관리 방안(Label function이 충분한지, 불필요한 Label function이 있다면 제거), 좀 더 깨끗한 정답지로 정량적 성능 평가 방식 고안을 생각해봐야 합니다. 체계적인 라벨 데이터 구축을 위한 지속적인 노력을 통해, 올바른 탐지 모델에 대한 학습과 제재 프로세스 자동화에 기여하면 좋겠습니다.
Appendix
-
backgorund
매개변수 추정을 위한 ERM 알고리즘
-
우리가 찾고자 하는 모델 \(f(x)\)의 Risk는 loss function(L)의 기댓값으로 정의
- \[R(f) = E[L(f(x), y)]\]
-
통계적 학습(Statistical Learning)의 목표는 이 loss의 기댓값을 최소화하는 \(f\)를 찾는 것
- \[f^* = argmin_{f \in F}R(f)\]
-
그러나 우리는 실제 \(P(x,y)\)의 확률분포를 알 수 없기 때문에 Risk를 직접 구할 수 없고 주어진 데이터셋 내에서 근사화 해서 찾아야한다. 그 값이 곧 Empirical Risk
- \[R_{emp}(f) = {1 \over N}{\sum_{i=1}^{N}L(f(x_i), y)}\]
-
예를 들어, Logistic 함수를 loss 함수로 활용한다면 아래와 같음
- \[l(w) = E_{(x,y) \sim \pi}[log(1+ exp(-w^t f(x) y))]\]
- 이를 최소화 하는 f(x)(혹은 매개변수)를 찾는 것이 학습의 목표가 되고 Empirical risk minimization이라 함 → SGD를 통해 찾음
-
-
알고리즘(Data Programming의 기본 학습 원리)
-
아래의 조건 하에서 추정치 (2), (3)을 찾을 수 있음
-
Λ : 라벨 함수에 의한 라벨 output
-
m : 라벨 함수 갯수
-
Y : predicted class
-
\[\forall \in \{ -1, 0, 1\}^m, Y \in \{ -1, 1\}^m, P_{(x,y) \sim \pi}(\lambda(x) = \Lambda, y = Y) = \mu_{\alpha^*, \beta^*}(\Lambda, Y)\]
-
-
1.Class 분류 확률을 1/2이라 하고, 아래와 같은 확률을 최대화 하는 모델 식을 정의(1 : indicator function)
-
이 모델에서 각 라벨링 함수 \(\lambda_i\)는 객체에 라벨을 붙일 확률 \(\beta_i\)와 객체를 올바르게 라벨링 할 확률 \(\alpha\)을 가짐
-
\[\mu_{\alpha, \beta}(\Lambda, Y) = {1 \over 2} {\prod_{i=1}^m (\beta_i \alpha_i 1_{\{\Lambda_i = Y\}} + \beta_i (1- \alpha_i) 1_{\{\Lambda_i = -Y\}} + (1- \beta_i )\alpha_i 1_{\{\Lambda_i = 0\}} )} \qquad (1)\]
- 한 데이터 포인트를 입력했을 때, 이 확률 값이 1에 가까울 수록 라벨 함수들의 태깅을 붙일 확률이 높으며, 출력한 결과들도 고르다는 의미로 해석됨
- 반대로 0에 가까울 수록 라벨 함수들의 태깅 붙일 확률이 낮으며, 출력한 결과가 상이하거나 Unknown으로 출력하는 비율이 높다고 해석됨
-
-
-
2.(1)의 식을 최대화 하는 α, β를 MLE를 통해 찾음
-
\[(\hat \alpha, \hat \beta)= argmax_{\alpha, \beta} \sum_{x \in S} logP_{(\Lambda, Y) \sim \mu_{\alpha, \beta} } (\Lambda = \lambda(x)) = argmax_{\alpha, \beta} \sum_{x \in S} log(\sum_{y' \in {\{-1, 1\}} } \mu_{\alpha,\beta}(\lambda(x), y')) \qquad (2)\]
-
\[(\hat \alpha, \hat \beta)= argmax_{\alpha, \beta} \sum_{x \in S} logP_{(\Lambda, Y) \sim \mu_{\alpha, \beta} } (\Lambda = \lambda(x)) = argmax_{\alpha, \beta} \sum_{x \in S} log(\sum_{y' \in {\{-1, 1\}} } \mu_{\alpha,\beta}(\lambda(x), y')) \qquad (2)\]
-
3.위에서 도출한 α, β를 토대로 다시 1번 의 logistic loss function을 최소화(empirical risk minimization)하는 weight를 찾는다.
-
학습 방법은 SGD를 통해 도출 (우항의 \(w\)의 norm은 과적합 방지를 위해 l2 정규화 항 추가한 형태, \(S\)는 특정 training data set, \(f(x)\)는 단순한 선형결합 함수)
-
\[\hat w = argmin_w L_{\hat \alpha, \hat \beta}(w; S) = argmin_w {1 \over |S|} \sum_{x \in S}E_{(\Lambda, Y) \sim \mu_{\alpha, \beta}}[log(1+e^{-w^T f(x)Y})| \Lambda = \lambda(x)] + \rho ||w||^2 \qquad (3)\]
-
-
즉, 노이즈가 덜 포함된 정보(위의 확률분포가 1에 가까운 샘플 위주)로 라벨 함수의 매개변수를 학습하겠다는 의미로 해석
-
종속성을 추가한 확장 알고리즘
-
라벨 함수간의 종속 관계를 고려한 factor를 μ 식에 반영한 형태로 변경
-
Λ : Label function matrix, ϕ : 라벨 함수간 종속적인 관계, Unknown을 덜 출력 하는 비율 등이 고려된 factor
-
종속적인 관계의 요소는 아래와 같음
- \[\phi_{i,j}^{Lab} = 1(\lambda_{i,j} \neq \emptyset ) \qquad \qquad \qquad \quad \\ \phi_{i,j}^{Acc} = 1(\lambda_{i,j} = y_i ) \qquad \qquad \qquad \quad \\ \phi_{i,j}^{Corr} = 1(\lambda_{i,j} = \lambda_{i,k}) \qquad (j,k) \in C \\\]
-
1.라벨함수의 출력결과가 Unk이 아닌 것의 개수
-
2.라벨함수의 출력결과와 예측된 클래스가 일치하는 수
-
3.i번째 데이터 포인트의 라벨 함수 조합 (j, k)를 선택했을 때 결과가 일치하는 수
-
위의 각 Φ를 Concat한 벡터(위의 종속적인 관계가 고려된 Factor)를 m개의 데이터 포인트에 가중합 한 형태, Z는 정규화 상수
- \[P_w(\Lambda, Y) = Z_w^{-1}exp(\sum_{i=1}^m w^T \phi_i(\Lambda, y_i))\]
-
위의 식의 Negative Log Loss 꼴로 바꾸고 최소화 하는 weight를 찾는다.
- \[\hat w = argmin_w -log\sum_Yp_w(\Lambda, Y)\]
-
학습된 weight를 각 라벨함수의 계수로 사용
-
위 확률을 추정하는 상세 기법
- Y가 잠재변수이므로 위의 직접 확률을 추정하지 않고, Λ에 대한 marginal pseudolikelihood 을 구하는 방식으로 근사값을 찾는다. → 자세한 내용은 Learning the structure of generative models without labeled data’ (Bach 2017)를 참조
-