
인과추론 분석 설계에서 도메인 지식이 필요한 이유
by DANBI
시작하며
단비에서는 기존에 “인과관계를 찾아서” 시리즈와 도메인 지식 결여에 따른 인과추론 분석의 위험성 (도메인 지식이 결여된 인과 추청이 위험한 이유 )게시글을 통해 인과관계 추론 분석에 대해 언급한바 있다. 인과관계 추론 분석이 어려운 이유는 앞의 위험성에 관한 게시물에서도 언급되었듯이 인과관계를 추론할 수 있는 영향 변수들을 찾아내는 것이 쉽지 않고 분석가의 도메인 지식이 부족한 경우 분석 설계를 잘못하여 엉뚱한 해석 결과를 내놓을 수 있기 때문이다. 이와 관련하여 엄밀하게 설계된 실험이 불가능한 사회 과학 영역 분석의 위험성을 극복하기 위해 고안한 장치인 도구변수에 대해서도 과거 소개한 바 있다(인과관계를 찾아서 3:도구변수). 하여 이번 글에서는 Joshua D. Angrist의 저서 ‘고수들의 계량경제학’에 소개된 도구변수를 사용한 여러 인과추론 분석 사례를 살펴보면서 단기간에 충분한 도메인 지식을 습득하기 어려운 분석가가 참고하면 좋을 분석 설계 방식을 나눠보고자 한다.
사례1. 헌장학교의 교육효과

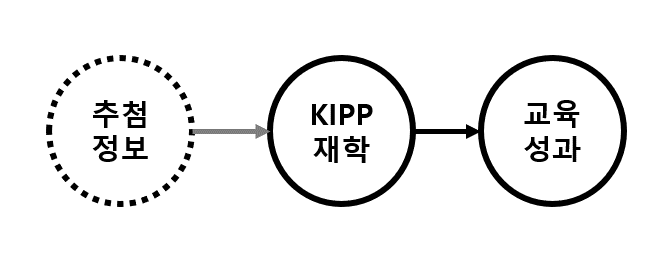
헌장학교(Knowledge Is Power Program, 이하 KIPP)는 미국에서 성적이 안좋은 지역의 교육 개혁을 위해 설립된 공립학교로 일반 공립학교에 비하여 교사 채용과 교육 시간 등의 운영방식이 자율적이라는 면에서 차별점을 둔 학교다. 연구자들은 실제로 KIPP에 진학하는 학생들의 성적이 향상되는지 알아보기 위해 보스턴의 린이라는 도시에 설립된 KIPP의 데이터를 분석하였다.
성적 향상 여부 확인을 위해 진학 직전의 수학 점수와 진학하여 1년이 지난 후의 수학 점수를 비교하였는데, 단순히 KIPP에 진학한 학생과 다른 공립학교 재학생의 수학 성적 향성 여부를 비교할 경우 학생들의 ‘학습 의지’의 차이를 고려하지 못하는 문제가 있었다. KIPP에 지원한 학생들은 애초에 학습에 대한 의지가 높기 때문에 (KIPP 재학 여부와 상관없이) 성적이 오를 가능성이 높기 때문이다. 따라서 KIPP 재학 여부에 따른 교육 성과의 차이가 존재하는지 분석하려면 학습 의지가 비슷한 학생끼리 비교하는 방법이 필요했다. 연구자들은 이를 위해 당국에서 정한 특정 기준을 만족하는 학생들에 한해 추첨을 통해 입학 자격을 부여하는 ‘추첨 정보’를 도구변수로 사용하였다. 추첨은 임의로 진학 여부를 선정하는 것이기 때문에 학생들의 학습 의지로 인해 성적 향상에 영향을 주는 선택편의가 제거될 수 있기 때문이다.

[표1]은 KIPP에 진학한 학생과 일반 공립학교에 진학한 학생들의 수학 점수 변화를 비교한 자료이다. KIPP 진학 여부만 놓고 단순 비교한 경우 교육 성과(수학 점수)가 0.467만큼 상승하며, 추첨을 통해 당첨된 경우와 탈락된 경우를 고려하여 비교하면 0.478증가하는 것으로 나타난다. 이를 통해 KIPP가 실제 교육 효과가 있다는 점을 확인할 수 있으며, 분석 설계 시 우려했던 ‘학습 의지’에 따른 선택편의 문제가 크지 않다는 것도 확인할 수 있었다(참고로 이 자료에서 0.467(혹은 0.478)의 의미는 해당 학교가 위치한 주(state)의 전체 수학 평균 점수에 비해 KIPP 재학생의 수학 점수가 평균적으로 0.467*표준편차 만큼 높다는 것을 의미한다).
요약했기 때문에 비교적 단순해 보이는 분석은 설계 단계에서 다음과 같은 가정들을 두었다.
첫째, 도구변수인 ‘추첨 정보’는 타 변수들과 상관관계가 없어야 한다. 즉, 추첨 결과가 학생의 가정환경이나 부모의 재정적 상황과는 독립적이어야 한다.
둘째, 도구변수인 ‘추첨 정보’는 성과변수인 교육 성과에 변화를 주는 유일한 통로여야 한다. 즉, 추첨에 따른 교육 성과에 대한 영향(당첨자와 당락자의 성과 점수 차이)은 순전히 추첨을 통한 합격으로 인한 결과라는 것이다.
위 분석에서 도구변수는 KIPP의 교육 성과에 대한 효과분석에서 동일한 조건의 학생들의 비교가 이루어지기 어렵다는 일부 사람들의 우려를 해소했고 보다 정밀한 비교를 통해 KIPP의 교육효과가 고무적이라는 것을 확인 가능하도록 했다. 하지만 여기서 도구변수로 사용된 ‘추첨 정보’는 해당 도시에서 학교에 지원자가 입학 정원보다 많을 경우 추첨을 도입하여 지원자격을 부여한다는 도메인 지식이 없이는 찾아낼 수 없는 변수이며 위 가정을 만족하지 않는다면 분석에 적절하지 않은 변수다. 무작위로 행해지는 변수의 필요를 파악한 분석가와 KIPP제도의 전반을 이해하고 있는 도메인 전문가가 함께 협력해야만 추첨 정보와 같은 도구변수가 발굴 가능하고 나아가 KIPP의 효과와 같은 고무적인 분석 결과를 찾아내는 것이 가능한 것이다.
사례2. 첫째 딜레마(양과 질의 상충관계)

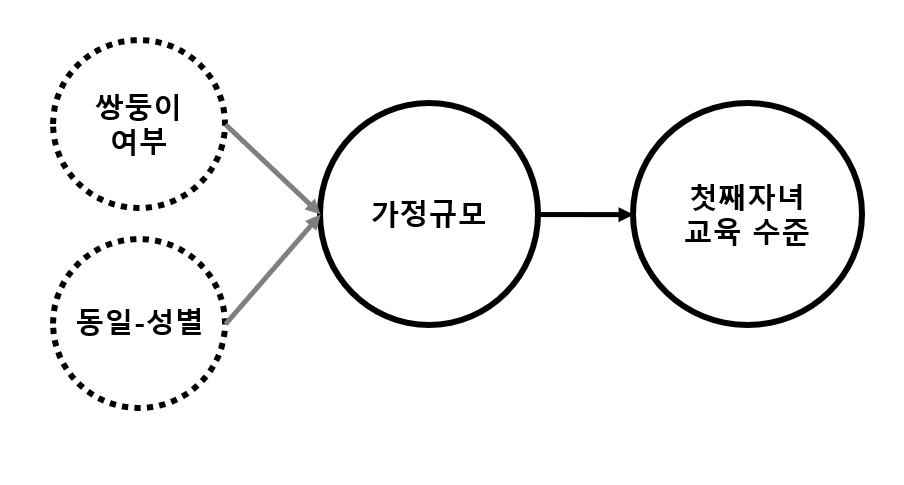
이번 사례는 사례1과 달리 두 가지의 도구변수를 활용한 경우이다. 가정 규모가 커짐에 따라 첫째에게 돌아가는 교육 수준이 낮아질 것인가에 대한 분석으로 ‘양과 질의 상충관계’ 개념의 분석이 되겠다. 여기서 첫째 자녀의 교육 수준과 가정 규모는 어떤 인과적 관련성이 존재할까. 부모의 차이에 따라 두 변수가 연관성이 있는데 예를 들어, 대가족일수록 부모의 교육 수준이 낮고 부모의 교육 수준이 낮으면 자녀의 교육 수준 또한 낮은 편이다. 그렇기 때문에 단순 비교를 할 경우 부모의 교육 수준이라는 특성에 따른 선택편의가 제거되지 않아 정확한 결과를 도출할 수 없다. 이를 해결하기 위해 교육 수준과 상관없고 가정 규모와 인과관계가 있으면서 무작위적 성질을 가진 도구변수가 필요하게 된다. 그래서 선택된 도구변수가 ‘두번째로 태어나는 자녀가 쌍둥이인지에 대한 정보’와 ‘첫째와 둘째사이의 성별의 동일 여부’이다. 쌍둥이로 태어나는 것과 태어나는 아이의 성별이 결정되는 것은 무작위에 가깝고 쌍둥이 여부는 가정 규모를 늘리는(+2명) 방식으로, 동일 성별 여부는 자녀의 성별이 다양하길 바라는 부모의 원함에 따른 가정 규모의 증가로 인과관계를 가진다.
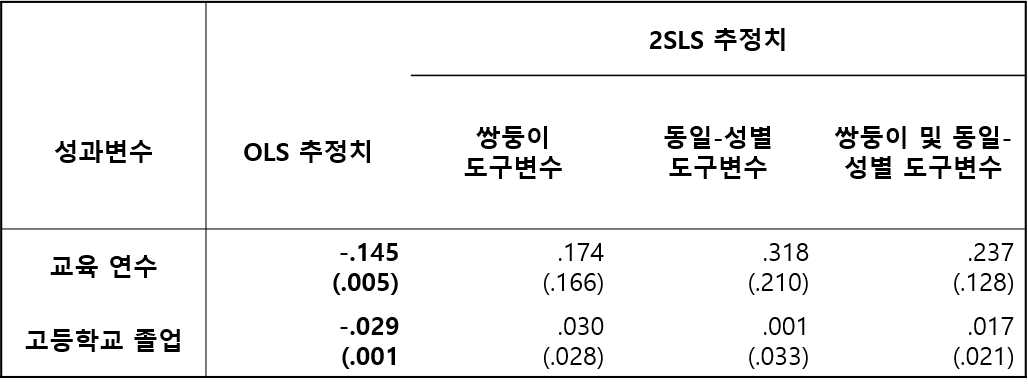
이러한 설계를 통해 분석을 수행한 결과, 도구변수를 사용하지 않은 경우(표1의 OLS 추정치) 자녀의 수가 많을수록 교육의 질이 떨어지는, 즉, 양과 질의 상충관계가 합당해 보이는 결과가 도출된 반면에 도구변수를 사용하여 선택편의를 제거(표1의 2SLS 추정치)한 모델에서 그 상충관계의 유의미성이 사라지는 결과가 도출되었다. 이는 다시 말해 OLS에서 얻은 추정량 결과는 선택편의에 영향을 받았음을 의미한다.
위 사례에서 쌍둥이 여부라는 도구변수는 쌍둥이가 가정규모 증가를 유도하는데 중요한 변수라는 마크 로젠쯔바이크(Mark Rosenzweig)와 케내스 울핀(Kenneth Wolpin)의 선구적인 연구결과를 통해 도출하였다. 그리고 자녀의 동일 성별 변수는 자녀의 성별이 섞이길 바라는 부모의 선호를 파악한 도메인 아이디어에서 나온 것이다. 즉, 여기서도 분석 결과의 선택편의를 완전히 제거하는데 효과적인 도구변수들은 분석가와 도메인 전문가의 고민과 탐구가 합쳐져 발굴된 것이다.
현실로 돌아와서
그렇다면 우리가 접하는 분석에서 위 두 사례와 같이 모든 가정을 만족하면서 효과적인 도구변수를 얼마나 만나볼 수 있을까? 분석에 적절한 도구변수를 만나기 전까지 우리는 다수의 약한 도구변수(처치변수와의 상관성이 약하고 선택편의를 효과적으로 제거하지 못하는 도구변수)를 더욱 많이 접하게 될 것이다. 적합한 변수를 찾는 과정이 어려운 만큼 유의미할 수 있는 변수를 눈 앞에서 놓치지 않도록 두 가지의 검토를 하는 것이 좋을 것 같다.
첫째, OLS와 2SLS의 분석 결과가 유사하게 나오는지 확인한다. 이는 도구변수가 처치변수의 선택편의를 제대로 제거하는 변수로 작용했는지 확인해보기 위해서이다..
둘째, 유한 표본 편의가 작용하지 않았는지 확인한다. 즉, 일부 도구변수가 약하게 나타날 수밖에 없는 표본만 고려한 것이 아닌지 확인하는 작업이 필요하다. 처치변수와 도구변수의 상관관계를 확인할 때 F 통계량이 최소 10(통념적 수치)을 넘으면 유한 표본 편의가 작용하지 않은 것으로 설명 가능하다.
인과추론 분석에 막 입문한 필자의 입장에서 데이터가 손에 쥐어지는 순간들을 돌아보면 빠르게 결과를 확인하고 싶은 마음이 더 앞선 탓에 변수 간의 관계 추론 및 데이터의 이해 과정을 과소평가해온 경향이 있다. 위에서 다룬 두 가지 분석 사례를 살펴보면 분석을 시행하기 전 모델 설계 단계에서 데이터 이해 과정이 얼마나 중요한지를 알 수 있다. 분석 기술과 도메인 지식 중 어느 한 쪽의 손을 들 수 없을 만큼 분석, 특히 인과추론 분석에서는 두 전문성의 조화가 필수적이며 과거의 의미있는 분석들이 많은 전문가의 협력 아래에 도출되었음을 상기하게 된다.
참고 자료
Jorn-steffen Pischke, Joshua D. Angrist (2014), 고수들의 계량경제학, 시그마프레스