
생성모델(Generation Model)이란 무엇인가?
by DANBI
Introduction
Machine Learning/Deep Learning의 발전이 급격히 이루어지면서 다양한 인공지능 모델이 연구되고 만들어지고 있습니다. 최근에는 OpenAI의 GPT-3, NAVER CLOVA의 HYPERCLOVA등 거대 AI모델들이 출연하고 있습니다. 필자는 이런 모델들을 연구하고 공부하면서 이 모델자체를 어떻게 분류하는게 맞는가 하는 고민을 항상 같이 합니다. 예를 들어 어떤 모델을 사용하면 이 모델 자체를 분류모델로 보는것이 맞나? 생성모델로 보는것이 맞나? 라는 질문을 스스로 계속합니다. 사실, Pre-Trained 된 모델을 이용하여 다양한 Downstream Task에 사용하는 경우가 많아지다 보니, 어떤 Task에 사용하느냐에 따라 사용성이 결정되는 모델이 많기 때문에 이런 질문자체가 무의미한 경우도 많습니다. (ex) BERT를 이용하여 문장을 분류한다거나, Language Model의 특성을 이용하여 문장을 생성해내기도 합니다. - 물론 학습방식때문에 문장 생성은 BERT보다는 GPT-3를 권하는 경우가 많습니다.)
쉴새없이 나오는 모델들과 알고리즘을 따라가기 위해 쉼없이 공부하다 보니, 정작 분류모델과 생성모델은 근본적으로 무엇이고 어떤 차이가 있는 것인가?라는 기본적인 질문에 대한 대답을 못하고 있는 자신을 발견하게 되었습니다. 생성모델이 무엇이냐는 질문을 받으면, 데이터를 생성해주는 모델! 이라는 정도의 대답을 못하였습니다. 그렇기에 몇주~몇개월간 자료조사 및 연구를 거쳐서 분류모델과 생성모델의 차이점 그리고 생성모델은 무엇인지에 대해 정리하게 되었습니다. 다만, 자료조사를 하면서 느꼈던 점은, 생성모델 자체를 정의하고 어떤 모델이 생성모델이다라고 정확히 분류한 자료는 많지 않다는 것입니다. 그 이유는 생성모델 자체가 보통 데이터의 분포를 추정하는 모델이 대부분이다 보니 추정된 분포를 이용하여 다른 TASK에 사용되는 경우로 알려져 있는 경우가 많이 있기 때문입니다. 예를들어 아래에서 설명할 Kernel Density Estimation은 데이터의 이상치를 찾는데 많이 활용되는 모델입니다. 하지만 이는 데이터 분포를 추정하여 데이터를 생성할 수 있는 생성모델이기도 합니다. 즉 이처럼 다른 Task로 알려져있는 경우도 많이 있어 자신이 생성모델을 활용하고 있으나 이를 모르는 경우도 많이 있습니다. 필자도 그랬습니다.
여기에 정리되는 내용은 필자의 주관적인 생각도 많이 개입되어 있습니다. 어떤 것이 생성모델인가?에 대한 해답을 찾기 위해 스스로 조사하고 정리한 자료이다 보니, 잘못된 내용도 있을 수 있습니다. 발견하시면 언제든 댓글 및 저희 I&I실 이메일로 연락주시면 감사하겠습니다.
판별모델 VS 생성모델
우선 판별모델(Discriminative Model)과 생성 모델(Generative Model)의 차이를 살펴봅시다.
판별모델(Discriminative Model)이란 데이터 X가 주어졌을때 Label Y가 나타날 조건부확률 P(Y|X)를 직접적으로 반환하는 모델입니다. 분류모델이라고도 부르죠. 현재 저희 I&I실에서도 가장 많이 사용하고 있는 모델이기도 하죠. 당연히 LABEL 정보가 있어야하기 때문에 지도학습 모델이라고 볼 수 있습니다.
생성모델(Generative Model)은 두가지로 나눌 수 있습니다.
- 지도적 생성모델 : LABEL이 있는 데이터에 대해서 각 클래스 별 특징 데이터의 확률분포 P(X|Y)를 추정한 다음 베이즈 정리를 사용하여 P(Y|X)를 계산하는 방법입니다. P(Y|X)를 계산할 수 있기 때문에 분류모델로 활용할 수도 있고 클래스별 Conditional 확률 P(X|Y)를 추정했기 때문에 확률분포 상에서의 새로운 가상의 데이터를 생성하거나 확률분포 끝자락에 있는 데이터를 이상치로도 판단하는 이상치 판별 모델로도 활용할 수 있습니다. 아래 그림을 보면 조금 더 이해하기 편하실 것 같습니다.
![]()
출처 : https://sites.google.com/site/machlearnwiki/bayesian-learning/saengseong-model
- 비지도적 생성모델 : LABEL이 없어서, 데이터 X자체의 분포를 학습하여 X의 모분포를 추정하는 학습데이터의 분포를 학습하는 모델입니다. 실제 대부분의 생성모델은 이 비지도적 생성모델이라고 생각하면 될 것 같습니다. GAN기반의 모델류들을 이용하여 새롭고 신기한 사진을 생성해내는 경우를 많이 보셨을텐데요. 원본이미지(X)의 확률분포를 학습하여 새로운 데이터를 생성해내는 비지도적 생성모델의 대표적인 예시입니다.
생성모델의 종류
위에서 설명하였듯이 생성모델은 지도적 생성모델 / 비지도적 생성모델로 나눌수 있습니다. 실제 예시와 함께 더 깊게 살펴봅시다.
1. 지도적 생성모델
지도적 생성모델의 대표적인 예시로는 선형판별분석법(LDA), 이차판별분석법(QDA)가 있습니다. 다음은 지도적 생성모델을 모델링하는 방법인데요.

출처 : https://datascienceschool.net/intro.html
가능도, 즉 y의 클래스값에 따른 X의 분포에 대한 정보를 먼저 알아낸 후 , 베이즈 정리를 사용하여 주어진 X에 대한 Y의 확률분포를 찾는 것입니다. 사전확률은 보통 Y의 비율로 두는 경우가 많죠. 이차판별분석법(QDA)의 경우에는 다음과 같이 우도를 가정하는 것입니다. 즉, 독립변수 X가 실수이고 확률분포가 다변수 정규분포라고 가정하는 것입니다. 이 분포들을 알고 있으면, 독립변수 X에 대한 Y클래스의 조건부확률분포는 위의 식을 따라 구할 수 있겠죠?
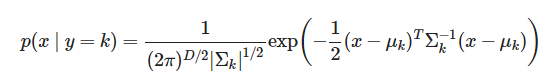
출처 : https://datascienceschool.net/intro.html
선형판별분석법과 이차판별분석법에 대해서 조금 더 자세하게 알고 싶다면 위 수식 출처에 있는 블로그를 추천드립니다.(제가 본 곳중에서 가장 상세하고 쉽게 설명이 되어 있네요.) 추가적으로, 선형판별분석법의 경우는 PCA와 같은 차원축소 기법으로 알려져있기도 하고, 분류모델로도 알려져있습니다. Introduction에서 설명드린것처럼, 이렇게 생성모델은 다른 task에서 쓰이고 있는 경우가 많습니다. 그래서 필자도 원래는 이게 생성모델이라고 생각을 못했었죠.
2. 비지도적 생성 모델
다음은 생성모델의 대부분을 차지하고 있는 비지도적 생성모델을 확인해봅시다. 비지도적 생성 모델은 종류가 많아 통계적 생성 모델 그리고 딥러닝에서의 생성 모델로 분류를 해봤습니다.
2-1. 통계적 생성 모델
통계적 생성 모델이란 밀도 추정을 의미한다고 생각하면 좋을것 같습니다. 관측된 데이터들의 분포로부터 원래 변수의 확률분포를 추정하고자 하는 것이 밀도 추정입니다. 사실상 통계 책에 나오는 모수적/비모수적 추정과 같죠. 대표적인 예시로 커널 밀도 추정(Kernel Density Estimation)이 있습니다. 랜덤변수 X에 대한 PDF를 다음과 같이 추정하는 것입니다. 어떤 커널 모양이냐에 따라 PDF가 달라지겠죠?
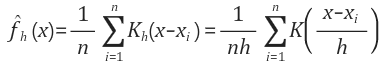
아래 왼쪽 그래프를 보시면, 검은색 선이 원 데이터를 나타내고 , 이에 걸맞는 분포를 Kernel값을 통해 추정하는 겁니다. 여기서 커널은 ‘가우시안’, ‘TOPHAT’, ‘EPANECHNIKOV’를 사용했는데요, 원 데이터의 분포를 잘 추정하고 있음을 확인할 수 있습니다. 이처럼 원 데이터의 분포를 추정하는 생성모델을 Kernel Density Estimation이라고 합니다. 원 데이터의 분포를 추정했기 때문에 추정한 분포로부터 새로운 데이터를 생성할 수 있겠죠?오른쪽 MNIST 사진을 보시면 MNIST 픽셀들의 분포를 학습하여, KDE로 새로운 숫자이미지를 생성한 것입니다.
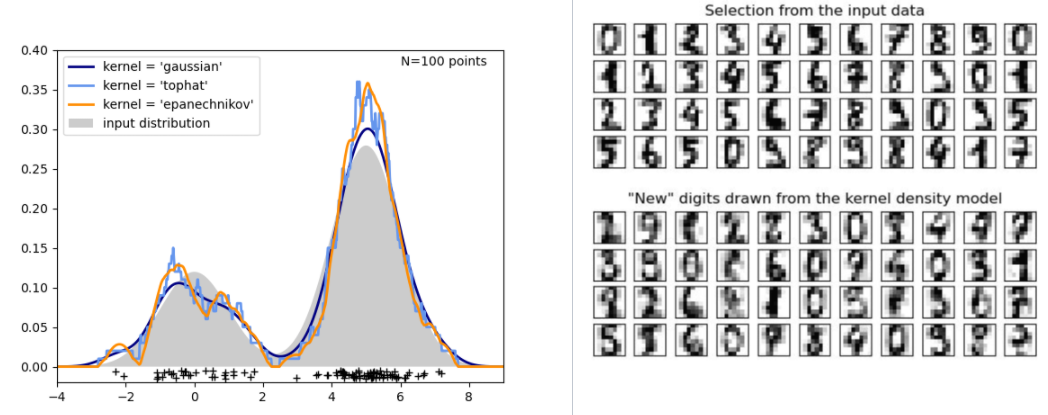
출처 : https://jayhey.github.io/novelty%20detection/2017/11/08/Novelty_detection_Kernel/
또 하나 소개드릴 통계적 생성모델은 가우시안 밀도 추정/혼합 가우시안 밀도 추정 모델입니다. 사실 간단한데요. 원래의 분포가 정규분포를 따른다고 가정하는 것입니다. 혼합가우시안 밀도 추정 모델은 여러 가우시안 분포의 합으로 이루어져있다고 가정하는 것이죠. 왼쪽 아래 그림을 보시면 파란색 데이터 분포를 정규분포로 가정하고, 각각의 끝자락에 있는 부분들을 이상치로 판단하죠. 이렇게 원 데이터의 분포를 학습해 이상치 탐지 모델로도 쓰입니다. 혼합가우시안 모델 같은 경우는 군집화 방법으로도 활용이 됩니다. 우리가 많이 사용하는 k-means 같은 경우는 하나의 데이터는 하나의 군집에만 속할 수 있지만, GMM(Gaussian Mixture Model)같은 경우에는 한데이터가 여러군집에 속할 수 있으며, 각각의 군집에 속할 확률을 나타냅니다. GMM에서 쓰이는 EM알고리즘은 너무 복잡해서 여기서는 생략할게요…ㅎㅎ (여담으로 EM알고리즘은 Youtube를 통해 Expectation, Maximization과정이 어떻게 순차적으로 이뤄지는지 동영상을 통해 보는게 더 좋습니다. 수식으로 하면 머리 깨져요..)
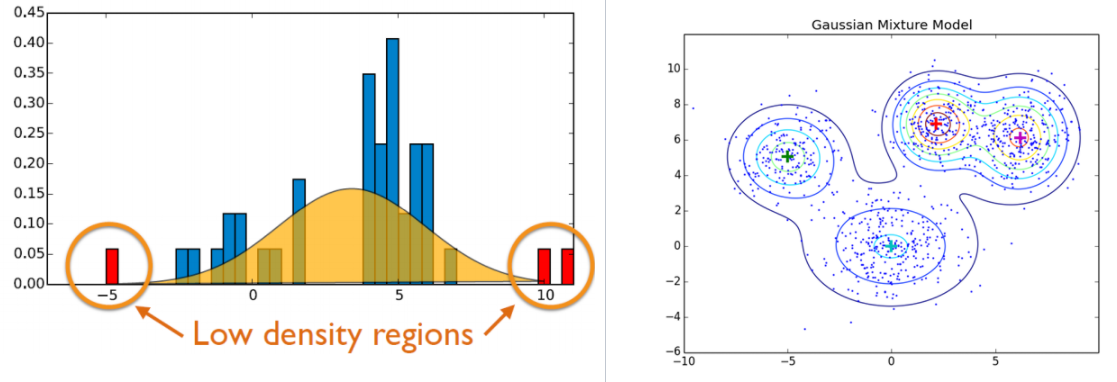
출처 : https://jayhey.github.io/novelty%20detection/2017/11/02/Novelty_detection_Gaussian/
2-2. 딥러닝을 이용한 생성 모델
다음은 딥러닝을 이용한 생성모델입니다. 생성모델이라는 것은 결국 많은 데이터를 필요로 합니다. 그러다 보니 대량의 데이터를 학습하는 딥러닝 분야에서 그 발전이 더 두드러지죠. 딥러닝을 이용한 생성모델 같은 경우는 많은 모델들이 있고 이를 이미 분류해주신 분이 계신데요. 바로 선구자이신 Ian Goodfellow님께서 gan tutorial을 하시면서 설명해주신 ppt자료입니다. (아래사진부터는 https://minsuksung-ai.tistory.com/12 에서 가져온 사진들입니다. )
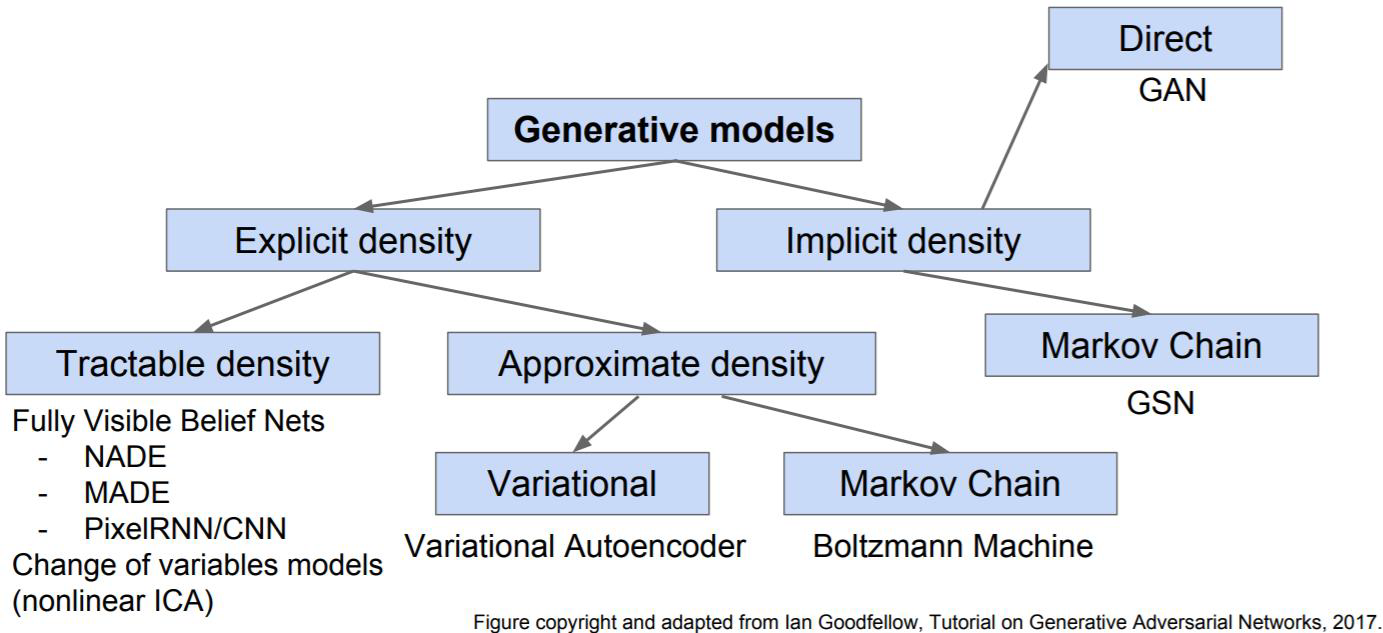
Ian Goodfellow께서생성모델을 세분화해서 크게 3가지로 나눠주셨는데요. 결국 위의 통계적 생성모델처럼 확률분포를 추정하는 건 똑같으나, 어떤 방식으로 추정할지에 따라서 구분하셨다고 합니다.
- Tractable Density : 데이터 X를 보고 확률분포를 ‘직접’ 구하는 방법
- Approximate Density: 데이터 X를 보고 확률분포를 ‘추정’하는 방법
- Implicit Density : 데이터 X의 분포를 몰라도 되는 방법
하나씩 예시와 함께 설명해볼게요.
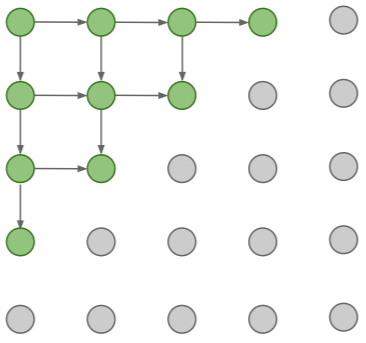
Tractable Density : Pixel RNN
이전 픽셀이 어떤 것인지에 따라 다음 픽셀이 무엇이 나오는지를 순서대로 확인(학습)하는 모델입니다. Chain Rule을 통해서 직접적으로 학습데이터의 분포를 구하는 것이라고 볼 수 있죠. 아래 그림을 보면 조금더 이해하기 쉬울 겁니다. 이렇게 해서 이미지 전체에 대한 확률분포를 직접적으로 구하는 모델을 만드는 것이죠.이처럼 이전 픽셀의 정보를 가지고 있어야 다음 픽셀의 분포를 알 수 있기에, 직접적으로 확률분포를 구하는 방법이라고 볼 수 있습니다.

Approximate Density : VAE(Variational Auto-Encoder)
실제 많이 사용하는 VAE입니다. 원 데이터의 Feature를 압축해서 복원하는 Encoder-Decoder 관게를 이용하죠. 하지만 VAE의 경우는 Auto-Encoder와는 살짝 차이가 있습니다. latent vector에 정규분포 항을 추가하여, latent vector를 조금씩 변형하면서 복원하는게 그 목적이죠. 그렇다면 다양한 종류의 데이터를 생성해낼 수 있겠죠. VAE는 학습시 두가지 에러를 사용합니다. Reconstruction Loss, Regularization Loss. 직관적으로는 생성모델이 만든 새로운 데이터와 원래 데이터와의 관계를 살펴보는 것이 Reconstrucion Loss 입니다. 데이터가 원래 가지는 분포와 동일한 분포를 가지게 학습하기 위해 True분포를 추정한 함수의 분포에 대한 loss term이 Regularization loss입니다. 자세한 설명은 생략하였지만, 이처럼 VAE는 원 데이터의 분포를 추정하고 이를 맞추려고 하면서 학습되는 방법을 사용합니다.
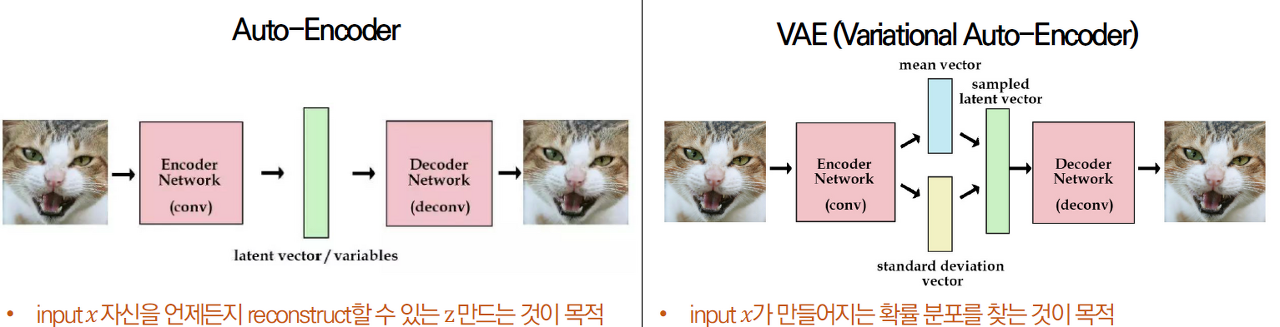
출처 : https://velog.io/@ohado/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EA%B0%9C%EB%85%90-1.-VAEVariational-Auto-Encoder
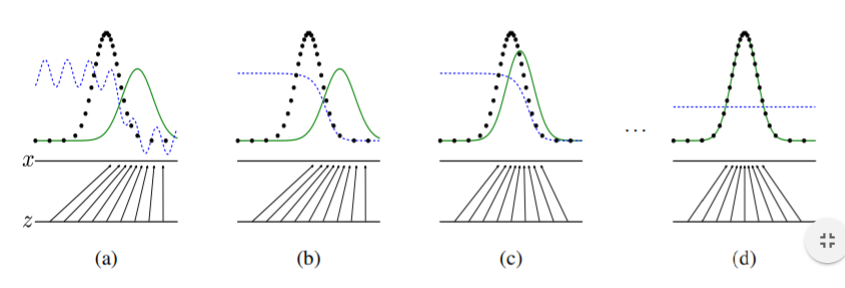
Implicit Density : GAN
위에서 Implicit Density의 경우 데이터 X의 분포를 ‘몰라도’ 된다고 했습니다. 이는 GAN의 특이한 점 때문인데요. 바로 판별기, 생성기가 서로 경쟁하면서 학습이 되고, 학습과정을 자세하게 들여다보면 생성기에는 실제 데이터가 들어가지도 않습니다. 오직 판별기가 차이를 구분해주죠. 그렇기에 생성기는 데이터 X를 쳐다본적도 없게 된 겁니다. 이런 특성으로 인해 실제 데이터를 쳐다보지 않는다고 표현한 것입니다. 아래 사진처럼, 원 데이터 분포와의 차이를 줄여나가는 방향으로 판별기와 생성기가 경쟁학습을 해서 원 데이터의 분포를 찾게 되는 것이죠. 물론 LATENT VECTOR Z의 역할이 중요합니다만, 여기서는 다루지 않겠습니다.
GAN에 대해서는 너무나 많은 자료와 연구가 있기에 더 자세하게 다루지는 않겠습니다. 다만, 저희 I&I실처럼 다량의 시계열 데이터를 다루는 곳에서 GAN을 사용하면 어떨까 하는 고민을 해본적이 있습니다. 보통 GAN은 시계열 데이터보다는 이미지/영상에 많이 쓰이는데요. MIT연구팀이 개발한 TadGAN 알고리즘은 시계열 데이터를 분석하여 이상치탐지를 하는데에 있어 좋은 성능을 나타내는 것으로 알려져 있습니다. 아래 그림을 보시면 TRAIN 데이터를 기반으로 Reconstructed data를 구축하고, 새로운 데이터가 들어오면 기 구축된 Reconstructed data와 새로운 데이터 사이에 이상 구간을 탐지하여 Anomaly error score를 계산하고 threshold에 맞게 이상치 구간을 탐지합니다. 현재 TadGAN은 놀라운 효과를 내고 있으며 많은 곳에서 연구와 적용이 이루어지고 있습니다. 앞으로 게임에서 발생하는 이상치(이상현상들)에 대해서 적용해보는 연구를 할 계획입니다.
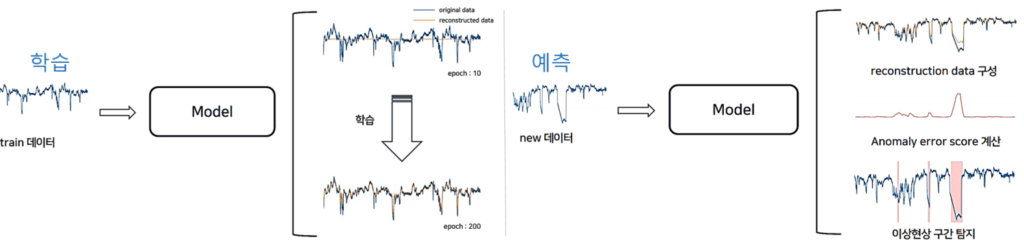
출처 : https://smilegate.ai/2021/06/01/tadgan/
마치며
지금까지 필자가 정리한 생성 모델의 내용을 소개해드렸습니다. 저만의 기준, 그리고 여러가지 소스에서 복잡하게 짬뽕한 내용이라, 틀린 부분도 있을 수 있습니다. 언제든 피드백을 환영합니다. 또한 생성모델을 어떻게 분류해볼 수 있을지에 대해 정리한 내용이라, 각각의 알고리즘에 대한 설명은 많이 부족합니다. 상세한 부분은 잘 정리된 자료가 많이 있으니 참고하시기 바랍니다.
현재 이루어지는 연구들 많은 부분들이 생성모델의 관점에서 이루어지고 있습니다. 그만큼 AI분야에서는 중요한 연구주제이고, 이를 I&I실에서 주로 다루는 게임 데이터에 적용하고 그 결과도 포스팅하려 합니다.