
PC의 시스템 로그를 활용하여 위협 행위 탐지하기
by DANBI
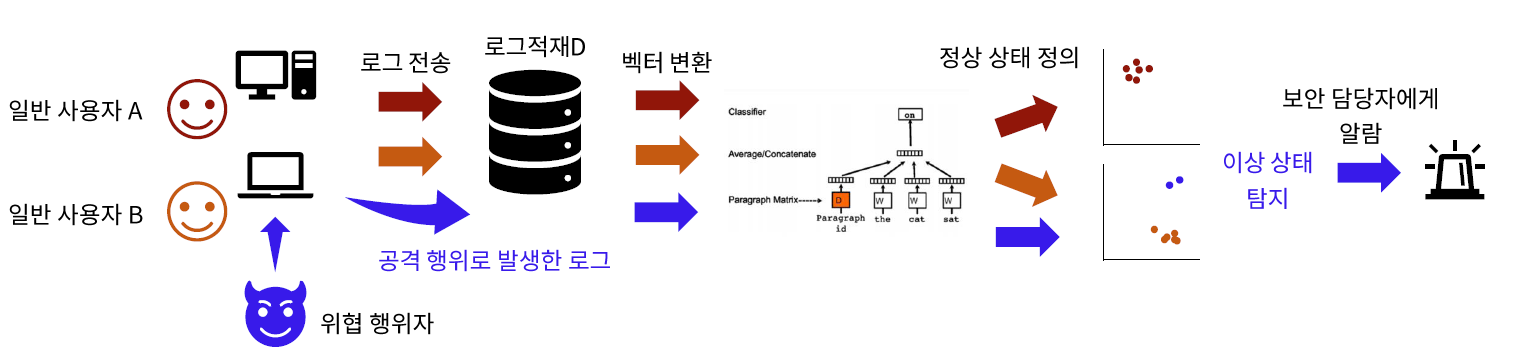
시작하며
하루에도 수통 씩 들어오는 스팸문자나 주기적인 개인 정보 유출 사고 뉴스를 접하다 보면 평소 보안에 관심이 없던 사람이라도 자신이 얼마나 위험에 노출되어 있는지 걱정되기 마련이다. 이런 이들을 위해 다양한 보안 프로그램과 서비스들이 등장하였지만 그에 맞춰 공격자들 또한 더욱 고도화된 방법들을 시도하고 있다. 대표적으로 기술적인 틈을 노리는 것이 아니라, 사용자의 인지적인 헛점을 공략하는 사회공학적 해킹 기법의 하나인 스피어피싱 (Spear phishing)이 있다. 스피어피싱은 불특정다수가 아니라 특정 개인/ 조직을 타겟으로 설정하고, 그들이 의문 없이 열람하도록 위장한 메일을 통해 악성코드를 감염시키는 공격 방식이다. 조직원이 공격 의도를 파악하지 못하고 메일 내 링크나 첨부파일을 열람할 때 악성코드가 실행되므로 방화벽과 같은 기존 보안 방식으로 사전에 이를 감지하여 막는 것은 쉽지 않다.
일단 치명적인 공격이 발생했다면 이에 대한 대응은 빠를수록 좋다. 그러나 공격자들은 최대한 많은 정보를 빼내기 위하여 공격 시도를 은폐하기 위한 조치들을 취해 놓는다. 앞서 예로 들은 스피어피싱의 경우 사용자가 문제되는 첨부파일 실행 시 악성 코드 감염 사실을 눈치채지 못하도록 정상 파일을 보여주는 식이다. 이렇게 침투한 악성 코드는 피해자의 PC를 경유해 조직의 DB나 서버에까지 접근하여 중요한 정보들을 탈취할 수 있게 된다.
보안 분야에서는 고도화되는 위협에 대응하기 위하여 위협 탐지 지점을 네트워크 경계 영역만이 아니라 실제 위협이 실현되는 엔드포인트(Endpoint)로 확장하고 있다. 엔드포인트란 PC, 노트북, 핸드폰 등과 같이 네트워크와 최종적으로 연결되는 IT 디바이스를 의미한다. 엔드포인트에서의 보안 분야 중 하나로 엔드포인트 탐색 및 대응 (Endpoint Detection and response, EDR)이 있는데, 원천적인 예방보다는 수상한 행동이 발생했을 경우에 대한 빠른 탐지와 초기 조치를 중요시한다. 이를 위해 엔드포인트에 설치된 에이전트가 시스템에서 발생하는 각종 활동을 끊임없이 모니터링하고 중앙 서버에 해당 정보를 전송하며 의심스러운 행동을 발견하면 자동으로 이를 수정하거나 보안 전문가에게 즉각 확인하도록 알림으로써 가능한 빠르게 위협 행위를 감지하고 대응할 수 있도록 한다. 이는 앞서 예시로 들었던 스피어피싱과 같이 사용자의 허점을 노려 시스템에 잠입한 뒤 장기간에 걸쳐 필요한 정보를 탈취한 다음 흔적을 지우고 사라지는 공격에 대해 특히 유효할 수 있다.
여기서 중요한 것은 의심스러운 행동을 최대한 빠르게 감지하는 것이다. 그렇다면 의심스러운 행동이란 무엇일까? 그 기준은 어떻게 정할 수 있을까? 이번 글에서는 이 질문에 대한 답을 찾기 위해 PC로부터 수집한 시스템 이벤트의 로그를 활용해본 방법과 그 결과를 소개해보고자 한다.
정상 상태 정의와 이상 상태 탐지
인사팀에 근무하는 A씨는 평소 9시에 출근하여 6시에 퇴근한다. 가끔 야근을 할 때도 있지만 12시를 넘기는 일은 흔치 않다. 그는 주로 자신의 PC로 엑셀과 워드, 파워포인트를 이용해서 작업을 하며 이메일과 사내 메신저를 사용해 협업을 한다.
만약 A씨의 PC로부터 새벽 2시에 쉘 스크립트를 통하여 전사 직원의 계좌 정보에 접근한 로그가 발생하였다면 이는 그의 평소 행동 패턴과는 매우 상이하다고 판단할 수 있을 것이다. A씨의 행동은 그 자신의 평소 패턴으로부터도 떨어져 있을 뿐 아니라 그가 속해 있는 인사팀의 일반적인 행동 범위로부터도 벗어났다는 점에서 상당히 의심스럽다.

위의 예시와 같이 PC 사용자들은 그들의 작업 방식 및 생활 패턴에 따라 각자의 정상 상태를 갖고 있을 것이다. 설령 개개인의 업무나 생활 방식에 변화가 발생할지라도 그가 수행하는 업무 특성 및 소속된 조직 단위로보면 일정한 범위로 정상 행동을 표현할 수 있을 것이다. 만약 악성 코드에 감염된 사용자의 PC에서 위협 행위가 시도될 경우 그로 인해 발생하는 로그는 정상 행동 범위에서 벗어나게 될 가능성이 높을 것이다. 이번 글에서 설명하려는 위협 행위 탐지 방법론은 이상의 가설에 기초하여 아래와 같은 동작 방식을 상정하고 있다.
먼저 각 사용자의 PC로부터 시스템 이벤트의 로그들을 수집한다. 로그가 충분히 자세하고 양이 풍부하다면 각 사용자의 PC 사용 패턴을 수집된 로그들을 사용하여 표현할 수 있을 것이다. 이렇게 각각의 정상적인 PC 사용 상태를 정의한 다음, 평소의 이용 패턴과 크게 상이한 이벤트 로그가 발생하였을 때 이를 위협 가능성이 있는 행위 후보로써 감지하고 실제 위협 행위여부를 판단할 수 있도록 보안 전문가에게 알람을 제공한다.
그렇다면 마이크로초 단위로 발생하는 시스템 이벤트의 로그들을 사용해서 어떻게 각 사용자의 정상 상태를 정의할 수 있을까? 그리고 이렇게 표현된 정상 상태가 사용자의 행동 특성을 충실하게 담고 있다는 것을 어떻게 확인할 수 있을까? 여기서 문서 임베딩 방식의 대표주자 중 하나인 Doc2Vec이 등장한다.
Doc2Vec을 사용한 사용자 행동패턴 표현과 이상탐지
Doc2Vec에 대해 이야기하기에 앞서 먼저 Word2Vec에 대해 간단하게 알아보자. Word2Vec은 단어를 벡터와 같은 연산 가능한 형태의 수학적 객체로 표현하기 위한 단어 표현 (Word Representation) 방법론 중 하나이다. Word2Vec을 사용하여 ‘사과’, ‘자동차’와 같은 단어들을 [2.351, -0.217, 1.242], [-4.121, 0.887, 1.298]과 같은 벡터로 변환할 수 있다는 것이다. Word2Vec은 이렇게 변환된 유사한 의미의 단어들이 벡터 공간 상에서도 비슷한 좌표값을 갖는다는 특징을 갖고 있다.
Doc2Vec은 단어(Word)가 아니라 문서(Document)를 벡터로 변환하는 방법론이다. Doc2Vec은 단어들로 구성된 문서와 문서의 ID에 해당하는 paragraph vector를 함께 학습하여 문서를 위치 좌표 공간상의 벡터로 변환한다. Word2Vec에서 의미가 유사한 단어들이 벡터 공간 상에서 비슷한 좌표계에 위치하는 것과 같이 Doc2Vec으로 학습된 문서들도 해당 문서를 구성하는 단어의 분포가 유사하면 비슷한 벡터를 지니게 되며, 이에 따라 주제 및 내용이 유사한 문서들이 비슷한 벡터로 변환되어 유사한 좌표 공간상에 위치한다.
이번 분석에서 정상 상태 정의를 위한 방법으로 Doc2Vec을 선택한 것은 이 특징 때문이다. 주제 및 내용이 유사한 문서들이 비슷한 벡터로 변환된다면, 각 사용자의 PC로부터 발생한 시스템 이벤트 로그의 집합(시퀀스)를 Doc2Vec으로 변환할 경우에도 사용자에 따라 벡터들이 비슷하게 생성될 것이다.
앞선 A씨의 PC에서 발생한 시스템 이벤트의 로그들을 모아 하루치 씩 Doc2Vec에 적용해서 벡터들을 생성했다고 해 보자. A씨의 행동 패턴에 큰 변화가 없었다면 7월 1일의 로그 시퀀스를 구성하는 이벤트 로그의 분포와 7월 2일의 분포는 유사할 것이므로, 7월 1일의 벡터와 7월 2일의 벡터는 좌표 공간 상에서 비슷한 곳에 위치하게 될 것이다. 그리고 로그 데이터가 충분히 많고 정밀하다면 A씨의 옆 팀 동료인 B씨의 로그 시퀀스 벡터는 A씨와 구분 가능할 정도로 떨어진 공간 상에 배치될 것이다. 만약 일정 기간에 걸쳐 각 사용자의 시간별 또는 일별 로그 시퀀스 벡터들을 생성해서 그들이 일정 크기의 클러스터를 구성한다면, 이후 해당 클러스터로부터 크게 떨어진 행동 로그 시퀀스가 발생했을 때 이를 위협 가능성이 존재하는 행위로써 탐지할 수 있을 것이다.
여기까지 해서 방법론에 대한 개괄 설명은 끝났다. 다음부터는 실제 데이터를 사용해서 어떤 식으로 분석을 진행하였고 그 결과가 어떻게 나왔는지 보여 드리고자 한다.
적용 과정
제안된 방법론에 적용하기 위한 데이터는 단비 블로그를 운영하고 있는 I&I실 실원들의 PC로부터 수집하였다. 수집 기간 중 인력 변동 및 장비 교체가 발생하여 최종적으로 14명의 유저가 사용한 15대의 PC로부터 총 100일간 (2019년 7월 3일 ~ 2019년 10월 10일) 발생한 로그를 확보하였다.
보안 서비스 업체인 Carbon Black에서 제공하는 엔드포인트 보안 솔루션의 내장 센서로부터 수집되는 로그는 json 또는 LEEF 구조의 key-value쌍의 형태로 기록되는데, 발생한 시스템 이벤트의 성격(종류)에 따라 key의 구성 및 value의 형식에 차이가 있다. 이번 분석에서는 시스템 이벤트가 발생한 시각, 발생한 PC의 ID, 발생한 이벤트의 종류 및 발생 경로에 대한 정보를 사용하였다.
시스템 로그는 PC가 동작하는 동안 지속적으로 발생하므로 하나의 문서로써 취급할 로그 시퀀스를 생성하기 위해서는 연속되는 로그(단어)들을 일정 기간 단위로 쪼갤 필요가 있다. 일반적으로 PC를 사용해서 업무를 수행하는 개인의 행동 패턴은 출근과 오전 근무, 점심 식사, 오후 근무 후 퇴근과 같은 반복성을 띄게 되며, 근무일과 휴일의 차이 및 요일별 차이도 고려할 필요가 있다. 이를 위하여 연속 발생하는 시스템 로그를 사용자별로 일-시간 단위로 분절하는 방법과 일 단위로 분할하는 방법을 각각 수행하여 결과를 확인하였다. 총 100일의 수집 기간 중 전반기 (2019년 7월 3일 ~ 7월 12일, 총 10일) 데이터는 시간 단위로 로그 시퀀스를 생성하였고, 후반기 (2019년 8월 22일 ~ 10월 10일, 총 50일) 데이터는 일 단위 로그 시퀀스를 생성하였다.
이렇게 전처리를 마친 로그 시퀀스를 문서로, 해당 로그 시퀀스가 발생한 시간대 혹은 날짜를 문서 ID로 설정하여 Doc2Vec에 적용하여 30차원의 벡터로 변환하였다. 그리고 변환된 각 벡터가 발생한 PC의 ID를 라벨로 붙여 앞서 가정했던 것처럼 벡터들이 사용자의 행동 정보를 잘 포함하고 있는지 확인하기 위한 검증을 진행했다.

먼저 전반기와 후반기 각각에 대해 로그 시퀀스가 발생한 시점에 따라 학습기간과 평가기간을 나눴다. 그리고 학습기간 동안 발생한 로그 시퀀스의 벡터들로 이들이 발생한 PC(의 ID)를 분류하도록 학습시킨 다음, 평가기간 발생한 로그 시퀀스의 벡터가 주어졌을 때 각 벡터가 발생한 PC를 제대로 예측할 수 있는지 알아보았다. 더불어 생성된 로그 시퀀스 벡터들을 시각화하여 처음 예상했던 것처럼 이들이 일정 범위의 클러스터를 구성하고 있는지 확인해 보았다.
적용 결과
차원 축소 및 시각화
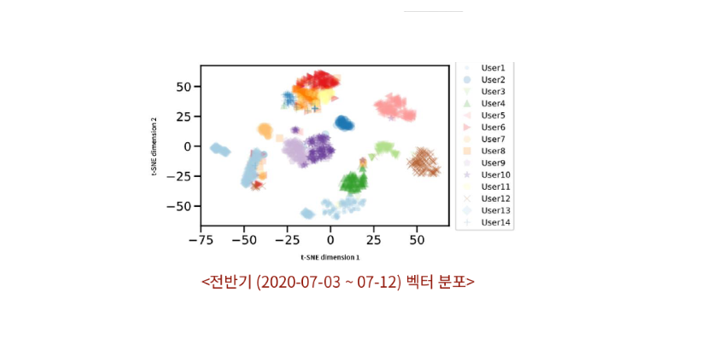
30차원의 벡터를 2차원 평면 상에 도시하기 위해 t-SNE를 사용하여 벡터의 차원을 축소하였다. 만약 사용자의 행동 특성이 정상적으로 반영되었다면 동일한 PC로부터 발생한 로그 시퀀스의 벡터들은 2차원 공간상에서 밀집된 형태로 나타날 것이다. 또한, 사용자별 행동 특성이 상이하다면 발생한 PC에 따라 벡터들이 다른 위치에 배치되어야 할 것이다.
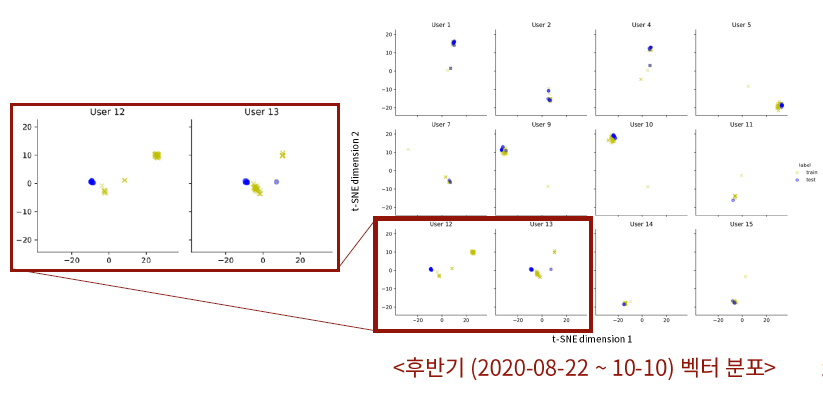
먼저 전반기 데이터를 사용해 시간대별 로그 시퀀스를 생성한 결과는 다음과 같다. 점의 색깔은 각 로그 시퀀스가 발생한 PC의 사용자를 의미하는데, 각 사용자의 벡터들이 클러스터 형태로 분포되는 것을 확인할 수 있다.
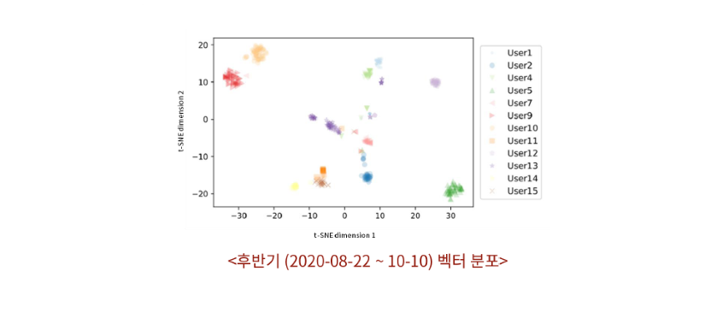
일별 로그 시퀀스를 생성한 후반기의 결과도 비슷하다. 다만 시간대별 결과에 비해서 생성된 포인트의 개수가 적어 클러스터 간 거리가 더 떨어지는 형태로 나타남을 알 수 있다.
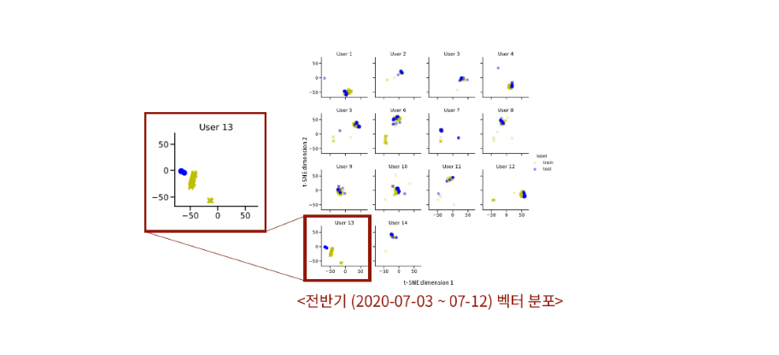
기간 변동에 따른 차이는 있었을까? 시간이 경과하여도 로그 수집에 참가한 대부분의 사용자들의 벡터들은 비슷한 공간 상에 mapping되었다. 다만, 전반기에서는 User 13, 후반기에서는 User 12와 User 13의 결과에서 학습 기간 벡터와 평가 기간 벡터의 영역이 비슷하게 위치하고는 있으나 겹치는 부분은 거의 없는 것으로 나타났다.
분류 모델을 통한 성능 측정 결과
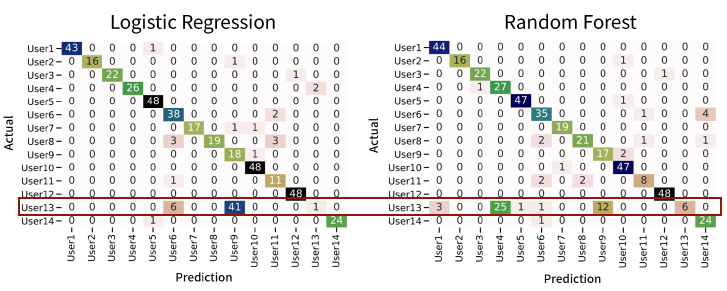
마지막으로 로그 시퀀스로 생성한 벡터들이 개별 사용자의 행동을 잘 표현하고 있는지 두 종류의 분류 모델을 통해 확인해 보았다. 앞서 설명한 것처럼 각 분류 모델의 목표는 특정 로그 시퀀스 벡터가 어느 PC로부터 생성되었는지를 분류하는 것이다. 분류 알고리즘은 Logistic Regression과 Random Forest를 사용하였다.
먼저 전반기의 시간별 로그 시퀀스 벡터를 설명변수로 사용한 두 분류 모델의 성능은 Macro F1-Measure 기준으로 0.83이었다. 전체적으로 Logistic Regression과 Random Forest 모두 로그 시퀀스 벡터가 생성된 PC를 준수하게 예측하였다. 다만 아래에서 확인할 수 있듯이 User 13의 PC에서 생성된 로그 시퀀스는 두 분류모델에서 대부분 오분류되는 결과가 발생했다.
왜 한 사람의 PC에서만 이런 현상이 나타난 것일까? 이 질문에 대한 답을 구하기 위해 User 13과의 인터뷰를 수행해 보았다. 그에 따르면 User 13은 두 대의 PC를 사용하여 작업을 하는데, 학습 기간에는 보안 솔루션이 탑재된 PC를 주로 사용하였던 반면 평가 기간에는 솔루션이 설치되지 않은 다른 PC를 중점적으로 사용했다는 것을 알 수 있었다. 즉, 학습기간의 행동 패턴과 평가기간의 행동 패턴이 변화함에 따라 이러한 결과가 나타났을 것으로 예상해 볼 수 있었다.
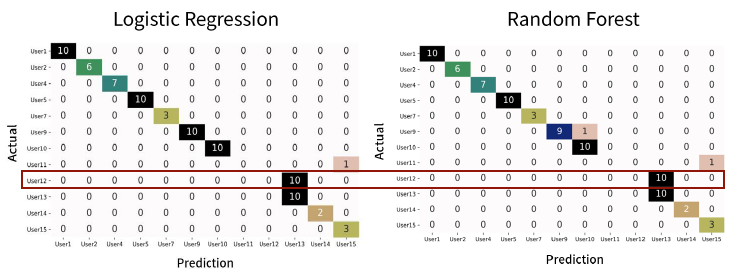
후반기의 일별 로그 시퀀스 벡터로 학습시킨 분류 모델들의 성능도 전반기와 비슷하였다. Logistic Regression의 Macro F1-Measure는 0.82, Random Forest는 0.81이었으며, 여기에서는 User 12의 로그만 대부분 오분류되는 현상이 발생하였다. User 12에게도 동일한 인터뷰를 진행해 본 결과, 9월 말부터 보안 솔루션이 설치되지 않은 PC를 주로 사용하는 업무를 수행했다는 것을 알 수 있었다.
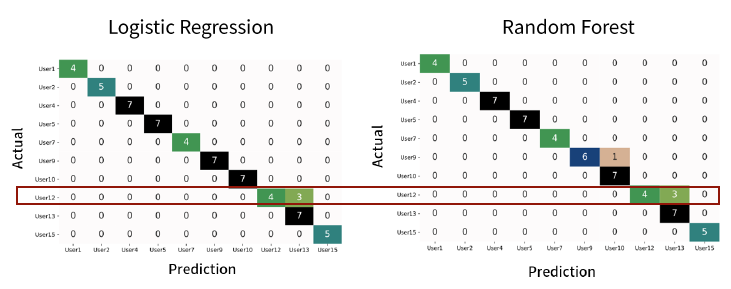
두 번의 분류 모델링과 관계자 인터뷰를 통해 사용자의 업무 방식 변화가 벡터화된 로그 시퀀스에 반영된 것이 오분류의 원인일 것으로 추정할 수 있었다. 이 추정에 대한 검증을 위해 후반기의 오분류 당사자였던 User 12의 인터뷰 내용을 활용해보기로 했다. User 12는 업무 방식의 변화가 9월 말에 발생했다고 말했다. 그렇다면 후반기 모델의 학습기간을 9월 중순까지 설정하고 평가기간을 9월 하순으로 두었을 경우, User12의 로그 시퀀스 벡터에 대한 분류 성능의 정확도는 어떻게 변화할 것인가?
그 결과는 다음과 같다. 해당 기간에 대한 전체적인 분류 모델 두개의 성능이 Macro F1-Measure 기준 0.93~0.95로 상승하였고, 관심의 대상이었던 User12의 7일간의 로그 시퀀스 벡터 중 4개를 정확히 분류하였다. 특히 전체 평가기간 중 9월 24일부터 27일까지의 나흘 간의 데이터를 정확히 분류하고 이후 사흘(9월 28일~30일)을 오분류 하였는데, 이는 9월 말에 업무 방식이 변화했다는 사용자의 응답 내용과 일치하는 결과라고 할 수 있다.
마치며
이 글에서는 앞서 사용자의 정상 행동 상태를 잘 정의할 수 있다면 향후 보안 위협에 의해 정상 범위로부터 크게 벗어난 행위가 발생했을 시 이를 위험 가능성이 있는 행동으로써 탐지하여 신속한 대응이 가능하리라 가정하였다. Doc2Vec을 사용해 시간별 또는 일별로 변환한 로그 시퀀스의 벡터에는 사용자의 행동 특성이 반영되어 있었고, PC 사용 행동 패턴의 변화 또한 변환되는 벡터에 반영되는 것을 알 수 있었다. 따라서 이를 잘 활용하면 목표로 했던 신속한 위협 행위 탐지 및 알람 시스템을 구축해 볼 수 있으리라 생각한다.
다만 이번 분석에서는 데이터의 수집 대상이 동일한 실의 한정된 인원에 국한되어 있었다. 만약 이번 분석에서 설계한 것처럼 사용자 개개인에 대한 정상상태를 정의하는 방식을 취하게 된다면, 데이터의 수집 대상이 증가할수록 분류할 범주의 개수 또한 늘어나 모델의 성능 저하 및 학습 소요 시간과 필요 리소스가 증가하게 될 것이다.
그리고 분류 모델의 성능에서 확인할 수 있듯이 변환된 로그 시퀀스 벡터는 사용자의 행동 변화에 매우 민감하게 반응하는 것으로 나타났다. 따라서 단순 업무 패턴의 변화를 위협 가능성이 있는 행위로 탐지하여 보안 담당자에게 알려주는 false positive의 가능성이 존재한다. 위협 탐지 시스템이 ‘양치기 소년’이 된다면 보안 담당자는 점점 알람 기능을 신뢰하지 않게 될 것이다.
예상되는 문제점을 개선할 실마리를 찾기 위해 이 글의 초반부에 등장했던 A씨의 사례를 떠올려 보자. A씨의 PC가 새벽 2시에 쉘 스크립트로 인사정보 DB에 접근한 행위는 그의 평소 업무 방식과 차이가 날 뿐 아니라 그가 속한 조직의 일반적인 업무 행동에서도 크게 벗어난 행위였다. 즉, 개인의 정상 행동 상태 뿐 아니라 그가 속하는 조직 및 직무에 따른 정상 행동 상태 범위를 설정하고, 특정 사용자의 행위 로그가 본인이 소속된 조직 및 담당 직무의 정상 패턴으로부터 극단적으로 이상성을 보일 때 위협으로 탐지한다면 앞서 제시된 ‘양치기 소년’ 문제를 해결함과 동시에 생성해야 할 분류 모델 개수를 줄여 구축 및 관리 비용도 절감할 수 있을 것이다.