
도메인 지식이 결여된 인과 추정이 위험한 이유
by DANBI
시작하며
간혹 ‘데이터 분석가에게 도메인 지식이 필요한가?’ 에 대한 질문을 받거나 관련된 논의글을 보곤 합니다. 전 도메인 지식이 필요할 뿐만 아니라 도메인 지식이 없는 상태에서 데이터 분석을 하는 것은 위험하다는 입장입니다. 특히, 분석의 목적이 인과 추론인 경우에는 더욱 그렇습니다. 이번 글에서는 가상의 사례를 통해 그 이유를 설명할까 합니다.
다음과 같은 네 가지 경우를 생각해 봅시다.
다음과 같은 네 가지 경우(df1 ~ df4)의 인과 관계를 갖는 사례가 있다고 가정해 보겠습니다. 아래 도식에서 동그라미는 각각의 변수를 의미하며, 화살표가 있는 실선은 두 변수가 화살표 방향으로 인과 관계에 있는 것을 의미합니다. 또한 실선 옆에 표시된 숫자는 원인 변수가 결과 변수에 미치는 인과 효과를 의미합니다. 예를 들어, df1 사례에서 x1 으로부터 y 로 향한 실선에 표시된 1.5는 ‘x1 변수의 값이 1만큼 증가하면 y 변수의 값이 평균적으로 1.5 만큼 증가하는 경향이 있다’는 것을 의미합니다.
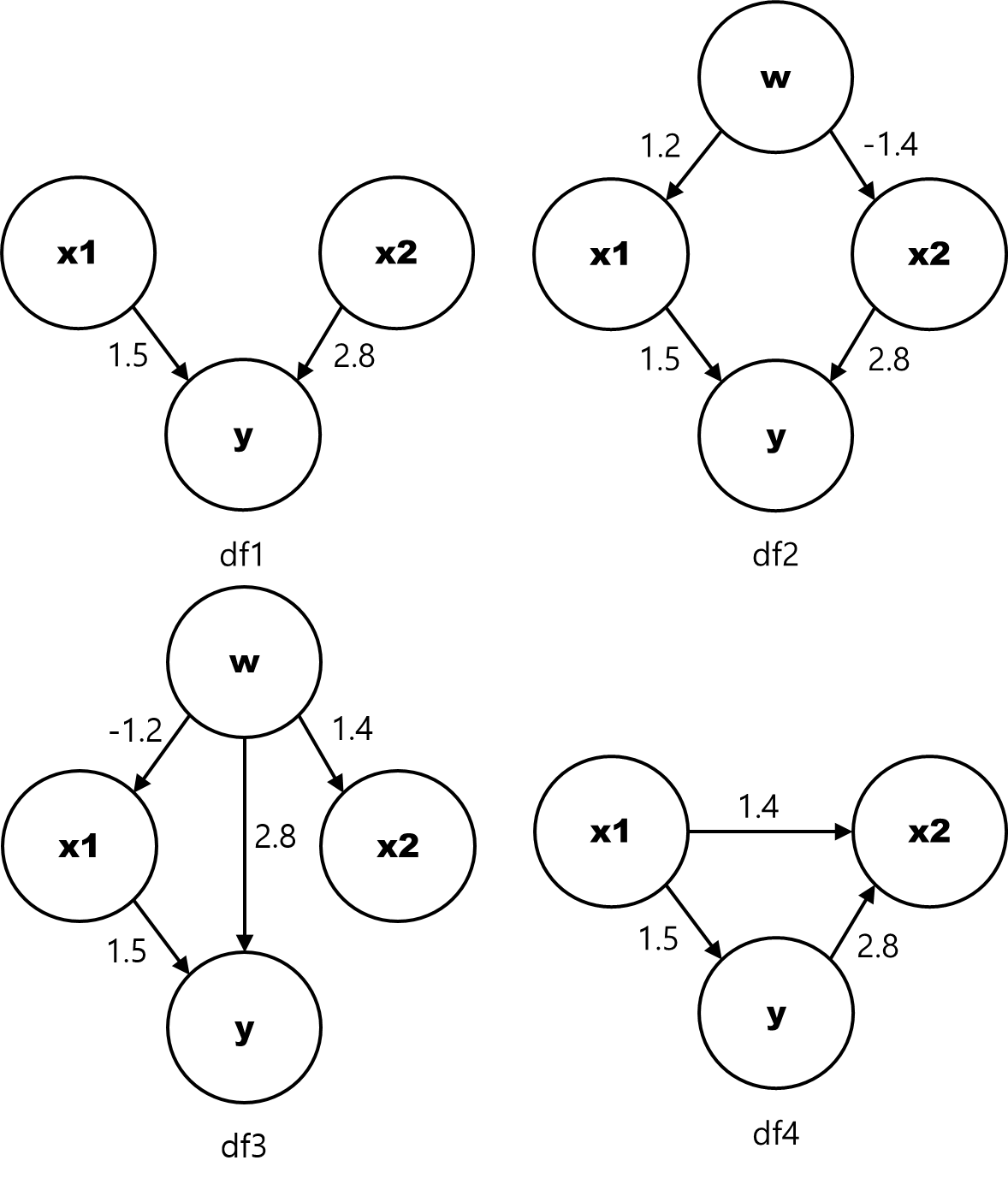 [그림1] 인과 관계 그래프
[그림1] 인과 관계 그래프
R코드를 이용해 각 사례를 나타내는 가상의 데이터를 생성해 보면 다음과 같습니다.
N <- 100
set.seed(1)
x1 <- rnorm(N)
x2 <- rnorm(N)
y <- 1.5*x1 + 2.8*x2 + rnorm(N)
df1 <- data.frame(y, x1, x2)
w <- rnorm(N)
x1 <- 1.2 * w + rnorm(N)
x2 <- -1.4 * w + rnorm(N)
y <- 1.5 * x1 + 2.8*x2 + rnorm(N)
df2 <- data.frame(y, x1, x2)
w <- rnorm(N)
x1 <- -1.2 * w + rnorm(N)
x2 <- 1.4 * w + rnorm(N)
y <- 1.5 * x1 + 2.8 * w + rnorm(N)
df3 <- data.frame(y, x1, x2, w)
x1 <- rnorm(N)
y <- 1.5 * x1 + rnorm(N)
x2 <- 1.4 * x1 + 2.8 * y + rnorm(N)
df4 <- data.frame(y, x1, x2)
이제 위와 같이 생성된 데이터가 주어졌을 때, 회귀 분석을 통해 y와 인과 관계를 갖는 원인 변수의 인과 효과를 정량적으로 추정하는 한 데이터 분석가가 있다고 생각해 보겠습니다.
1) 첫번째 사례 - df1
우선 df1 를 살펴보면, x1과 x2는 서로 독립이고 둘 다 종속변수인 y에 인과적 영향을 주며 오차항은 정규분포를 갖습니다. OLS 회귀의 가정에 충실한 데이터입니다. 이 데이터가 주어졌을 때 아무런 도메인 지식이 없는 분석가가 R 을 이용하여 회귀 분석을 한다면 아마 다음과 같은 세 가지 모형을 만들 수 있을 겁니다.
summary(lm(y ~ x1, df1))
summary(lm(y ~ x2, df1))
summary(lm(y ~ x1 + x2, df1))
그리고 그 결과는 아래와 같습니다 (중요한 정보는 빨간색 상자로 감쌌습니다).
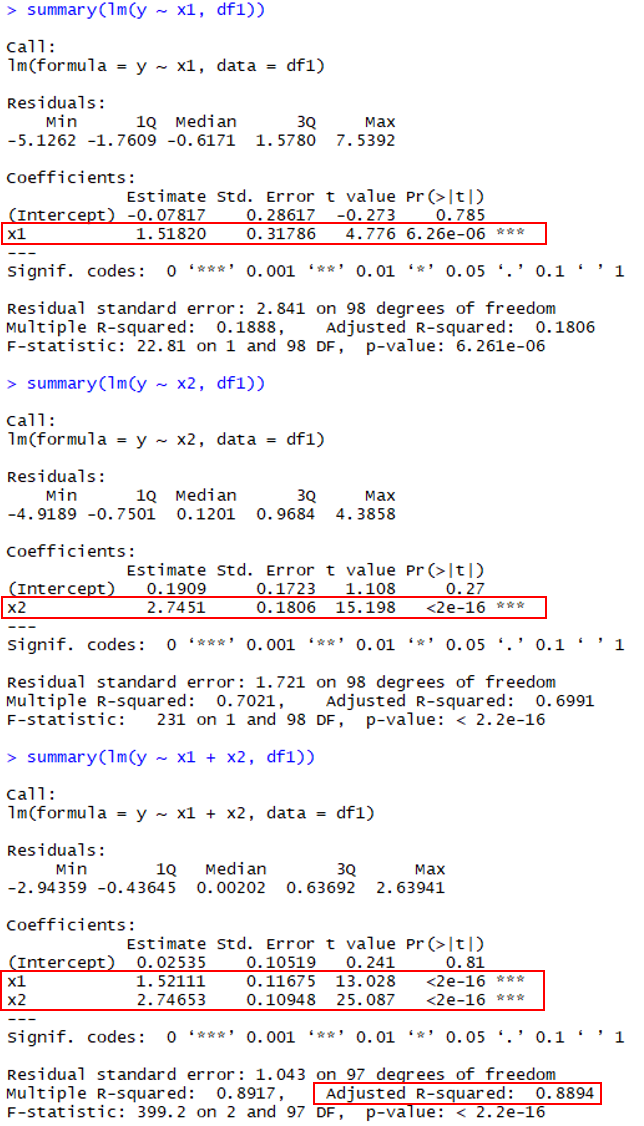 [그림2] 모든 모델에 대해서 x1과 x2의 회귀 계수는 통계적으로 유의하며 y ~ x1 + x2 모델은 매우 높은 설명력 (Adjusted R-sqaured) 을 갖습니다.
[그림2] 모든 모델에 대해서 x1과 x2의 회귀 계수는 통계적으로 유의하며 y ~ x1 + x2 모델은 매우 높은 설명력 (Adjusted R-sqaured) 을 갖습니다.
보다시피 x1 이나 x2 에 대해 각각 회귀 모델을 만들더라도 회귀 계수가 실제값에 가깝게 잘 추정됩니다. 물론 두 변수를 모두 사용한다면, 설명력까지 높은 금상첨화의 회귀 모델이 만들어집니다. 분석가는 행복합니다.
2) 두번째 사례 - df2
이제 df2 데이터를 살펴보죠. 이번에도 y에 대한 x1과 x2의 영향력은 df1 과 동일하지만 x1과 x2가 둘 다 w 라는 변수와 인과적 관계를 갖고 있습니다. 따라서 x1과 x2는 이제 아주 높지는 않지만 통계적으로는 충분히 유의한 상관관계가 있습니다.
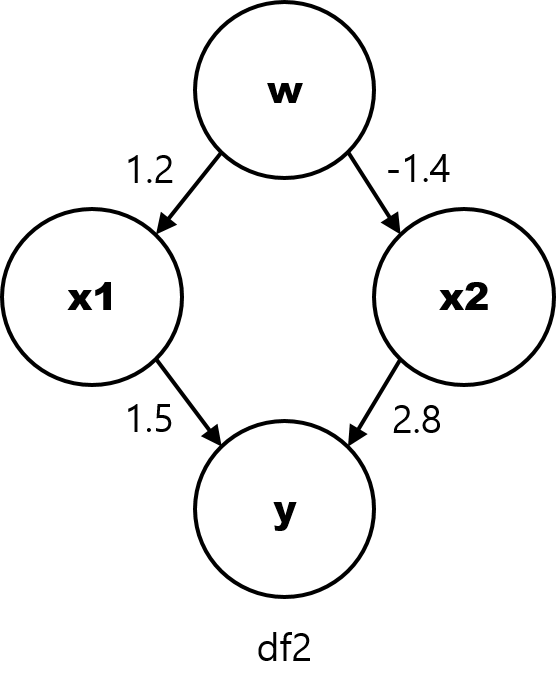 [그림3] df2 의 인과 관계 그래프
[그림3] df2 의 인과 관계 그래프
이런 상태에서 이전과 동일하게 회귀 모델을 만들어 보면 그 결과는 다음과 같이 나옵니다.
summary(lm(y ~ x1, df2))
summary(lm(y ~ x2, df2))
summary(lm(y ~ x1 + x2, df2))
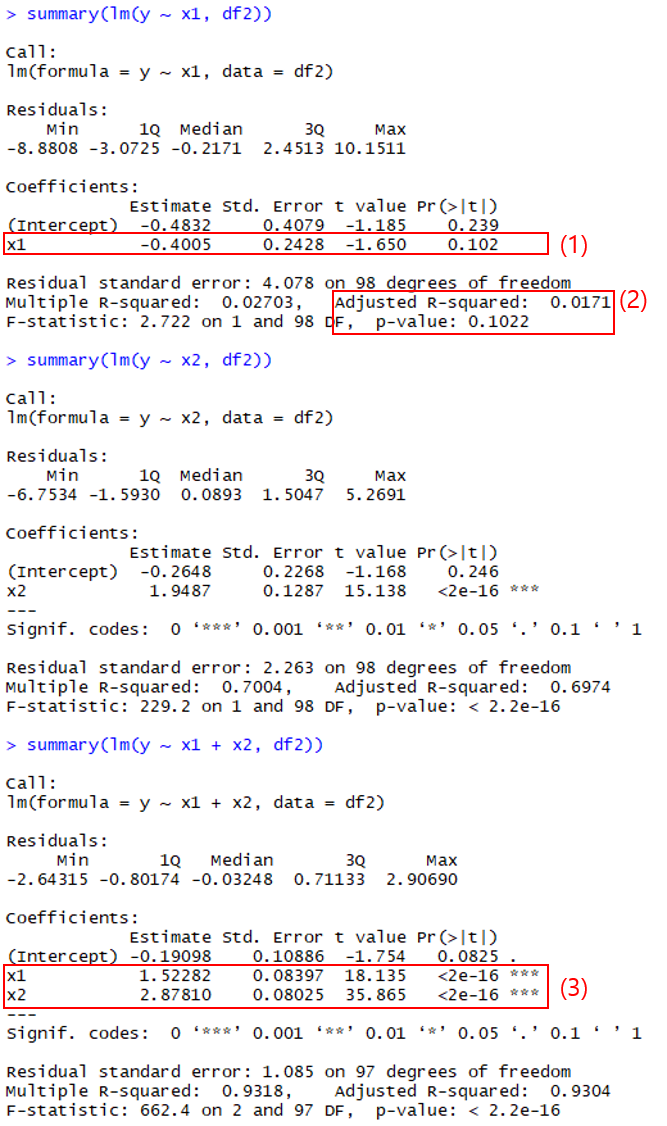 [그림4] x1과 x2를 모두 모델에 반영하지 않으면 인과 관계를 잘못 추정하게 됩니다.
[그림4] x1과 x2를 모두 모델에 반영하지 않으면 인과 관계를 잘못 추정하게 됩니다.
위 결과에서 y ~ x1 모델은 회귀 계수가 -0.4005 로 나오는데 이것은 실제값인 1.5와 비교했을 때 완전히 잘못된 (심지어 부호도 반대인) 추정치입니다 (<그림4> 의 (1)). 게다가 모델의 p-value 는 0.102로 높으며, 설명력(Adjusted R-squared) 은 0.0171로 매우 낮게 나옵니다 (<그림4> 의 (2)). 따라서 이 결과만 보면 x1은 y와 인과 관계가 없는 변수라고 잘못된 결론을 내릴 수 있습니다. 어쩌면 (최악의 경우), 분석가는 여러 차례의 샘플링과 회귀 분석의 반복을 통해 통계적으로 유의한 p-value를 얻을지도 모릅니다. 그러면 '초콜릿이 다이어트에 효과가 있다.' ([관련기사](http://sbsfune.sbs.co.kr/news/news_content.jsp?article_id=E10009770001)) 와 같은 헤프닝이 생기는 것이죠.
결국 첫번째 경우와 달리 x1과 x2를 모두 모델에 정확히 반영해야 제대로된 영향력이 추정됩니다 (<그림 4>의 (3)). 다시 말해, 현실 세계에서 위와 같은 경우가 존재할 때 만약 두 변수 중 하나라도 수집 단계에서 누락하거나 혹은 분석 단계에서 모형 설계를 잘못한다면, 분석가는 완전히 잘못된 결론을 내릴 수 있습니다.
3) 세번째 사례 - df3
df3 에서 w는 x1과 x2 뿐만 아니라 y에도 인과적 영향을 끼치는 ‘교란 변수 (confounder)’ 입니다. 한편, x1 은 앞서와 동일하게 y와 인과 관계가 있는 반면, x2는 y와 인과적으로 관련이 없습니다 (하지만 w라는 공통 요인이 있기 때문에 상관 관계는 존재합니다).
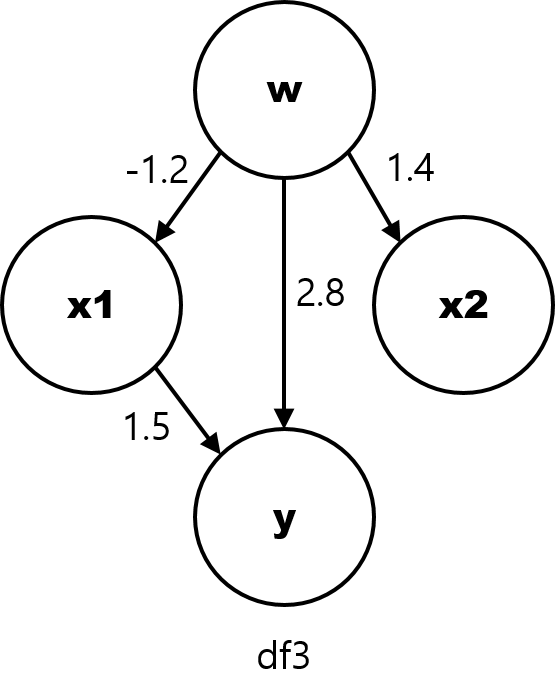 [그림5] df3 의 인과 관계 그래프
[그림5] df3 의 인과 관계 그래프
이제 df3에 대해서 회귀 분석을 수행하면 그 결과는 다음과 같습니다.
summary(lm(y ~ x1, df3))
summary(lm(y ~ x2, df3))
summary(lm(y ~ x1 + x2 + w, df3))
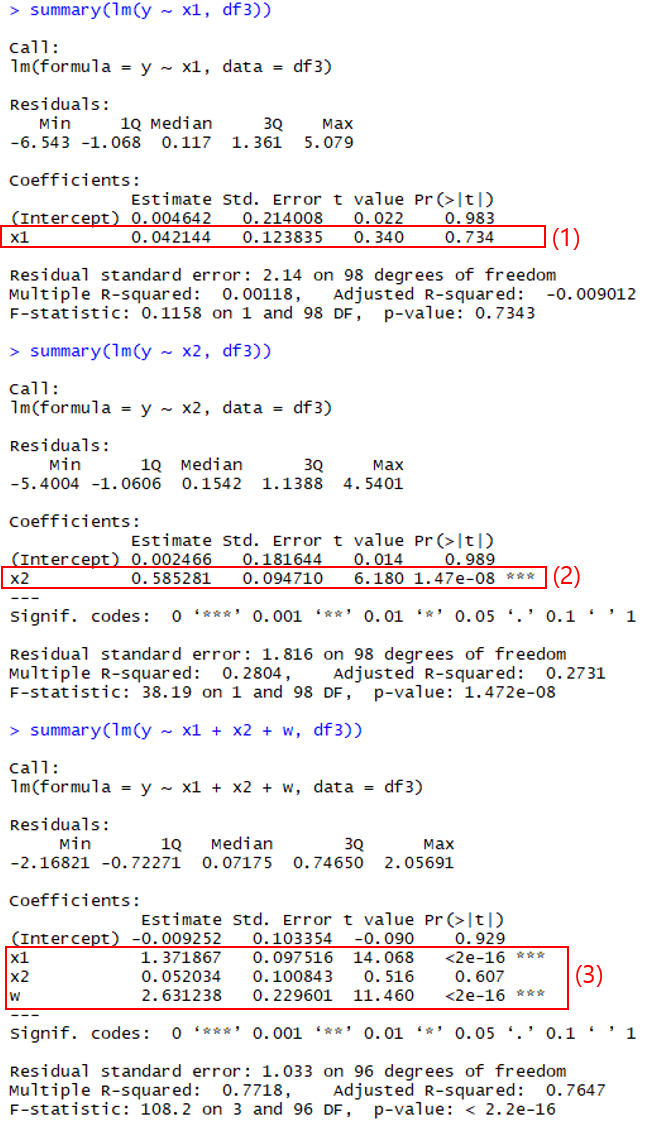 [그림 6] 교안 변수인 w를 모델에 포함하지 않으면 잘못된 추정 결과가 나옵니다.
[그림 6] 교안 변수인 w를 모델에 포함하지 않으면 잘못된 추정 결과가 나옵니다.
분석 결과를 보면 실제와는 반대로 y ~ x1 보다 y ~ x2 모델이 통계적으로 더 유의하다고 나옵니다 (<그림 6>의 (1)과 (2)). 다시 말해, 교란 변수인 w 를 회귀 모델 설계 시 누락할 경우 y에 인과 효과를 미치는 변수가 x1이 아니라 x2라는 잘못된 결론이 나올 수 있습니다. 반면, w를 회귀 모델에 포함시키면 x1과 w의 인과 효과는 비교적 잘 추정되며 x2는 통계적으로 유의하지 않다고 나옵니다 (<그림 6>의 (3)).
여기까지만 보면 ‘가급적 다양한 데이터를 수집해서 최대한 많은 변수를 넣은 모델을 만들어야겠다’ 고 생각하는 분들이 있을지도 모르겠습니다만, 그런 분들을 위해 마지막 사례가 준비되어 있습니다.
4) 네번째 사례 - df4
이번에는 기존과 구조가 좀 다릅니다. y에 영향을 주는 변수는 x1 하나뿐이며, x2는 이제 x1 과 y 로부터 인과적 영향을 받는 결과 변수입니다. 통계학에서는 x2와 같은 변수를 ‘collider’ 라고 부릅니다.
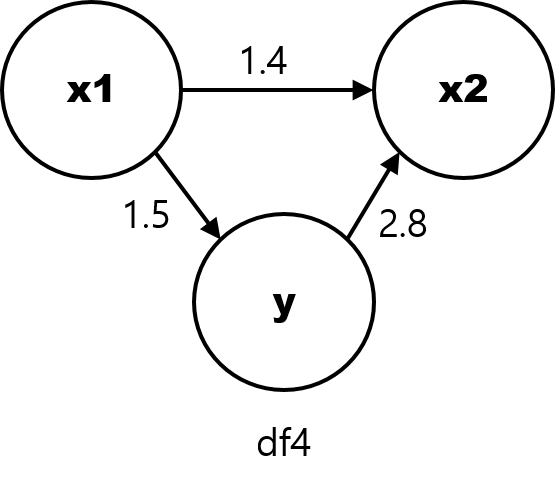 [그림7] df4 의 인과 관계 그래프
[그림7] df4 의 인과 관계 그래프
이제 이 데이터를 이용해 회귀 모델을 만들어 봅니다.
summary(lm(y ~ x1, df4))
summary(lm(y ~ x2, df4))
summary(lm(y ~ x1 + x2, df4))
 [그림 8] collider를 모델에 포함시키면 잘못된 추정 결과가 나옵니다.
[그림 8] collider를 모델에 포함시키면 잘못된 추정 결과가 나옵니다.
여기서 y ~ x1 모델은 올바른 추정을 합니다 (<그림 8>의 (1)). 또한 y ~ x2 모델 역시 유효한 모델로 나옵니다 (이건 y와 x2 사이에 역인과 관계가 있기 때문입니다). 가장 큰 문제는 세번째 모델입니다. y ~ x1 + x2 모델은 x1의 회귀 계수를 완전히 잘못 추정하고 있는데, 통계적 유의성은 충분히 갖추고 있으며 심지어 설명력(Adjusted R-squared)은 가장 높습니다 (<그림 8>의 (2)).
결국 모델의 결과만 보면 y ~ x1 + x2 모델이 가장 좋은 모델이라는 결론이 나옵니다. 물론 이것은 실제와 완전히 다릅니다.
도메인 지식이 없는 통계 전문가는 위험하다.
(적어도 제가 아는 한) 통계적 기법을 통해 위 예시들을 정확히 구분해 내기는 대단히 어렵습니다. 통계 기법은 주어진 모델에 대한 유의성 검정을 할 수 있을 뿐, 데이터를 보고 자동으로 모델을 만들어 주지는 못합니다. 그런데 위 예시를 보면 알 수 있듯이 잘못 설계된 모형을 적용하면 현실과 동떨어진 검정 결과가 나오기 쉽습니다. 최근에 인과 구조를 자동으로 생성해 주는 기법에 대한 많은 연구가 이뤄지고 있지만, 아직까지는 (여기에 나온 예시와 비교할 수 없을 만큼) 복잡한 인과적 구조를 갖고 있는 현실 데이터에 적용하기에는 넘어야할 산이 많습니다.
결국, 이런 오류를 피하기 위한 현실적인 방안은 충분한 도메인 지식을 통해 최대한 논리적이고 합리적인 모델 및 실험 구조를 설계한 후 관측 데이터에 적용함으로써 구체적이고 정량적인 효과를 추정하는 것입니다. 적어도 아직까지는 그렇습니다. 때문에 통계적 지식이 결여된 도메인 전문가 못지않게 도메인 지식이 결여된 통계 전문가 역시 위험합니다. 전자가 문제를 잘못 푸는 경향이 높다면, 후자는 잘못된 문제를 푸는 경향이 높습니다.
참고로 여기서 제가 얘기한 ‘도메인 지식이 필요하다’가 ‘도메인 전문가가 되어야 한다’를 의미하는 것은 아닙니다 (몸이 건강해지려면 운동을 해야 한다란 말이 운동 선수가 되라는 뜻은 아니죠).
예측 모델을 인과적으로 해석하는 것은 위험하다.
한편, 모델링의 목적이 오로지 ‘종속 변수(y)에 대한 예측’ 이라고 하면 문제가 좀 더 수월해집니다.
가령, 네번째 사례에서 y ~ x1 + x2 모델은 비록 실제 인과 구조를 틀리게 추정했지만 설명력 자체는 y ~ x1 보다 좋습니다. 따라서 목적이 y 값을 예측하는 것이라면 그냥 세번째 모델을 이용해도 괜찮습니다. 현재의 데이터 분석 분야가 예측 분석에 집중하고 있는 것은 이 때문입니다. 인과 추론보다 예측이 훨씬 더 쉽습니다.
그런데 예측 결과가 잘 맞는다고 해서 요즘 유행하는 interpretable ML 관련 기법을 써서 예측 모델에 대해 인과적으로 해석하거나 의사 결정에 활용하려고 하면 다시 위 사례와 같은 오류에 빠지게 됩니다. 이를테면, 예전에 이탈 예측 경진 대회를 진행했을 때, 많은 참가팀들이 자신들의 예측 모델을 해석하기 위해 PDP, SHAP Value, LIME 등을 써서 특정 변수가 이탈 예측 모델의 결과값에 미치는 관계를 분석한 후, ‘이러이러한 유저들이 이탈하는 경향이 있다.’ 라는 식으로 발표하는 경우가 많았습니다 (https://danbi-ncsoft.github.io/competition/2019/02/19/big-contest-2018-retrospect.html). ‘우리 모델은 이러이러한 경우 이탈할 것으로 판단하는 경향이 있다.’ 가 좀 더 맞는 해석입니다.
예측 모델을 사용할 때는 예측 결과 자체를 어떻게 서비스에서 잘 활용할지에 대해서만 고민해야 합니다.